 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeERASER: A Benchmark to Evaluate Rationalized NLP Models
Paper and Code

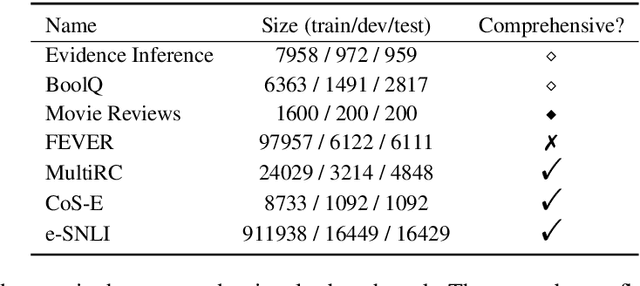
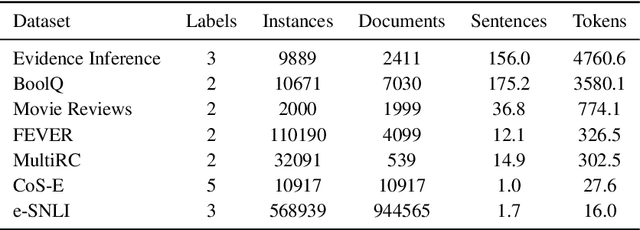
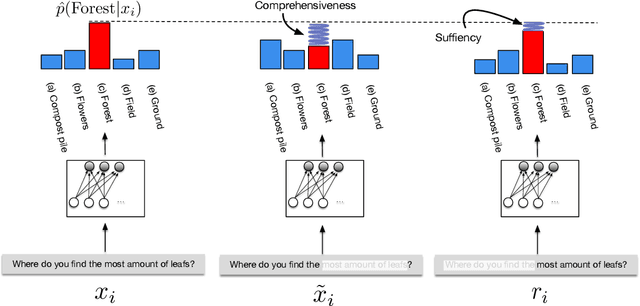
State-of-the-art models in NLP are now predominantly based on deep neural networks that are generally opaque in terms of how they come to specific predictions. This limitation has led to increased interest in designing more interpretable deep models for NLP that can reveal the `reasoning' underlying model outputs. But work in this direction has been conducted on different datasets and tasks with correspondingly unique aims and metrics; this makes it difficult to track progress. We propose the Evaluating Rationales And Simple English Reasoning (ERASER) benchmark to advance research on interpretable models in NLP. This benchmark comprises multiple datasets and tasks for which human annotations of "rationales" (supporting evidence) have been collected. We propose several metrics that aim to capture how well the rationales provided by models align with human rationales, and also how faithful these rationales are (i.e., the degree to which provided rationales influenced the corresponding predictions). Our hope is that releasing this benchmark facilitates progress on designing more interpretable NLP systems. The benchmark, code, and documentation are available at: www.eraserbenchmark.com .