 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmotionNAS: Two-stream Architecture Search for Speech Emotion Recognition
Paper and Code
Mar 25, 2022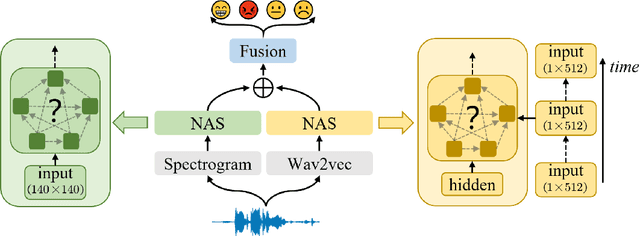
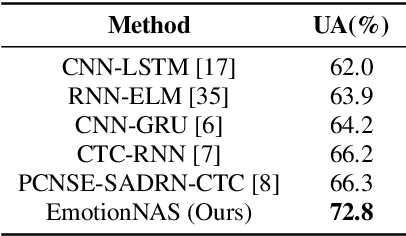
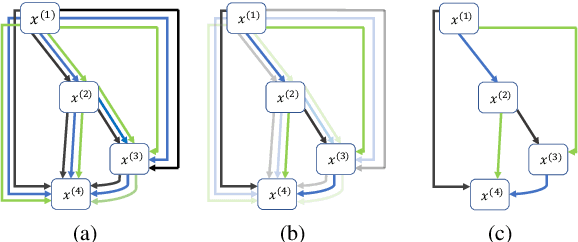
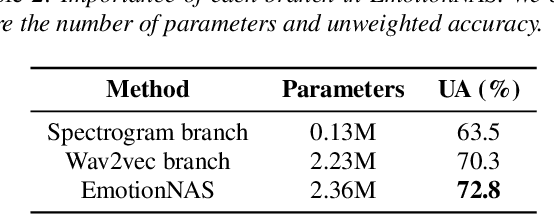
Speech emotion recognition (SER) is a crucial research topic in human-computer interactions. Existing works are mainly based on manually designed models. Despite their great success, these methods heavily rely on historical experience, which are time-consuming but cannot exhaust all possible structures. To address this problem, we propose a neural architecture search (NAS) based framework for SER, called "EmotionNAS". We take spectrogram and wav2vec features as the inputs, followed with NAS to optimize the network structure for these features separately. We further incorporate complementary information in these features through decision-level fusion. Experimental results on IEMOCAP demonstrate that our method succeeds over existing state-of-the-art strategies on SER.