 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiverse Image Inpainting with Bidirectional and Autoregressive Transformers
Paper and Code
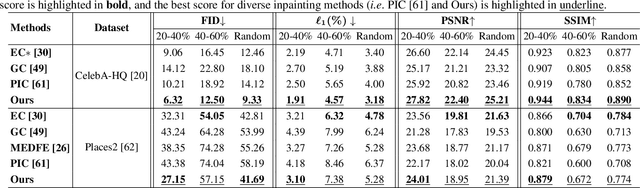
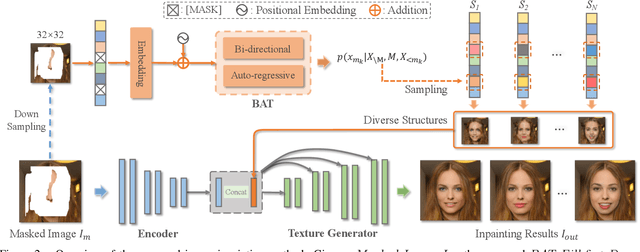
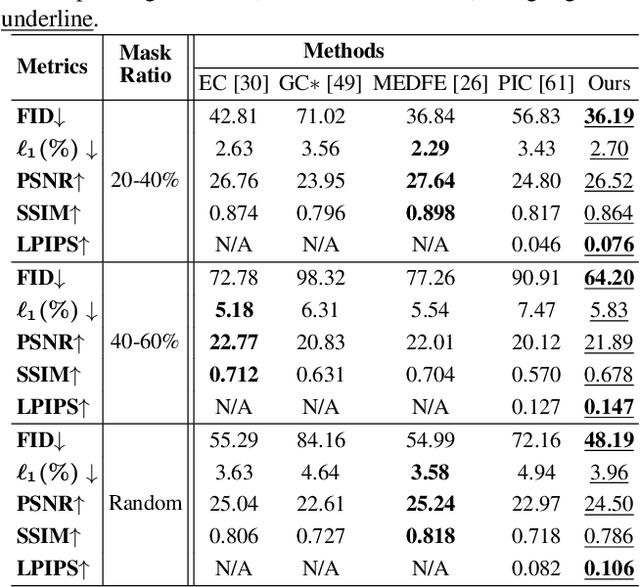
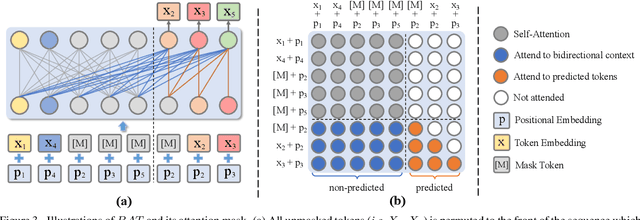
Image inpainting is an underdetermined inverse problem, it naturally allows diverse contents that fill up the missing or corrupted regions reasonably and realistically. Prevalent approaches using convolutional neural networks (CNNs) can synthesize visually pleasant contents, but CNNs suffer from limited perception fields for capturing global features. With image-level attention, transformers enable to model long-range dependencies and generate diverse contents with autoregressive modeling of pixel-sequence distributions. However, the unidirectional attention in transformers is suboptimal as corrupted regions can have arbitrary shapes with contexts from arbitrary directions. We propose BAT-Fill, an image inpainting framework with a novel bidirectional autoregressive transformer (BAT) that models deep bidirectional contexts for autoregressive generation of diverse inpainting contents. BAT-Fill inherits the merits of transformers and CNNs in a two-stage manner, which allows to generate high-resolution contents without being constrained by the quadratic complexity of attention in transformers. Specifically, it first generates pluralistic image structures of low resolution by adapting transformers and then synthesizes realistic texture details of high resolutions with a CNN-based up-sampling network. Extensive experiments over multiple datasets show that BAT-Fill achieves superior diversity and fidelity in image inpainting qualitatively and quantitatively.