 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiscovering Drug-Target Interaction Knowledge from Biomedical Literature
Paper and Code


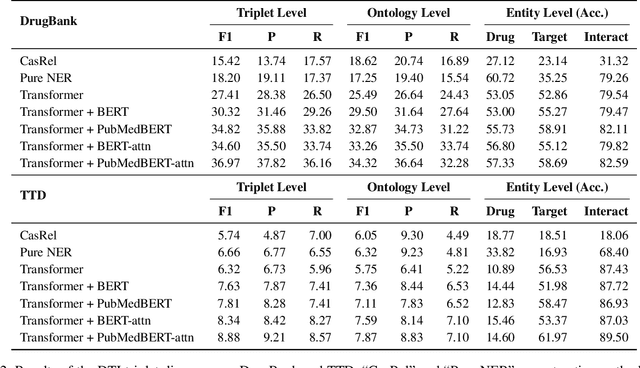
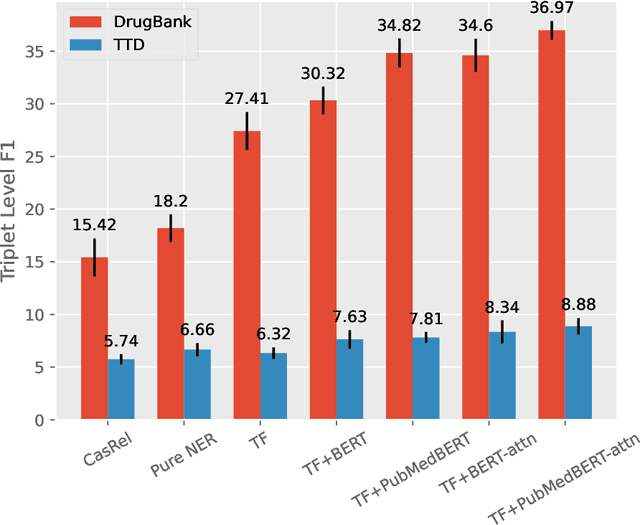
The Interaction between Drugs and Targets (DTI) in human body plays a crucial role in biomedical science and applications. As millions of papers come out every year in the biomedical domain, automatically discovering DTI knowledge from biomedical literature, which are usually triplets about drugs, targets and their interaction, becomes an urgent demand in the industry. Existing methods of discovering biological knowledge are mainly extractive approaches that often require detailed annotations (e.g., all mentions of biological entities, relations between every two entity mentions, etc.). However, it is difficult and costly to obtain sufficient annotations due to the requirement of expert knowledge from biomedical domains. To overcome these difficulties, we explore the first end-to-end solution for this task by using generative approaches. We regard the DTI triplets as a sequence and use a Transformer-based model to directly generate them without using the detailed annotations of entities and relations. Further, we propose a semi-supervised method, which leverages the aforementioned end-to-end model to filter unlabeled literature and label them. Experimental results show that our method significantly outperforms extractive baselines on DTI discovery. We also create a dataset, KD-DTI, to advance this task and will release it to the community.