 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDense Connector for MLLMs
Paper and Code
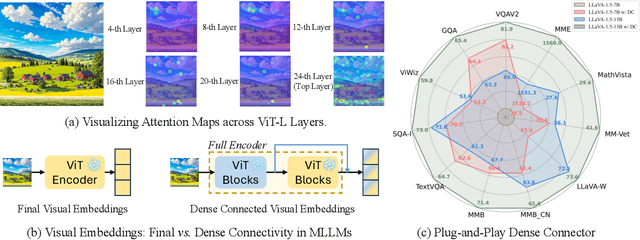
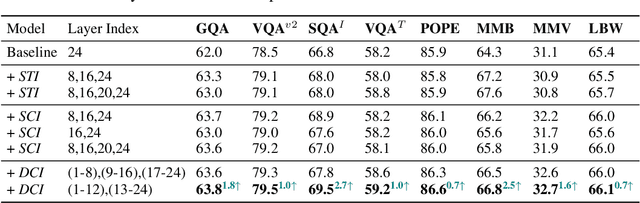
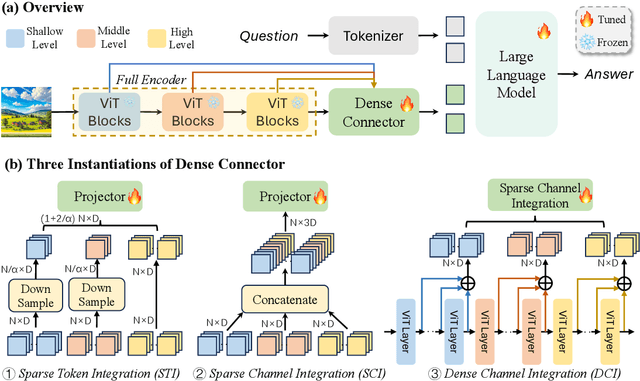
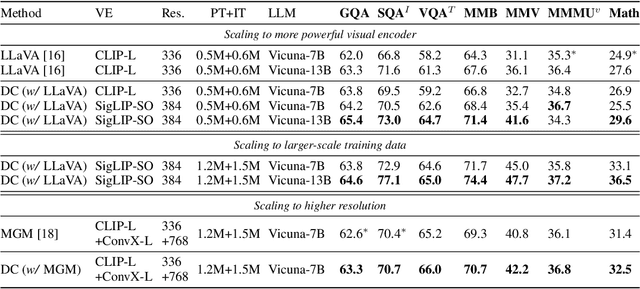
Do we fully leverage the potential of visual encoder in Multimodal Large Language Models (MLLMs)? The recent outstanding performance of MLLMs in multimodal understanding has garnered broad attention from both academia and industry. In the current MLLM rat race, the focus seems to be predominantly on the linguistic side. We witness the rise of larger and higher-quality instruction datasets, as well as the involvement of larger-sized LLMs. Yet, scant attention has been directed towards the visual signals utilized by MLLMs, often assumed to be the final high-level features extracted by a frozen visual encoder. In this paper, we introduce the Dense Connector - a simple, effective, and plug-and-play vision-language connector that significantly enhances existing MLLMs by leveraging multi-layer visual features, with minimal additional computational overhead. Furthermore, our model, trained solely on images, showcases remarkable zero-shot capabilities in video understanding as well. Experimental results across various vision encoders, image resolutions, training dataset scales, varying sizes of LLMs (2.7B->70B), and diverse architectures of MLLMs (e.g., LLaVA and Mini-Gemini) validate the versatility and scalability of our approach, achieving state-of-the-art performance on across 19 image and video benchmarks. We hope that this work will provide valuable experience and serve as a basic module for future MLLM development.