Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContextual Similarity is More Valuable than Character Similarity: Curriculum Learning for Chinese Spell Checking
Paper and Code
Jul 17, 2022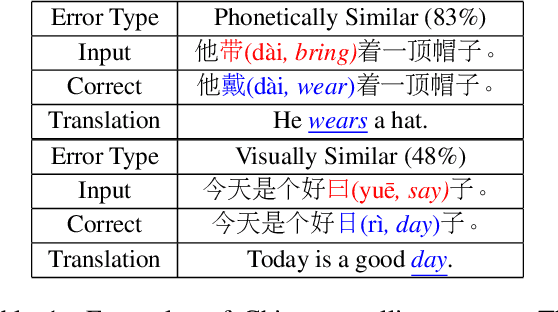
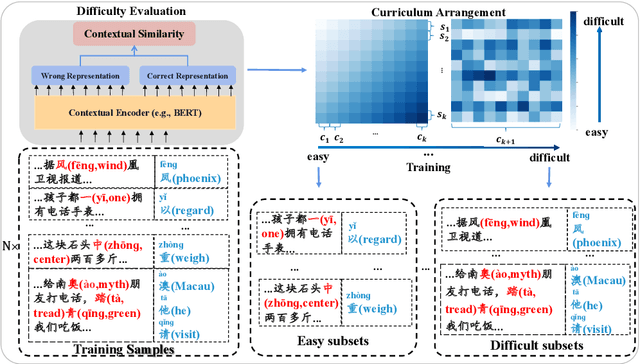
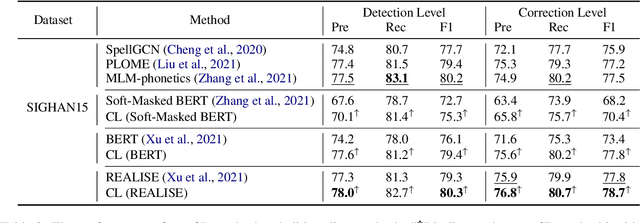
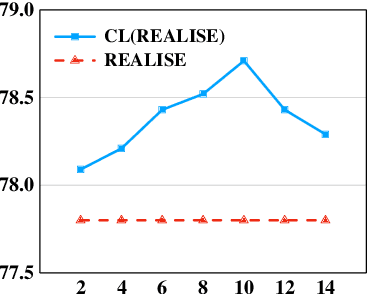
Chinese Spell Checking (CSC) task aims to detect and correct Chinese spelling errors. In recent years, related researches focus on introducing the character similarity from confusion set to enhance the CSC models, ignoring the context of characters that contain richer information. To make better use of contextual similarity, we propose a simple yet effective curriculum learning framework for the CSC task. With the help of our designed model-agnostic framework, existing CSC models will be trained from easy to difficult as humans learn Chinese characters and achieve further performance improvements. Extensive experiments and detailed analyses on widely used SIGHAN datasets show that our method outperforms previous state-of-the-art methods.
View paper on