 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCEMFormer: Learning to Predict Driver Intentions from In-Cabin and External Cameras via Spatial-Temporal Transformers
Paper and Code
May 13, 2023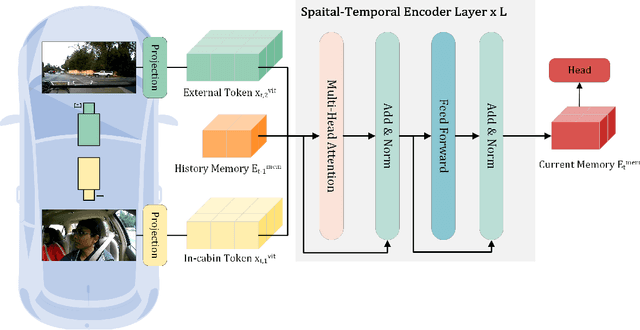
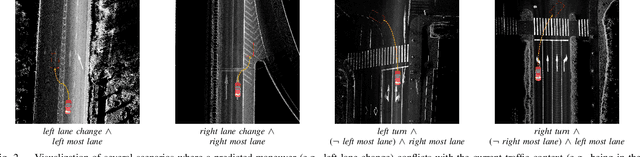
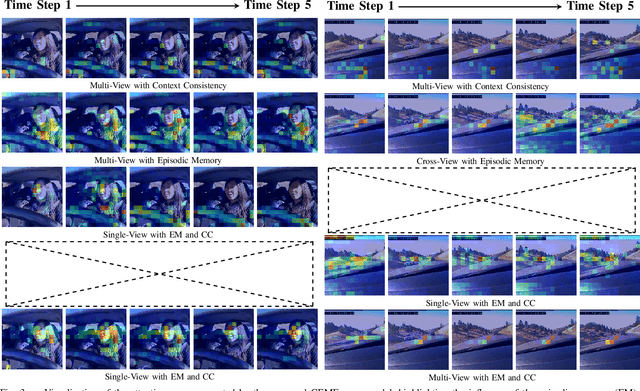
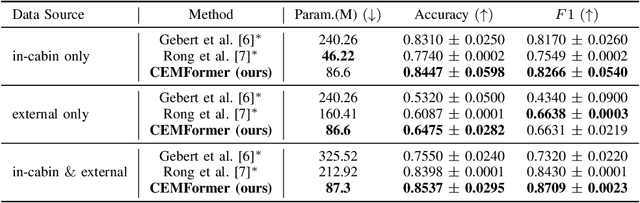
Driver intention prediction seeks to anticipate drivers' actions by analyzing their behaviors with respect to surrounding traffic environments. Existing approaches primarily focus on late-fusion techniques, and neglect the importance of maintaining consistency between predictions and prevailing driving contexts. In this paper, we introduce a new framework called Cross-View Episodic Memory Transformer (CEMFormer), which employs spatio-temporal transformers to learn unified memory representations for an improved driver intention prediction. Specifically, we develop a spatial-temporal encoder to integrate information from both in-cabin and external camera views, along with episodic memory representations to continuously fuse historical data. Furthermore, we propose a novel context-consistency loss that incorporates driving context as an auxiliary supervision signal to improve prediction performance. Comprehensive experiments on the Brain4Cars dataset demonstrate that CEMFormer consistently outperforms existing state-of-the-art methods in driver intention prediction.