 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBioT5+: Towards Generalized Biological Understanding with IUPAC Integration and Multi-task Tuning
Paper and Code
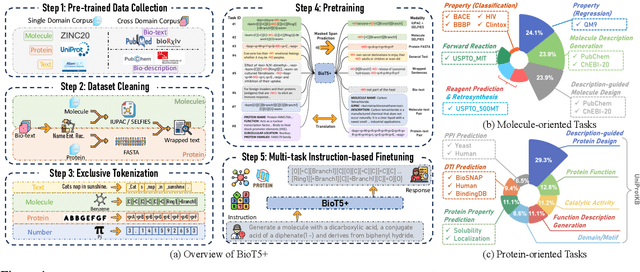
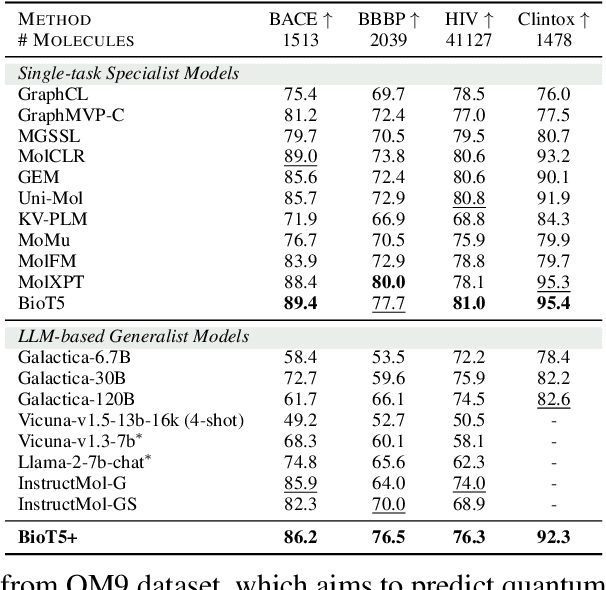
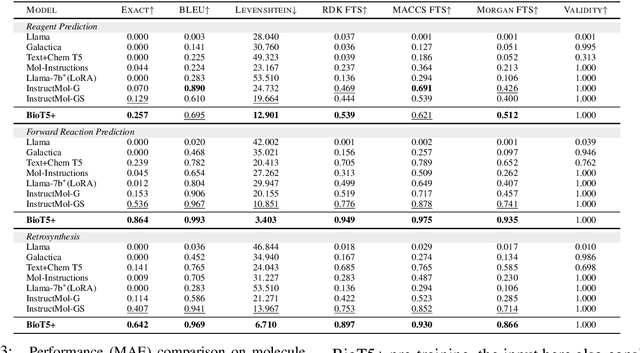
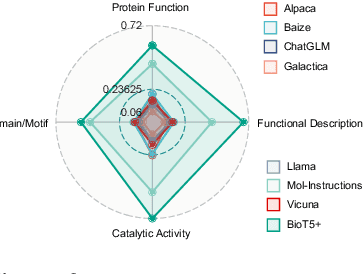
Recent research trends in computational biology have increasingly focused on integrating text and bio-entity modeling, especially in the context of molecules and proteins. However, previous efforts like BioT5 faced challenges in generalizing across diverse tasks and lacked a nuanced understanding of molecular structures, particularly in their textual representations (e.g., IUPAC). This paper introduces BioT5+, an extension of the BioT5 framework, tailored to enhance biological research and drug discovery. BioT5+ incorporates several novel features: integration of IUPAC names for molecular understanding, inclusion of extensive bio-text and molecule data from sources like bioRxiv and PubChem, the multi-task instruction tuning for generality across tasks, and a novel numerical tokenization technique for improved processing of numerical data. These enhancements allow BioT5+ to bridge the gap between molecular representations and their textual descriptions, providing a more holistic understanding of biological entities, and largely improving the grounded reasoning of bio-text and bio-sequences. The model is pre-trained and fine-tuned with a large number of experiments, including \emph{3 types of problems (classification, regression, generation), 15 kinds of tasks, and 21 total benchmark datasets}, demonstrating the remarkable performance and state-of-the-art results in most cases. BioT5+ stands out for its ability to capture intricate relationships in biological data, thereby contributing significantly to bioinformatics and computational biology. Our code is available at \url{https://github.com/QizhiPei/BioT5}.