 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edgebert2BERT: Towards Reusable Pretrained Language Models
Paper and Code
Oct 14, 2021


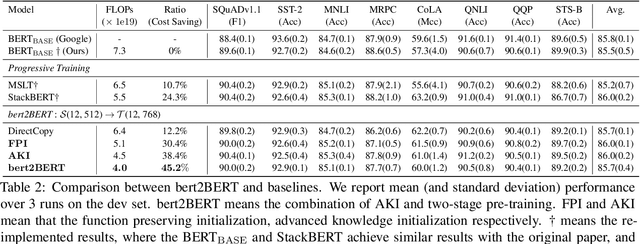
In recent years, researchers tend to pre-train ever-larger language models to explore the upper limit of deep models. However, large language model pre-training costs intensive computational resources and most of the models are trained from scratch without reusing the existing pre-trained models, which is wasteful. In this paper, we propose bert2BERT, which can effectively transfer the knowledge of an existing smaller pre-trained model (e.g., BERT_BASE) to a large model (e.g., BERT_LARGE) through parameter initialization and significantly improve the pre-training efficiency of the large model. Specifically, we extend the previous function-preserving on Transformer-based language model, and further improve it by proposing advanced knowledge for large model's initialization. In addition, a two-stage pre-training method is proposed to further accelerate the training process. We did extensive experiments on representative PLMs (e.g., BERT and GPT) and demonstrate that (1) our method can save a significant amount of training cost compared with baselines including learning from scratch, StackBERT and MSLT; (2) our method is generic and applicable to different types of pre-trained models. In particular, bert2BERT saves about 45% and 47% computational cost of pre-training BERT_BASE and GPT_BASE by reusing the models of almost their half sizes. The source code will be publicly available upon publication.