 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAligning the Capabilities of Large Language Models with the Context of Information Retrieval via Contrastive Feedback
Paper and Code
Sep 29, 2023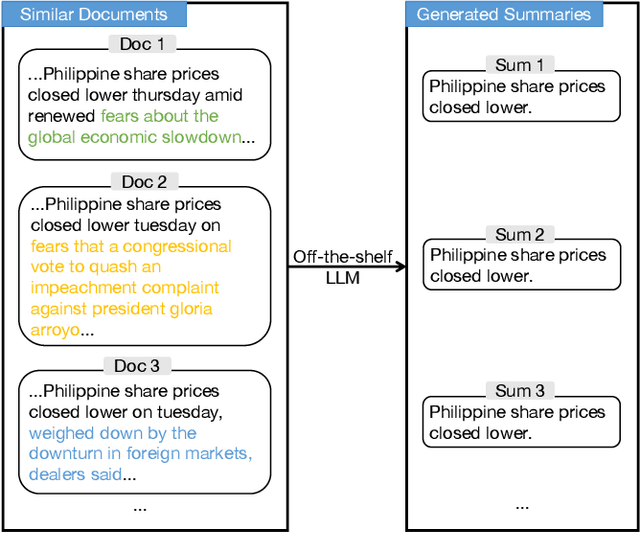

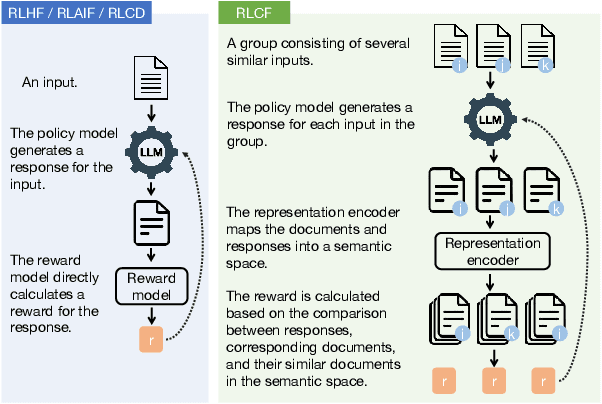
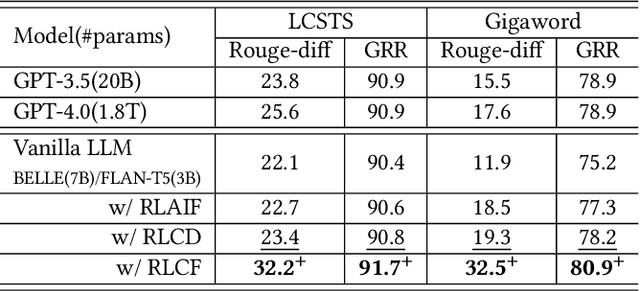
Information Retrieval (IR), the process of finding information to satisfy user's information needs, plays an essential role in modern people's lives. Recently, large language models (LLMs) have demonstrated remarkable capabilities across various tasks, some of which are important for IR. Nonetheless, LLMs frequently confront the issue of generating responses that lack specificity. This has limited the overall effectiveness of LLMs for IR in many cases. To address these issues, we present an unsupervised alignment framework called Reinforcement Learning from Contrastive Feedback (RLCF), which empowers LLMs to generate both high-quality and context-specific responses that suit the needs of IR tasks. Specifically, we construct contrastive feedback by comparing each document with its similar documents, and then propose a reward function named Batched-MRR to teach LLMs to generate responses that captures the fine-grained information that distinguish documents from their similar ones. To demonstrate the effectiveness of RLCF, we conducted experiments in two typical applications of LLMs in IR, i.e., data augmentation and summarization. The experimental results show that RLCF can effectively improve the performance of LLMs in IR context.