 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Text-guided Protein Design Framework
Paper and Code
Feb 09, 2023

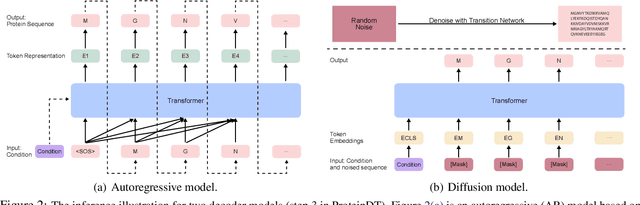

Current AI-assisted protein design mainly utilizes protein sequential and structural information. Meanwhile, there exists tremendous knowledge curated by humans in the text format describing proteins' high-level properties. Yet, whether the incorporation of such text data can help protein design tasks has not been explored. To bridge this gap, we propose ProteinDT, a multi-modal framework that leverages textual descriptions for protein design. ProteinDT consists of three subsequent steps: ProteinCLAP that aligns the representation of two modalities, a facilitator that generates the protein representation from the text modality, and a decoder that generates the protein sequences from the representation. To train ProteinDT, we construct a large dataset, SwissProtCLAP, with 441K text and protein pairs. We empirically verify the effectiveness of ProteinDT from three aspects: (1) consistently superior performance on four out of six protein property prediction benchmarks; (2) over 90% accuracy for text-guided protein generation; and (3) promising results for zero-shot text-guided protein editing.