 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInference of hidden common driver dynamics by anisotropic self-organizing neural networks
Apr 02, 2025We are introducing a novel approach to infer the underlying dynamics of hidden common drivers, based on analyzing time series data from two driven dynamical systems. The inference relies on time-delay embedding, estimation of the intrinsic dimension of the observed systems, and their mutual dimension. A key component of our approach is a new anisotropic training technique applied to Kohonen's self-organizing map, which effectively learns the attractor of the driven system and separates it into submanifolds corresponding to the self-dynamics and shared dynamics. To demonstrate the effectiveness of our method, we conducted simulated experiments using different chaotic maps in a setup, where two chaotic maps were driven by a third map with nonlinear coupling. The inferred time series exhibited high correlation with the time series of the actual hidden common driver, in contrast to the observed systems. The quality of our reconstruction were compared and shown to be superior to several other methods that are intended to find the common features behind the observed time series, including linear methods like PCA and ICA as well as nonlinear methods like dynamical component analysis, canonical correlation analysis and even deep canonical correlation analysis.
Detecting Causality in the Frequency Domain with Cross-Mapping Coherence
Jul 30, 2024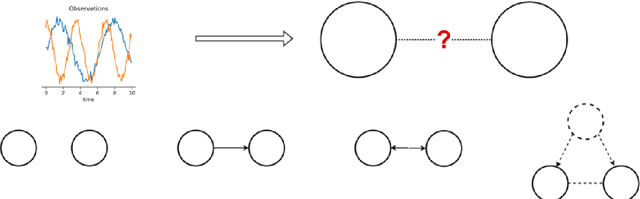
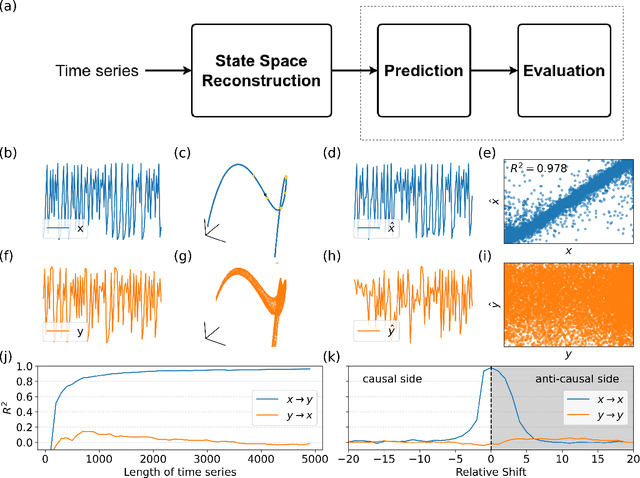

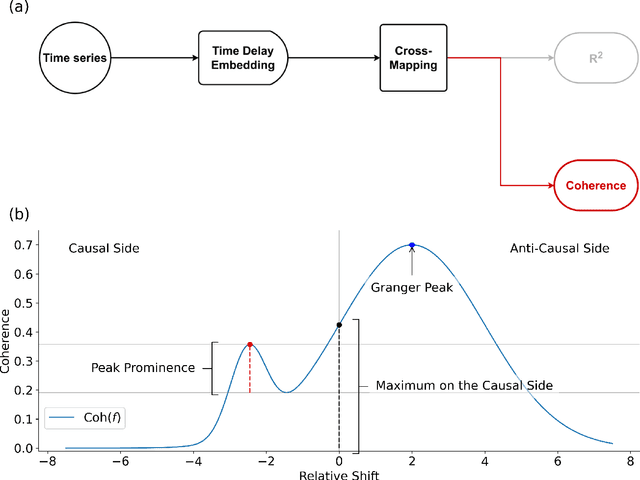
Understanding causal relationships within a system is crucial for uncovering its underlying mechanisms. Causal discovery methods, which facilitate the construction of such models from time-series data, hold the potential to significantly advance scientific and engineering fields. This study introduces the Cross-Mapping Coherence (CMC) method, designed to reveal causal connections in the frequency domain between time series. CMC builds upon nonlinear state-space reconstruction and extends the Convergent Cross-Mapping algorithm to the frequency domain by utilizing coherence metrics for evaluation. We tested the Cross-Mapping Coherence method using simulations of logistic maps, Lorenz systems, Kuramoto oscillators, and the Wilson-Cowan model of the visual cortex. CMC accurately identified the direction of causal connections in all simulated scenarios. When applied to the Wilson-Cowan model, CMC yielded consistent results similar to spectral Granger causality. Furthermore, CMC exhibits high sensitivity in detecting weak connections, demonstrates sample efficiency, and maintains robustness in the presence of noise. In conclusion, the capability to determine directed causal influences across different frequency bands allows CMC to provide valuable insights into the dynamics of complex, nonlinear systems.
Feature space reduction method for ultrahigh-dimensional, multiclass data: Random forest-based multiround screening (RFMS)
May 25, 2023In recent years, numerous screening methods have been published for ultrahigh-dimensional data that contain hundreds of thousands of features; however, most of these features cannot handle data with thousands of classes. Prediction models built to authenticate users based on multichannel biometric data result in this type of problem. In this study, we present a novel method known as random forest-based multiround screening (RFMS) that can be effectively applied under such circumstances. The proposed algorithm divides the feature space into small subsets and executes a series of partial model builds. These partial models are used to implement tournament-based sorting and the selection of features based on their importance. To benchmark RFMS, a synthetic biometric feature space generator known as BiometricBlender is employed. Based on the results, the RFMS is on par with industry-standard feature screening methods while simultaneously possessing many advantages over these methods.
BiometricBlender: Ultra-high dimensional, multi-class synthetic data generator to imitate biometric feature space
Jun 21, 2022
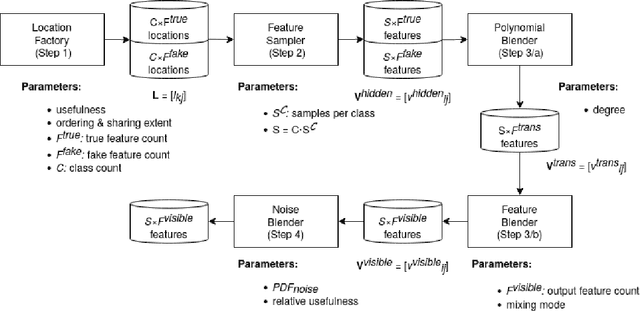


The lack of freely available (real-life or synthetic) high or ultra-high dimensional, multi-class datasets may hamper the rapidly growing research on feature screening, especially in the field of biometrics, where the usage of such datasets is common. This paper reports a Python package called BiometricBlender, which is an ultra-high dimensional, multi-class synthetic data generator to benchmark a wide range of feature screening methods. During the data generation process, the overall usefulness and the intercorrelations of blended features can be controlled by the user, thus the synthetic feature space is able to imitate the key properties of a real biometric dataset.
Reconstructing common latent input from time series with the mapper-coach network and error backpropagation
May 05, 2021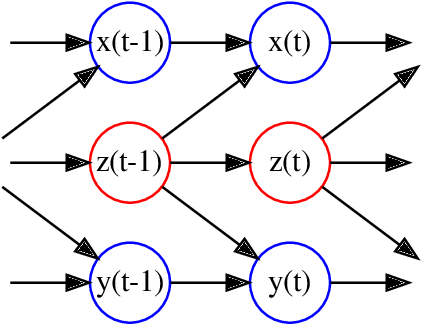
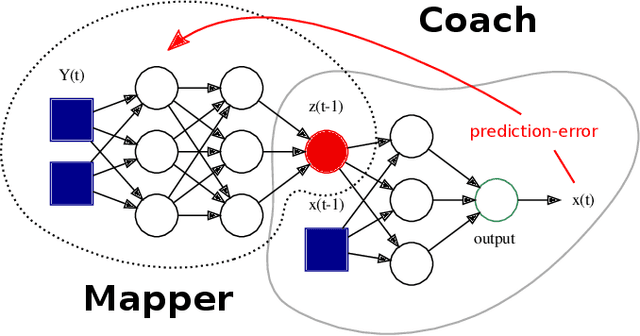
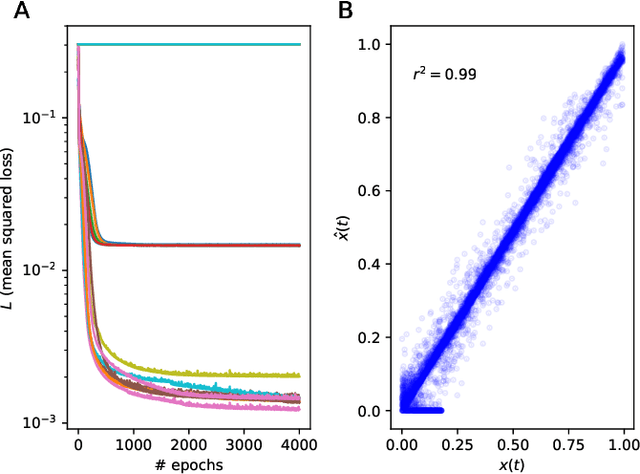
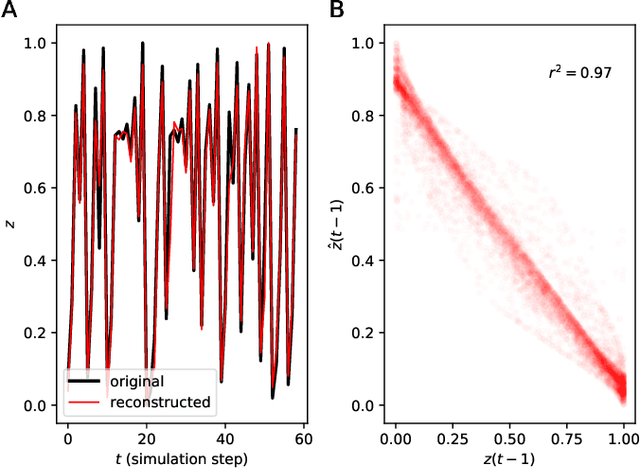
A two-module, feedforward neural network architecture called mapper-coach network has been introduced to reconstruct an unobserved, continuous latent variable input, driving two observed dynamical systems. The method has been demonstrated on time series generated by two chaotic logistic maps driven by a hidden third one. The network has been trained to predict one of the observed time series based on its own past and on the other observed time series by error-back propagation. It was shown, that after this prediction have been learned successfully, the activity of the bottleneck neuron, connecting the mapper and the coach module, correlates strongly with the latent common input variable. The method has the potential to reveal hidden components of dynamical systems, where experimental intervention is not possible.
Manifold-adaptive dimension estimation revisited
Aug 10, 2020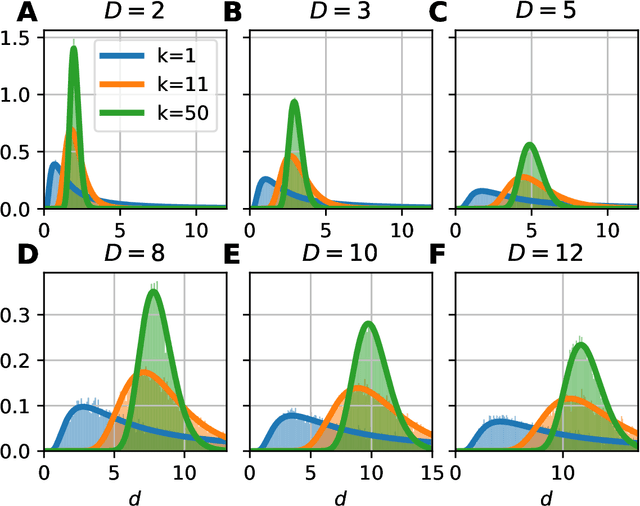
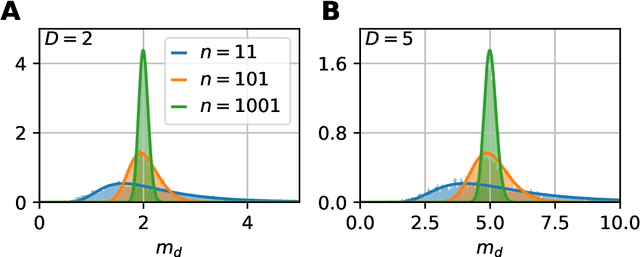
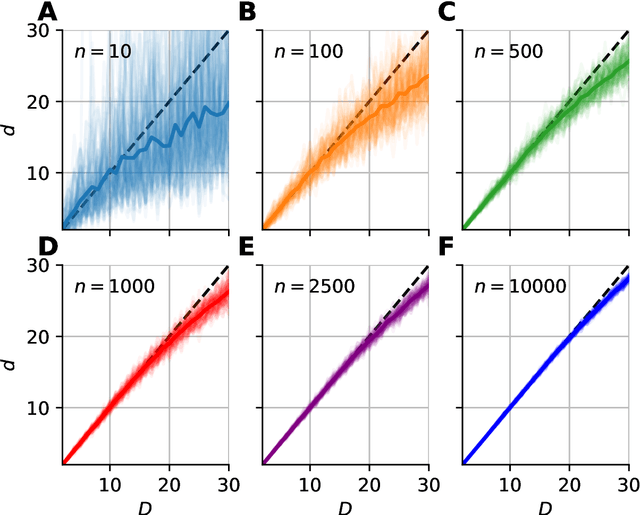

Data dimensionality informs us about data complexity and sets limit on the structure of successful signal processing pipelines. In this work we revisit and improve the manifold-adaptive Farahmand-Szepesv\'ari-Audibert (FSA) dimension estimator, making it one of the best nearest neighbor-based dimension estimators available. We compute the probability density function of local FSA estimates, if the local manifold density is uniform. Based on the probability density function, we propose to use the median of local estimates as a basic global measure of intrinsic dimensionality, and we demonstrate the advantages of this asymptotically unbiased estimator over the previously proposed statistics: the mode and the mean. Additionally, from the probability density function, we derive the maximum likelihood formula for global intrinsic dimensionality, if i.i.d. holds. We tackle edge and finite-sample effects with an exponential correction formula, calibrated on hypercube datasets. We compare the performance of the corrected-median-FSA estimator with kNN estimators: maximum likelihood (ML, Levina-Bickel) and two implementations of DANCo (R and matlab). We show that corrected-median-FSA estimator beats the ML estimator and it is on equal footing with DANCo for standard synthetic benchmarks according to mean percentage error and error rate metrics. With the median-FSA algorithm, we reveal diverse changes in the neural dynamics while resting state and during epileptic seizures. We identify brain areas with lower-dimensional dynamics that are possible causal sources and candidates for being seizure onset zones.
How to find a unicorn: a novel model-free, unsupervised anomaly detection method for time series
May 05, 2020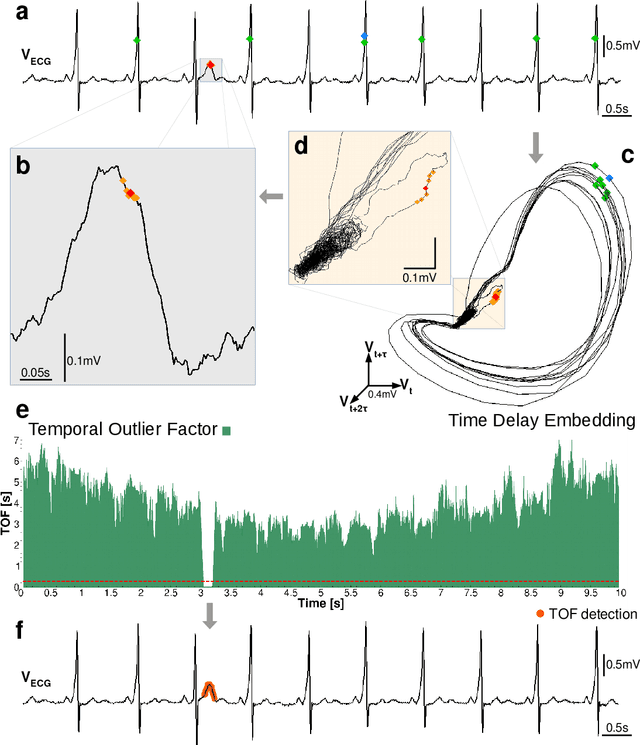
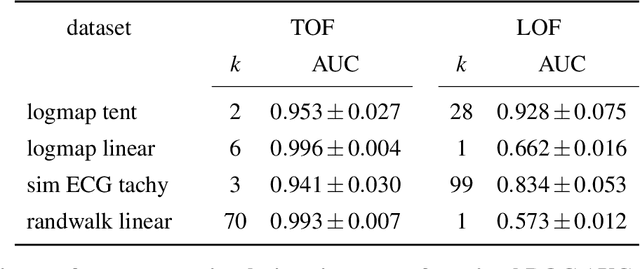

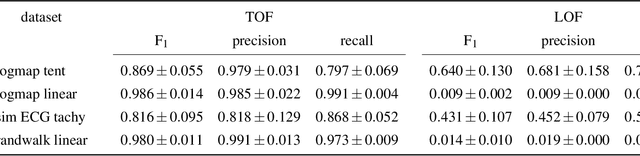
Recognition of anomalous events is a challenging but critical task in many scientific and industrial fields, especially when the properties of anomalies are unknown. In this paper, we present a new anomaly concept called "unicorn" or unique event and present a new, model-independent, unsupervised detection algorithm to detect unicorns. The Temporal Outlier Factor (TOF) is introduced to measure the uniqueness of events in continuous data sets from dynamic systems. The concept of unique events differs significantly from traditional outliers in many aspects: while repetitive outliers are no longer unique events, a unique event is not necessarily outlier in either pointwise or collective sense; it does not necessarily fall out from the distribution of normal activity. The performance of our algorithm was examined in recognizing unique events on different types of simulated data sets with anomalies and it was compared with the standard Local Outlier Factor (LOF). TOF had superior performance compared to LOF even in recognizing traditional outliers and it also recognized unique events that LOF did not. Benefits of the unicorn concept and the new detection method were illustrated by example data sets from very different scientific fields. Our algorithm successfully recognized unique events in those cases where they were already known such as the gravitational waves of a black hole merger on LIGO detector data and the signs of respiratory failure on ECG data series. Furthermore, unique events were found on the LIBOR data set of the last 30 years.