Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBiometricBlender: Ultra-high dimensional, multi-class synthetic data generator to imitate biometric feature space
Paper and Code
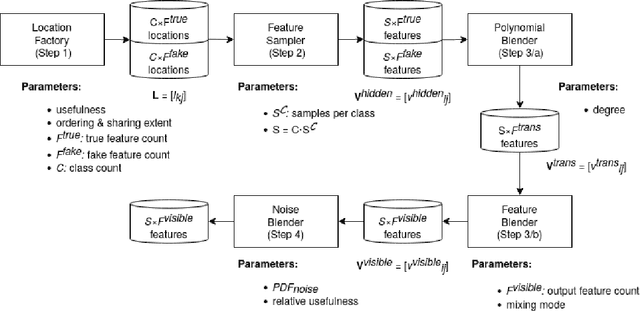


The lack of freely available (real-life or synthetic) high or ultra-high dimensional, multi-class datasets may hamper the rapidly growing research on feature screening, especially in the field of biometrics, where the usage of such datasets is common. This paper reports a Python package called BiometricBlender, which is an ultra-high dimensional, multi-class synthetic data generator to benchmark a wide range of feature screening methods. During the data generation process, the overall usefulness and the intercorrelations of blended features can be controlled by the user, thus the synthetic feature space is able to imitate the key properties of a real biometric dataset.
* 12 pages, 2 figures, 2 tables
View paper on