 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFeature space reduction method for ultrahigh-dimensional, multiclass data: Random forest-based multiround screening (RFMS)
May 25, 2023In recent years, numerous screening methods have been published for ultrahigh-dimensional data that contain hundreds of thousands of features; however, most of these features cannot handle data with thousands of classes. Prediction models built to authenticate users based on multichannel biometric data result in this type of problem. In this study, we present a novel method known as random forest-based multiround screening (RFMS) that can be effectively applied under such circumstances. The proposed algorithm divides the feature space into small subsets and executes a series of partial model builds. These partial models are used to implement tournament-based sorting and the selection of features based on their importance. To benchmark RFMS, a synthetic biometric feature space generator known as BiometricBlender is employed. Based on the results, the RFMS is on par with industry-standard feature screening methods while simultaneously possessing many advantages over these methods.
BiometricBlender: Ultra-high dimensional, multi-class synthetic data generator to imitate biometric feature space
Jun 21, 2022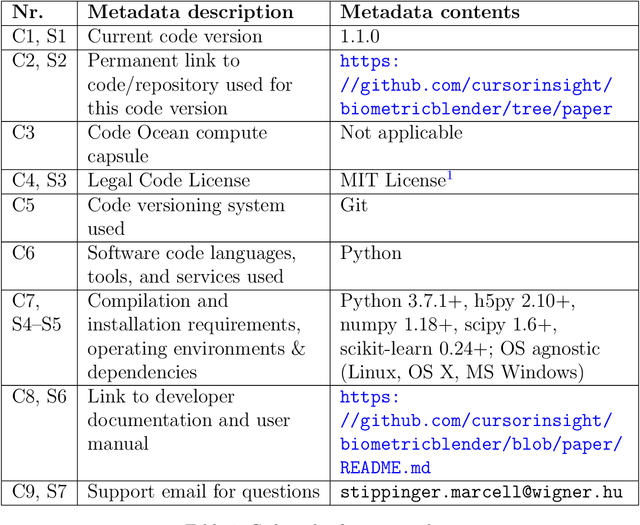
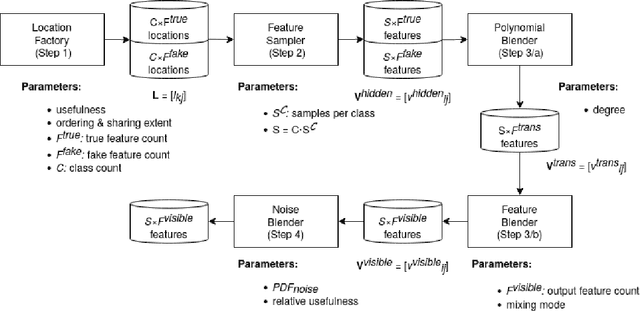


The lack of freely available (real-life or synthetic) high or ultra-high dimensional, multi-class datasets may hamper the rapidly growing research on feature screening, especially in the field of biometrics, where the usage of such datasets is common. This paper reports a Python package called BiometricBlender, which is an ultra-high dimensional, multi-class synthetic data generator to benchmark a wide range of feature screening methods. During the data generation process, the overall usefulness and the intercorrelations of blended features can be controlled by the user, thus the synthetic feature space is able to imitate the key properties of a real biometric dataset.