 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchical LLM-Driven Control for HAPS-Assisted UAV Networks: Joint Optimization of Flight and Connectivity
May 12, 2026Uncrewed aerial vehicles (UAVs) are increasingly deployed in complex networked environments, yet the joint optimization of multi-UAV motion control and connectivity remains a fundamental challenge. In this paper, we study a multi-UAV system operating in an integrated terrestrial and non-terrestrial network (ITNTN) comprising terrestrial base stations and high-altitude platform stations (HAPS). We consider a three-dimensional (3D) aerial highway scenario where UAVs must adapt their motion to ensure collision avoidance, efficient traffic flow, and reliable communication under dynamic and partially observable conditions. We first model the problem as a hierarchical multi-objective partially observable Markov decision process (H-MO-POMDP), capturing the coupling between control and communication objectives. Based on this formulation, we propose a large language model (LLM)-driven hierarchical multi-rate control framework. At the global level, an LLM-based controller on the HAPS performs long-term planning for load balancing and handover decisions. At the local level, each UAV employs a hybrid controller that integrates a slow-timescale LLM for high-level spatial reasoning with a reinforcement learning agent for faster UAV-to-infrastructure (U2I) communication and motion control. We further develop a high-fidelity 3D simulation platform by integrating the gym-pybullet-drones environment with 3GPP-compliant RF/THz channel models. Numerical results demonstrate that the proposed framework significantly outperforms state-of-the-art baselines, achieving a 14% increase in transportation efficiency and a 25% improvement in telecommunication throughput. Additionally, it achieves a 23% reduction in physical collision rates, demonstrating strong handover stability and zero-shot generalization in dynamic scenarios.
EMFusion: Conditional Diffusion Framework for Trustworthy Frequency Selective EMF Forecasting in Wireless Networks
Dec 17, 2025The rapid growth in wireless infrastructure has increased the need to accurately estimate and forecast electromagnetic field (EMF) levels to ensure ongoing compliance, assess potential health impacts, and support efficient network planning. While existing studies rely on univariate forecasting of wideband aggregate EMF data, frequency-selective multivariate forecasting is needed to capture the inter-operator and inter-frequency variations essential for proactive network planning. To this end, this paper introduces EMFusion, a conditional multivariate diffusion-based probabilistic forecasting framework that integrates diverse contextual factors (e.g., time of day, season, and holidays) while providing explicit uncertainty estimates. The proposed architecture features a residual U-Net backbone enhanced by a cross-attention mechanism that dynamically integrates external conditions to guide the generation process. Furthermore, EMFusion integrates an imputation-based sampling strategy that treats forecasting as a structural inpainting task, ensuring temporal coherence even with irregular measurements. Unlike standard point forecasters, EMFusion generates calibrated probabilistic prediction intervals directly from the learned conditional distribution, providing explicit uncertainty quantification essential for trustworthy decision-making. Numerical experiments conducted on frequency-selective EMF datasets demonstrate that EMFusion with the contextual information of working hours outperforms the baseline models with or without conditions. The EMFusion outperforms the best baseline by 23.85% in continuous ranked probability score (CRPS), 13.93% in normalized root mean square error, and reduces prediction CRPS error by 22.47%.
Hierarchical and Collaborative LLM-Based Control for Multi-UAV Motion and Communication in Integrated Terrestrial and Non-Terrestrial Networks
Jun 06, 2025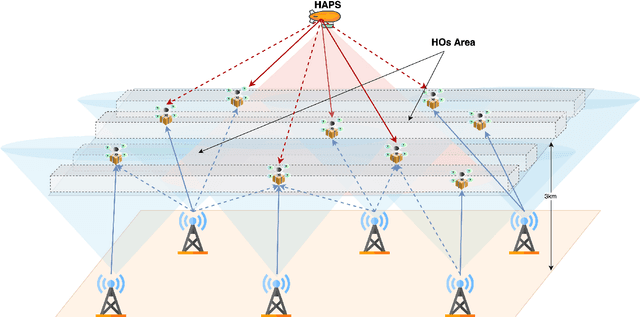
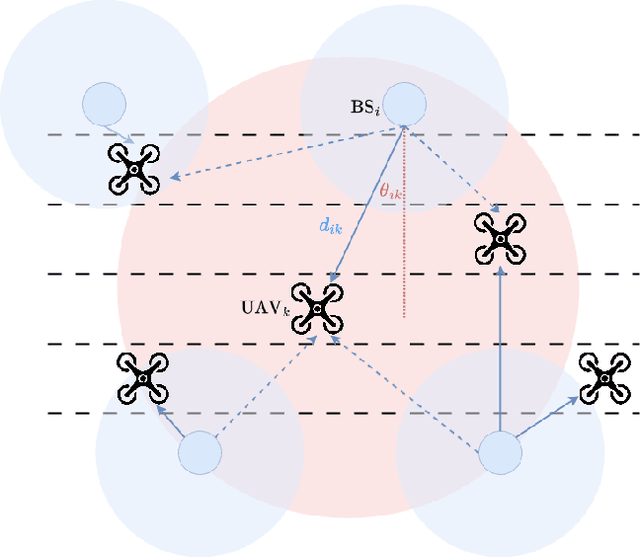
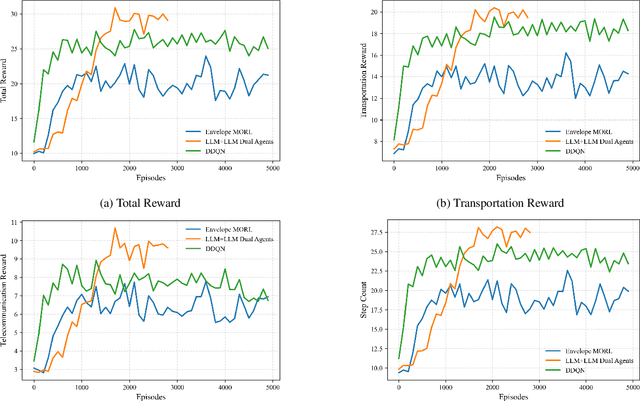
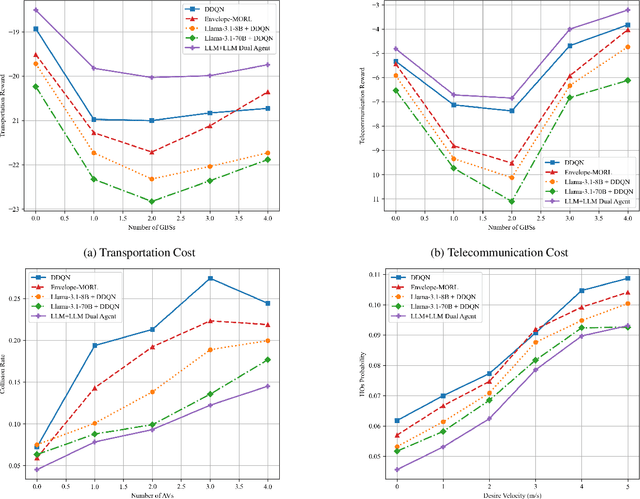
Unmanned aerial vehicles (UAVs) have been widely adopted in various real-world applications. However, the control and optimization of multi-UAV systems remain a significant challenge, particularly in dynamic and constrained environments. This work explores the joint motion and communication control of multiple UAVs operating within integrated terrestrial and non-terrestrial networks that include high-altitude platform stations (HAPS). Specifically, we consider an aerial highway scenario in which UAVs must accelerate, decelerate, and change lanes to avoid collisions and maintain overall traffic flow. Different from existing studies, we propose a novel hierarchical and collaborative method based on large language models (LLMs). In our approach, an LLM deployed on the HAPS performs UAV access control, while another LLM onboard each UAV handles motion planning and control. This LLM-based framework leverages the rich knowledge embedded in pre-trained models to enable both high-level strategic planning and low-level tactical decisions. This knowledge-driven paradigm holds great potential for the development of next-generation 3D aerial highway systems. Experimental results demonstrate that our proposed collaborative LLM-based method achieves higher system rewards, lower operational costs, and significantly reduced UAV collision rates compared to baseline approaches.
Semantic-Aware Adaptive Video Streaming Using Latent Diffusion Models for Wireless Networks
Feb 08, 2025



This paper proposes a novel framework for real-time adaptive-bitrate video streaming by integrating latent diffusion models (LDMs) within the FFmpeg techniques. This solution addresses the challenges of high bandwidth usage, storage inefficiencies, and quality of experience (QoE) degradation associated with traditional constant bitrate streaming (CBS) and adaptive bitrate streaming (ABS). The proposed approach leverages LDMs to compress I-frames into a latent space, offering significant storage and semantic transmission savings without sacrificing high visual quality. While it keeps B-frames and P-frames as adjustment metadata to ensure efficient video reconstruction at the user side, the proposed framework is complemented with the most state-of-the-art denoising and video frame interpolation (VFI) techniques. These techniques mitigate semantic ambiguity and restore temporal coherence between frames, even in noisy wireless communication environments. Experimental results demonstrate the proposed method achieves high-quality video streaming with optimized bandwidth usage, outperforming state-of-the-art solutions in terms of QoE and resource efficiency. This work opens new possibilities for scalable real-time video streaming in 5G and future post-5G networks.
CVaR-Based Variational Quantum Optimization for User Association in Handoff-Aware Vehicular Networks
Jan 14, 2025Efficient resource allocation is essential for optimizing various tasks in wireless networks, which are usually formulated as generalized assignment problems (GAP). GAP, as a generalized version of the linear sum assignment problem, involves both equality and inequality constraints that add computational challenges. In this work, we present a novel Conditional Value at Risk (CVaR)-based Variational Quantum Eigensolver (VQE) framework to address GAP in vehicular networks (VNets). Our approach leverages a hybrid quantum-classical structure, integrating a tailored cost function that balances both objective and constraint-specific penalties to improve solution quality and stability. Using the CVaR-VQE model, we handle the GAP efficiently by focusing optimization on the lower tail of the solution space, enhancing both convergence and resilience on noisy intermediate-scale quantum (NISQ) devices. We apply this framework to a user-association problem in VNets, where our method achieves 23.5% improvement compared to the deep neural network (DNN) approach.
Hybrid LLM-DDQN based Joint Optimization of V2I Communication and Autonomous Driving
Oct 11, 2024Large language models (LLMs) have received considerable interest recently due to their outstanding reasoning and comprehension capabilities. This work explores applying LLMs to vehicular networks, aiming to jointly optimize vehicle-to-infrastructure (V2I) communications and autonomous driving (AD) policies. We deploy LLMs for AD decision-making to maximize traffic flow and avoid collisions for road safety, and a double deep Q-learning algorithm (DDQN) is used for V2I optimization to maximize the received data rate and reduce frequent handovers. In particular, for LLM-enabled AD, we employ the Euclidean distance to identify previously explored AD experiences, and then LLMs can learn from past good and bad decisions for further improvement. Then, LLM-based AD decisions will become part of states in V2I problems, and DDQN will optimize the V2I decisions accordingly. After that, the AD and V2I decisions are iteratively optimized until convergence. Such an iterative optimization approach can better explore the interactions between LLMs and conventional reinforcement learning techniques, revealing the potential of using LLMs for network optimization and management. Finally, the simulations demonstrate that our proposed hybrid LLM-DDQN approach outperforms the conventional DDQN algorithm, showing faster convergence and higher average rewards.
Optimizing Vehicular Networks with Variational Quantum Circuits-based Reinforcement Learning
May 29, 2024In vehicular networks (VNets), ensuring both road safety and dependable network connectivity is of utmost importance. Achieving this necessitates the creation of resilient and efficient decision-making policies that prioritize multiple objectives. In this paper, we develop a Variational Quantum Circuit (VQC)-based multi-objective reinforcement learning (MORL) framework to characterize efficient network selection and autonomous driving policies in a vehicular network (VNet). Numerical results showcase notable enhancements in both convergence rates and rewards when compared to conventional deep-Q networks (DQNs), validating the efficacy of the VQC-MORL solution.
Generalized Multi-Objective Reinforcement Learning with Envelope Updates in URLLC-enabled Vehicular Networks
May 18, 2024
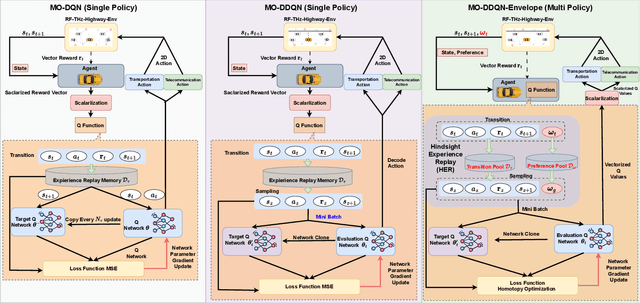


We develop a novel multi-objective reinforcement learning (MORL) framework to jointly optimize wireless network selection and autonomous driving policies in a multi-band vehicular network operating on conventional sub-6GHz spectrum and Terahertz frequencies. The proposed framework is designed to 1. maximize the traffic flow and 2. minimize collisions by controlling the vehicle's motion dynamics (i.e., speed and acceleration), and enhance the ultra-reliable low-latency communication (URLLC) while minimizing handoffs (HOs). We cast this problem as a multi-objective Markov Decision Process (MOMDP) and develop solutions for both predefined and unknown preferences of the conflicting objectives. Specifically, deep-Q-network and double deep-Q-network-based solutions are developed first that consider scalarizing the transportation and telecommunication rewards using predefined preferences. We then develop a novel envelope MORL solution which develop policies that address multiple objectives with unknown preferences to the agent. While this approach reduces reliance on scalar rewards, policy effectiveness varying with different preferences is a challenge. To address this, we apply a generalized version of the Bellman equation and optimize the convex envelope of multi-objective Q values to learn a unified parametric representation capable of generating optimal policies across all possible preference configurations. Following an initial learning phase, our agent can execute optimal policies under any specified preference or infer preferences from minimal data samples.Numerical results validate the efficacy of the envelope-based MORL solution and demonstrate interesting insights related to the inter-dependency of vehicle motion dynamics, HOs, and the communication data rate. The proposed policies enable autonomous vehicles to adopt safe driving behaviors with improved connectivity.
Multi-UAV Speed Control with Collision Avoidance and Handover-aware Cell Association: DRL with Action Branching
Jul 24, 2023



This paper presents a deep reinforcement learning solution for optimizing multi-UAV cell-association decisions and their moving velocity on a 3D aerial highway. The objective is to enhance transportation and communication performance, including collision avoidance, connectivity, and handovers. The problem is formulated as a Markov decision process (MDP) with UAVs' states defined by velocities and communication data rates. We propose a neural architecture with a shared decision module and multiple network branches, each dedicated to a specific action dimension in a 2D transportation-communication space. This design efficiently handles the multi-dimensional action space, allowing independence for individual action dimensions. We introduce two models, Branching Dueling Q-Network (BDQ) and Branching Dueling Double Deep Q-Network (Dueling DDQN), to demonstrate the approach. Simulation results show a significant improvement of 18.32% compared to existing benchmarks.
Reinforcement Learning for Joint V2I Network Selection and Autonomous Driving Policies
Aug 03, 2022

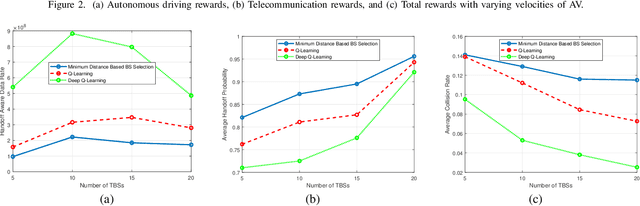

Vehicle-to-Infrastructure (V2I) communication is becoming critical for the enhanced reliability of autonomous vehicles (AVs). However, the uncertainties in the road-traffic and AVs' wireless connections can severely impair timely decision-making. It is thus critical to simultaneously optimize the AVs' network selection and driving policies in order to minimize road collisions while maximizing the communication data rates. In this paper, we develop a reinforcement learning (RL) framework to characterize efficient network selection and autonomous driving policies in a multi-band vehicular network (VNet) operating on conventional sub-6GHz spectrum and Terahertz (THz) frequencies. The proposed framework is designed to (i) maximize the traffic flow and minimize collisions by controlling the vehicle's motion dynamics (i.e., speed and acceleration) from autonomous driving perspective, and (ii) maximize the data rates and minimize handoffs by jointly controlling the vehicle's motion dynamics and network selection from telecommunication perspective. We cast this problem as a Markov Decision Process (MDP) and develop a deep Q-learning based solution to optimize the actions such as acceleration, deceleration, lane-changes, and AV-base station assignments for a given AV's state. The AV's state is defined based on the velocities and communication channel states of AVs. Numerical results demonstrate interesting insights related to the inter-dependency of vehicle's motion dynamics, handoffs, and the communication data rate. The proposed policies enable AVs to adopt safe driving behaviors with improved connectivity.