 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantic-Aware Adaptive Video Streaming Using Latent Diffusion Models for Wireless Networks
Feb 08, 2025



This paper proposes a novel framework for real-time adaptive-bitrate video streaming by integrating latent diffusion models (LDMs) within the FFmpeg techniques. This solution addresses the challenges of high bandwidth usage, storage inefficiencies, and quality of experience (QoE) degradation associated with traditional constant bitrate streaming (CBS) and adaptive bitrate streaming (ABS). The proposed approach leverages LDMs to compress I-frames into a latent space, offering significant storage and semantic transmission savings without sacrificing high visual quality. While it keeps B-frames and P-frames as adjustment metadata to ensure efficient video reconstruction at the user side, the proposed framework is complemented with the most state-of-the-art denoising and video frame interpolation (VFI) techniques. These techniques mitigate semantic ambiguity and restore temporal coherence between frames, even in noisy wireless communication environments. Experimental results demonstrate the proposed method achieves high-quality video streaming with optimized bandwidth usage, outperforming state-of-the-art solutions in terms of QoE and resource efficiency. This work opens new possibilities for scalable real-time video streaming in 5G and future post-5G networks.
Straggler-resilient Federated Learning: Tackling Computation Heterogeneity with Layer-wise Partial Model Training in Mobile Edge Network
Nov 16, 2023



Federated Learning (FL) enables many resource-limited devices to train a model collaboratively without data sharing. However, many existing works focus on model-homogeneous FL, where the global and local models are the same size, ignoring the inherently heterogeneous computational capabilities of different devices and restricting resource-constrained devices from contributing to FL. In this paper, we consider model-heterogeneous FL and propose Federated Partial Model Training (FedPMT), where devices with smaller computational capabilities work on partial models (subsets of the global model) and contribute to the global model. Different from Dropout-based partial model generation, which removes neurons in hidden layers at random, model training in FedPMT is achieved from the back-propagation perspective. As such, all devices in FedPMT prioritize the most crucial parts of the global model. Theoretical analysis shows that the proposed partial model training design has a similar convergence rate to the widely adopted Federated Averaging (FedAvg) algorithm, $\mathcal{O}(1/T)$, with the sub-optimality gap enlarged by a constant factor related to the model splitting design in FedPMT. Empirical results show that FedPMT significantly outperforms the existing benchmark FedDrop. Meanwhile, compared to the popular model-homogeneous benchmark, FedAvg, FedPMT reaches the learning target in a shorter completion time, thus achieving a better trade-off between learning accuracy and completion time.
A Deep Reinforcement Learning-Based Caching Strategy for IoT Networks with Transient Data
Mar 16, 2022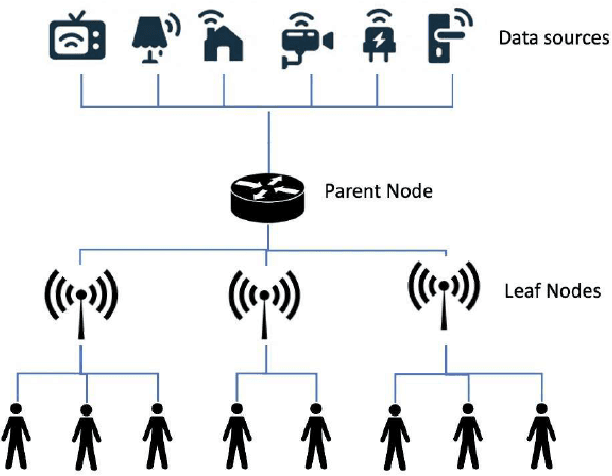

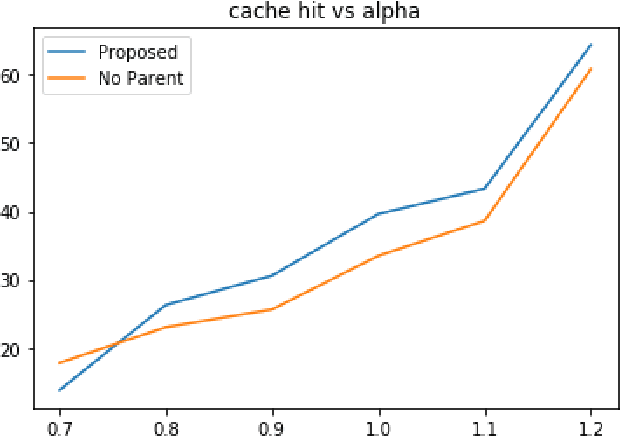
The Internet of Things (IoT) has been continuously rising in the past few years, and its potentials are now more apparent. However, transient data generation and limited energy resources are the major bottlenecks of these networks. Besides, minimum delay and other conventional quality of service measurements are still valid requirements to meet. An efficient caching policy can help meet the standard quality of service requirements while bypassing IoT networks' specific limitations. Adopting deep reinforcement learning (DRL) algorithms enables us to develop an effective caching scheme without the need for any prior knowledge or contextual information. In this work, we propose a DRL-based caching scheme that improves the cache hit rate and reduces energy consumption of the IoT networks, in the meanwhile, taking data freshness and limited lifetime of IoT data into account. To better capture the regional-different popularity distribution, we propose a hierarchical architecture to deploy edge caching nodes in IoT networks. The results of comprehensive experiments show that our proposed method outperforms the well-known conventional caching policies and an existing DRL-based solution in terms of cache hit rate and energy consumption of the IoT networks by considerable margins.
Node Selection Toward Faster Convergence for Federated Learning on Non-IID Data
May 14, 2021



Federated Learning (FL) is a distributed learning paradigm that enables a large number of resource-limited nodes to collaboratively train a model without data sharing. The non-independent-and-identically-distributed (non-i.i.d.) data samples invoke discrepancy between global and local objectives, making the FL model slow to converge. In this paper, we proposed Optimal Aggregation algorithm for better aggregation, which finds out the optimal subset of local updates of participating nodes in each global round, by identifying and excluding the adverse local updates via checking the relationship between the local gradient and the global gradient. Then, we proposed a Probabilistic Node Selection framework (FedPNS) to dynamically change the probability for each node to be selected based on the output of Optimal Aggregation. FedPNS can preferentially select nodes that propel faster model convergence. The unbiasedness of the proposed FedPNS design is illustrated and the convergence rate improvement of FedPNS over the commonly adopted Federated Averaging (FedAvg) algorithm is analyzed theoretically. Experimental results demonstrate the effectiveness of FedPNS in accelerating the FL convergence rate, as compared to FedAvg with random node selection.
Fast-Convergent Federated Learning with Adaptive Weighting
Dec 01, 2020
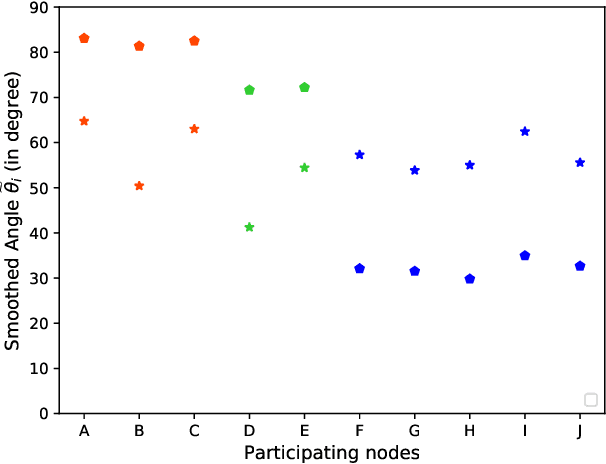
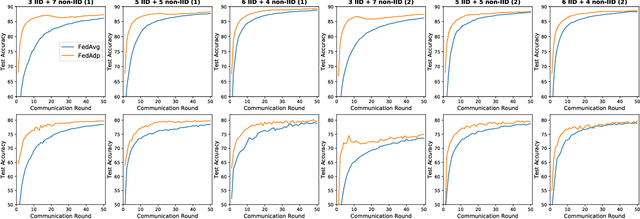
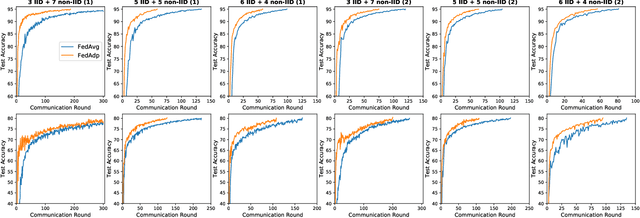
Federated learning (FL) enables resource-constrained edge nodes to collaboratively learn a global model under the orchestration of a central server while keeping privacy-sensitive data locally. The non-independent-and-identically-distributed (non-IID) data samples across participating nodes slow model training and impose additional communication rounds for FL to converge. In this paper, we propose Federated Adaptive Weighting (FedAdp) algorithm that aims to accelerate model convergence under the presence of nodes with non-IID dataset. We observe the implicit connection between the node contribution to the global model aggregation and data distribution on the local node through theoretical and empirical analysis. We then propose to assign different weights for updating the global model based on node contribution adaptively through each training round. The contribution of participating nodes is first measured by the angle between the local gradient vector and the global gradient vector, and then, weight is quantified by a designed non-linear mapping function subsequently. The simple yet effective strategy can reinforce positive (suppress negative) node contribution dynamically, resulting in communication round reduction drastically. Its superiority over the commonly adopted Federated Averaging (FedAvg) is verified both theoretically and experimentally. With extensive experiments performed in Pytorch and PySyft, we show that FL training with FedAdp can reduce the number of communication rounds by up to 54.1% on MNIST dataset and up to 45.4% on FashionMNIST dataset, as compared to FedAvg algorithm.