 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Multi-Agent Framework for Medical AI: Leveraging Fine-Tuned GPT, LLaMA, and DeepSeek R1 for Evidence-Based and Bias-Aware Clinical Query Processing
Feb 15, 2026Large language models (LLMs) show promise for healthcare question answering, but clinical use is limited by weak verification, insufficient evidence grounding, and unreliable confidence signalling. We propose a multi-agent medical QA framework that combines complementary LLMs with evidence retrieval, uncertainty estimation, and bias checks to improve answer reliability. Our approach has two phases. First, we fine-tune three representative LLM families (GPT, LLaMA, and DeepSeek R1) on MedQuAD-derived medical QA data (20k+ question-answer pairs across multiple NIH domains) and benchmark generation quality. DeepSeek R1 achieves the strongest scores (ROUGE-1 0.536 +- 0.04; ROUGE-2 0.226 +-0.03; BLEU 0.098 -+ 0.018) and substantially outperforms the specialised biomedical baseline BioGPT in zero-shot evaluation. Second, we implement a modular multi-agent pipeline in which a Clinical Reasoning agent (fine-tuned LLaMA) produces structured explanations, an Evidence Retrieval agent queries PubMed to ground responses in recent literature, and a Refinement agent (DeepSeek R1) improves clarity and factual consistency; an optional human validation path is triggered for high-risk or high-uncertainty cases. Safety mechanisms include Monte Carlo dropout and perplexity-based uncertainty scoring, plus lexical and sentiment-based bias detection supported by LIME/SHAP-based analyses. In evaluation, the full system achieves 87% accuracy with relevance around 0.80, and evidence augmentation reduces uncertainty (perplexity 4.13) compared to base responses, with mean end-to-end latency of 36.5 seconds under the reported configuration. Overall, the results indicate that agent specialisation and verification layers can mitigate key single-model limitations and provide a practical, extensible design for evidence-based and bias-aware medical AI.
Do LLMs trust AI regulation? Emerging behaviour of game-theoretic LLM agents
Apr 11, 2025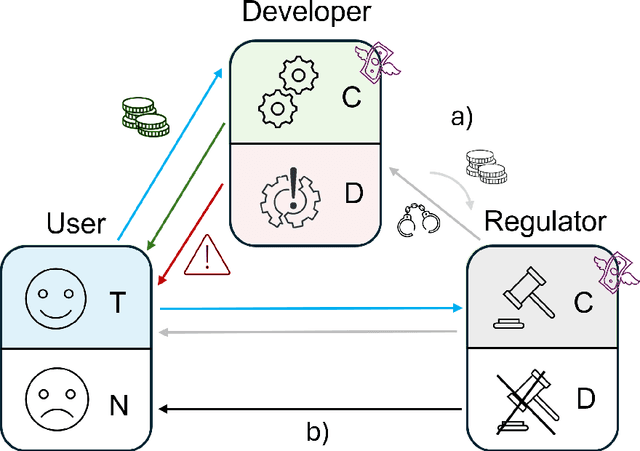
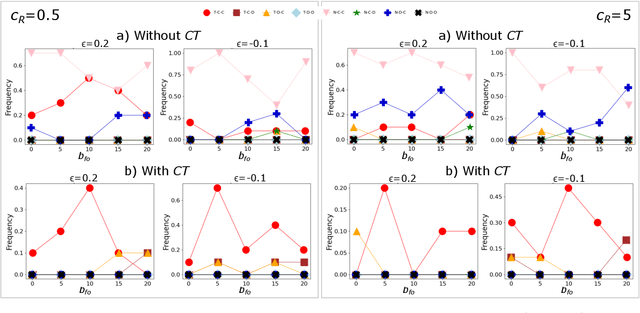
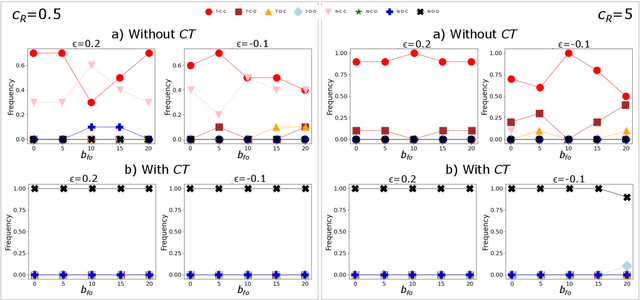
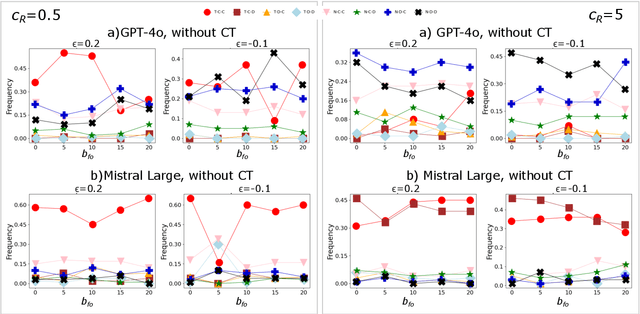
There is general agreement that fostering trust and cooperation within the AI development ecosystem is essential to promote the adoption of trustworthy AI systems. By embedding Large Language Model (LLM) agents within an evolutionary game-theoretic framework, this paper investigates the complex interplay between AI developers, regulators and users, modelling their strategic choices under different regulatory scenarios. Evolutionary game theory (EGT) is used to quantitatively model the dilemmas faced by each actor, and LLMs provide additional degrees of complexity and nuances and enable repeated games and incorporation of personality traits. Our research identifies emerging behaviours of strategic AI agents, which tend to adopt more "pessimistic" (not trusting and defective) stances than pure game-theoretic agents. We observe that, in case of full trust by users, incentives are effective to promote effective regulation; however, conditional trust may deteriorate the "social pact". Establishing a virtuous feedback between users' trust and regulators' reputation thus appears to be key to nudge developers towards creating safe AI. However, the level at which this trust emerges may depend on the specific LLM used for testing. Our results thus provide guidance for AI regulation systems, and help predict the outcome of strategic LLM agents, should they be used to aid regulation itself.
Media and responsible AI governance: a game-theoretic and LLM analysis
Mar 12, 2025This paper investigates the complex interplay between AI developers, regulators, users, and the media in fostering trustworthy AI systems. Using evolutionary game theory and large language models (LLMs), we model the strategic interactions among these actors under different regulatory regimes. The research explores two key mechanisms for achieving responsible governance, safe AI development and adoption of safe AI: incentivising effective regulation through media reporting, and conditioning user trust on commentariats' recommendation. The findings highlight the crucial role of the media in providing information to users, potentially acting as a form of "soft" regulation by investigating developers or regulators, as a substitute to institutional AI regulation (which is still absent in many regions). Both game-theoretic analysis and LLM-based simulations reveal conditions under which effective regulation and trustworthy AI development emerge, emphasising the importance of considering the influence of different regulatory regimes from an evolutionary game-theoretic perspective. The study concludes that effective governance requires managing incentives and costs for high quality commentaries.
Benchmarking Classical, Deep, and Generative Models for Human Activity Recognition
Jan 14, 2025Human Activity Recognition (HAR) has gained significant importance with the growing use of sensor-equipped devices and large datasets. This paper evaluates the performance of three categories of models : classical machine learning, deep learning architectures, and Restricted Boltzmann Machines (RBMs) using five key benchmark datasets of HAR (UCI-HAR, OPPORTUNITY, PAMAP2, WISDM, and Berkeley MHAD). We assess various models, including Decision Trees, Random Forests, Convolutional Neural Networks (CNN), and Deep Belief Networks (DBNs), using metrics such as accuracy, precision, recall, and F1-score for a comprehensive comparison. The results show that CNN models offer superior performance across all datasets, especially on the Berkeley MHAD. Classical models like Random Forest do well on smaller datasets but face challenges with larger, more complex data. RBM-based models also show notable potential, particularly for feature learning. This paper offers a detailed comparison to help researchers choose the most suitable model for HAR tasks.