 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Assistive Impulses: Synthesizing Exaggerated Motions for Physics-based Characters
Apr 07, 2026Physics-based character animation has become a fundamental approach for synthesizing realistic, physically plausible motions. While current data-driven deep reinforcement learning (DRL) methods can synthesize complex skills, they struggle to reproduce exaggerated, stylized motions, such as instantaneous dashes or mid-air trajectory changes, which are required in animation but violate standard physical laws. The primary limitation stems from modeling the character as an underactuated floating-base system, in which internal joint torques and momentum conservation strictly govern motion. Direct attempts to enforce such motions via external wrenches often lead to training instability, as velocity discontinuities produce sparse, high-magnitude force spikes that prevent policy convergence. We propose Assistive Impulse Neural Control, a framework that reformulates external assistance in impulse space rather than force space to ensure numerical stability. We decompose the assistive signal into an analytic high-frequency component derived from Inverse Dynamics and a learned low-frequency residual correction, governed by a hybrid neural policy. We demonstrate that our method enables robust tracking of highly agile, dynamically infeasible maneuvers that were previously intractable for physics-based methods.
Co-design of Embodied Neural Intelligence via Constrained Evolution
May 21, 2022
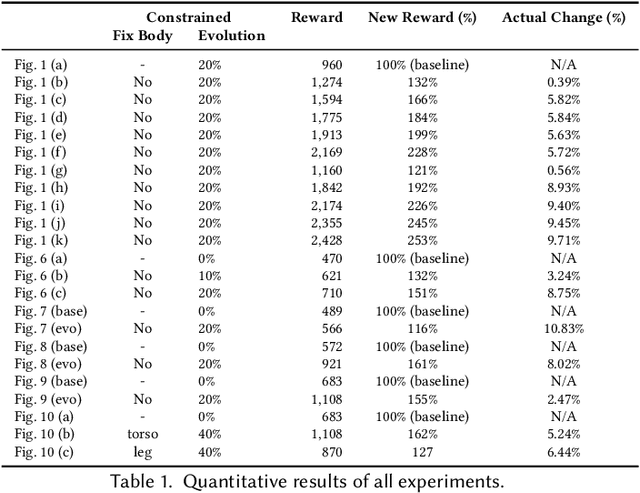
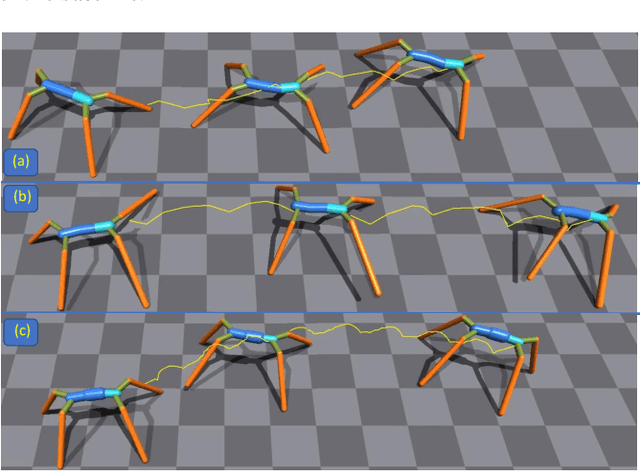
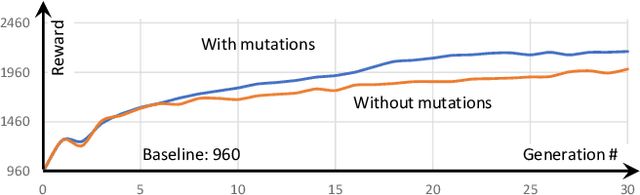
We introduce a novel co-design method for autonomous moving agents' shape attributes and locomotion by combining deep reinforcement learning and evolution with user control. Our main inspiration comes from evolution, which has led to wide variability and adaptation in Nature and has the potential to significantly improve design and behavior simultaneously. Our method takes an input agent with optional simple constraints such as leg parts that should not evolve or allowed ranges of changes. It uses physics-based simulation to determine its locomotion and finds a behavior policy for the input design, later used as a baseline for comparison. The agent is then randomly modified within the allowed ranges creating a new generation of several hundred agents. The generation is trained by transferring the previous policy, which significantly speeds up the training. The best-performing agents are selected, and a new generation is formed using their crossover and mutations. The next generations are then trained until satisfactory results are reached. We show a wide variety of evolved agents, and our results show that even with only 10% of changes, the overall performance of the evolved agents improves 50%. If more significant changes to the initial design are allowed, our experiments' performance improves even more to 150%. Contrary to related work, our co-design works on a single GPU and provides satisfactory results by training thousands of agents within one hour.
One-way Hash Function Based on Neural Network
Jul 27, 2007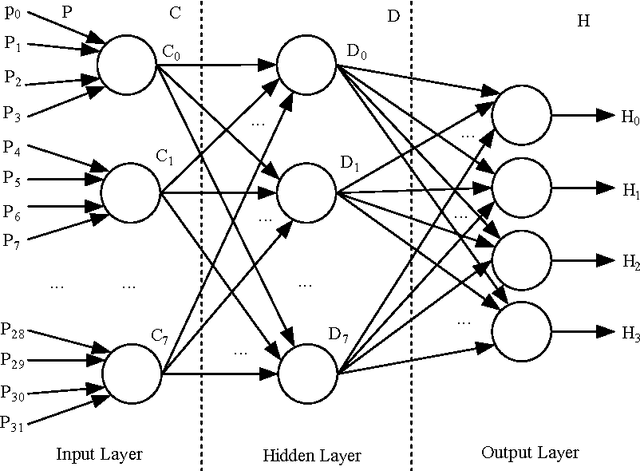

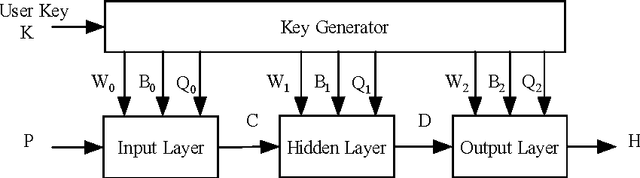
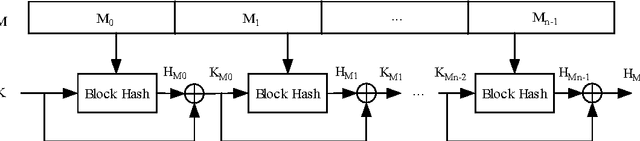
A hash function is constructed based on a three-layer neural network. The three neuron-layers are used to realize data confusion, diffusion and compression respectively, and the multi-block hash mode is presented to support the plaintext with variable length. Theoretical analysis and experimental results show that this hash function is one-way, with high key sensitivity and plaintext sensitivity, and secure against birthday attacks or meet-in-the-middle attacks. Additionally, the neural network's property makes it practical to realize in a parallel way. These properties make it a suitable choice for data signature or authentication.