 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging Text Data Using Hybrid Transformer-LSTM Based End-to-End ASR in Transfer Learning
May 28, 2020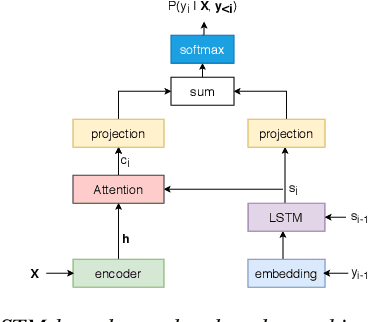
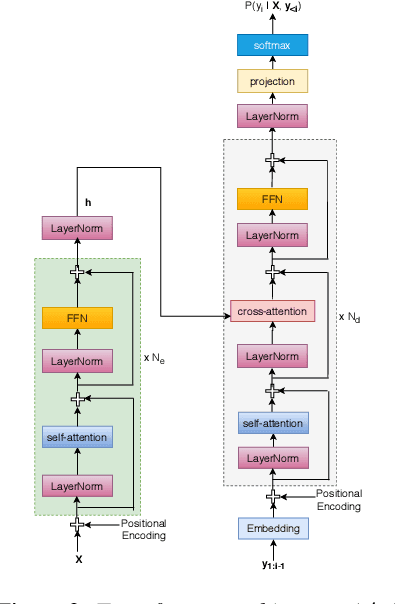

In this work, we study leveraging extra text data to improve low-resource end-to-end ASR under cross-lingual transfer learning setting. To this end, we extend our prior work [1], and propose a hybrid Transformer-LSTM based architecture. This architecture not only takes advantage of the highly effective encoding capacity of the Transformer network but also benefits from extra text data due to the LSTM-based independent language model network. We conduct experiments on our in-house Malay corpus which contains limited labeled data and a large amount of extra text. Results show that the proposed architecture outperforms the previous LSTM-based architecture [1] by 24.2% relative word error rate (WER) when both are trained using limited labeled data. Starting from this, we obtain further 25.4% relative WER reduction by transfer learning from another resource-rich language. Moreover, we obtain additional 13.6% relative WER reduction by boosting the LSTM decoder of the transferred model with the extra text data. Overall, our best model outperforms the vanilla Transformer ASR by 11.9% relative WER. Last but not least, the proposed hybrid architecture offers much faster inference compared to both LSTM and Transformer architectures.
Independent language modeling architecture for end-to-end ASR
Nov 25, 2019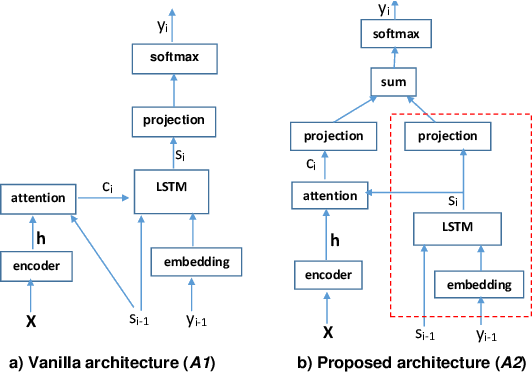
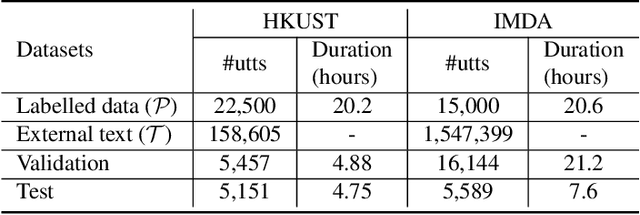
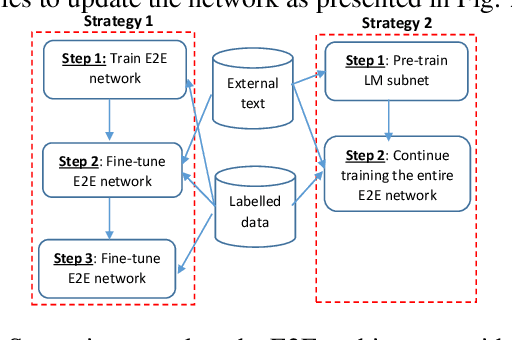
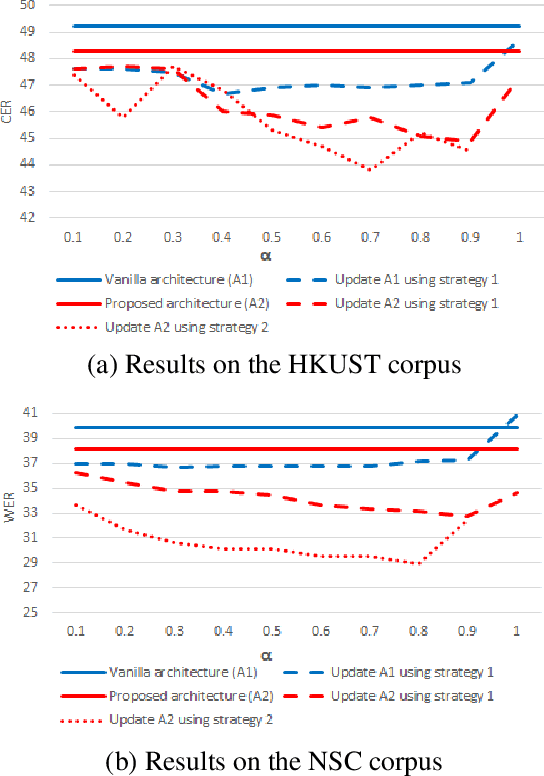
The attention-based end-to-end (E2E) automatic speech recognition (ASR) architecture allows for joint optimization of acoustic and language models within a single network. However, in a vanilla E2E ASR architecture, the decoder sub-network (subnet), which incorporates the role of the language model (LM), is conditioned on the encoder output. This means that the acoustic encoder and the language model are entangled that doesn't allow language model to be trained separately from external text data. To address this problem, in this work, we propose a new architecture that separates the decoder subnet from the encoder output. In this way, the decoupled subnet becomes an independently trainable LM subnet, which can easily be updated using the external text data. We study two strategies for updating the new architecture. Experimental results show that, 1) the independent LM architecture benefits from external text data, achieving 9.3% and 22.8% relative character and word error rate reduction on Mandarin HKUST and English NSC datasets respectively; 2)the proposed architecture works well with external LM and can be generalized to different amount of labelled data.
Constrained Output Embeddings for End-to-End Code-Switching Speech Recognition with Only Monolingual Data
Apr 08, 2019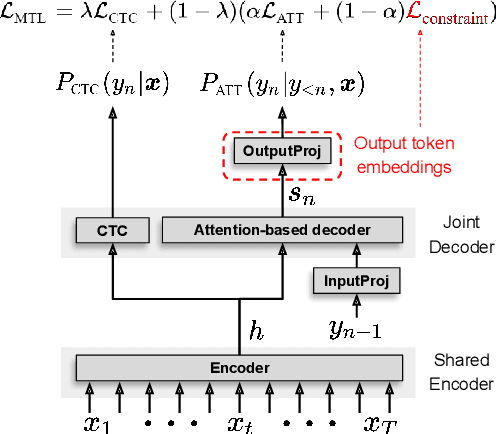
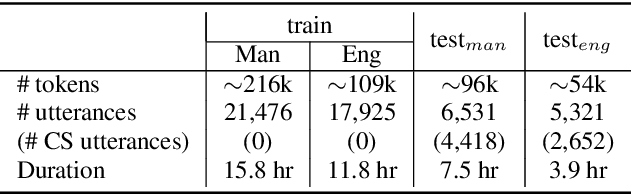
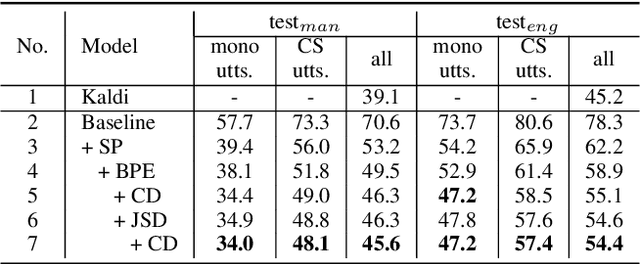
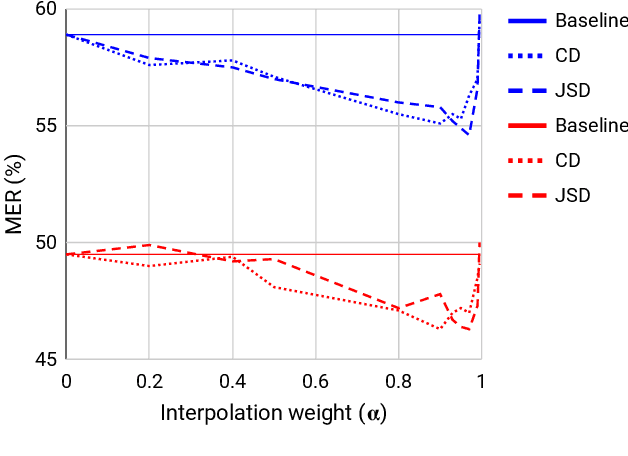
The lack of code-switch training data is one of the major concerns in the development of end-to-end code-switching automatic speech recognition (ASR) models. In this work, we propose a method to train an improved end-to-end code-switching ASR using only monolingual data. Our method encourages the distributions of output token embeddings of monolingual languages to be similar, and hence, promotes the ASR model to easily code-switch between languages. Specifically, we propose to use Jensen-Shannon divergence and cosine distance based constraints. The former will enforce output embeddings of monolingual languages to possess similar distributions, while the later simply brings the centroids of two distributions to be close to each other. Experimental results demonstrate high effectiveness of the proposed method, yielding up to 4.5% absolute mixed error rate improvement on Mandarin-English code-switching ASR task.
Enriching Rare Word Representations in Neural Language Models by Embedding Matrix Augmentation
Apr 08, 2019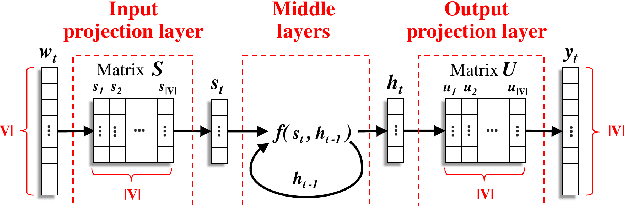
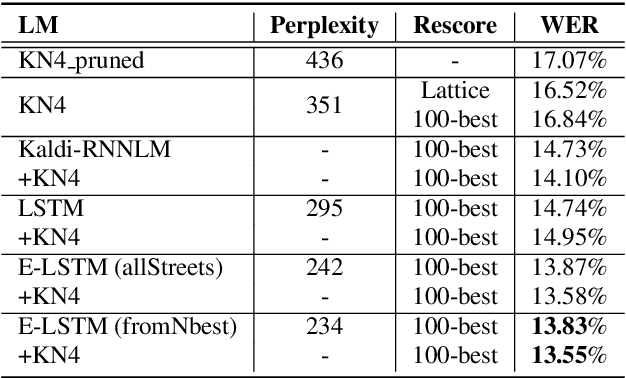

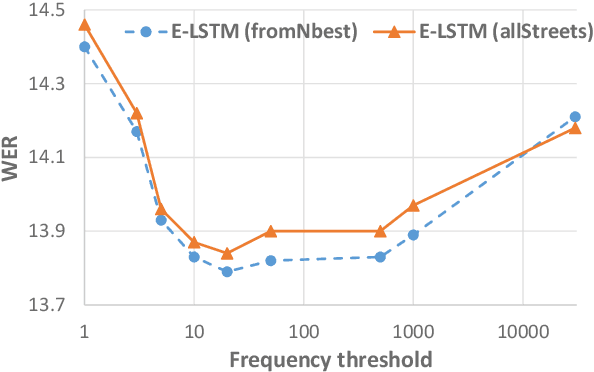
The neural language models (NLM) achieve strong generalization capability by learning the dense representation of words and using them to estimate probability distribution function. However, learning the representation of rare words is a challenging problem causing the NLM to produce unreliable probability estimates. To address this problem, we propose a method to enrich representations of rare words in pre-trained NLM and consequently improve its probability estimation performance. The proposed method augments the word embedding matrices of pre-trained NLM while keeping other parameters unchanged. Specifically, our method updates the embedding vectors of rare words using embedding vectors of other semantically and syntactically similar words. To evaluate the proposed method, we enrich the rare street names in the pre-trained NLM and use it to rescore 100-best hypotheses output from the Singapore English speech recognition system. The enriched NLM reduces the word error rate by 6% relative and improves the recognition accuracy of the rare words by 16% absolute as compared to the baseline NLM.
On the End-to-End Solution to Mandarin-English Code-switching Speech Recognition
Nov 01, 2018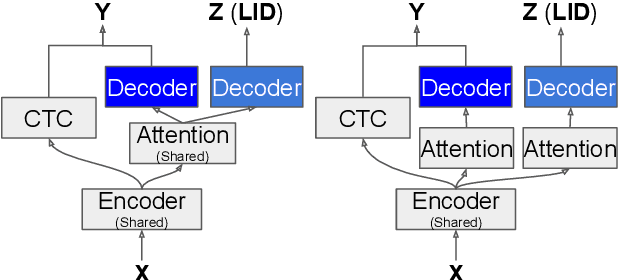
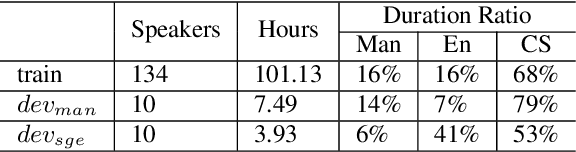
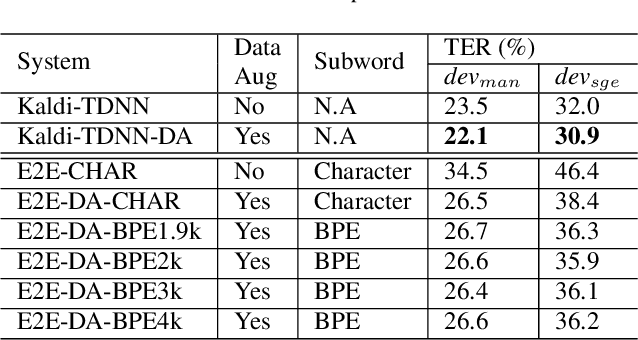
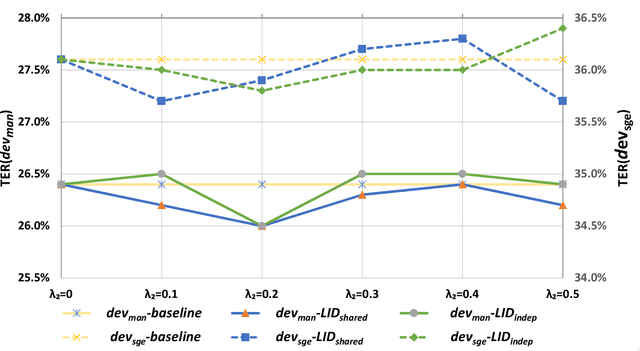
Code-switching (CS) refers to a linguistic phenomenon where a speaker uses different languages in an utterance or between alternating utterances. In this work, we study end-to-end (E2E) approaches to the Mandarin-English code-switching speech recognition (CSSR) task. We first examine the effectiveness of using data augmentation and byte-pair encoding (BPE) subword units. More importantly, we propose a multitask learning recipe, where a language identification task is explicitly learned in addition to the E2E speech recognition task. Furthermore, we introduce an efficient word vocabulary expansion method for language modeling to alleviate data sparsity issues under the code-switching scenario. Experimental results on the SEAME data, a Mandarin-English CS corpus, demonstrate the effectiveness of the proposed methods.