 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Step Back: Prefix Importance Ratio Stabilizes Policy Optimization
Jan 30, 2026Reinforcement learning (RL) post-training has increasingly demonstrated strong ability to elicit reasoning behaviors in large language models (LLMs). For training efficiency, rollouts are typically generated in an off-policy manner using an older sampling policy and then used to update the current target policy. To correct the resulting discrepancy between the sampling and target policies, most existing RL objectives rely on a token-level importance sampling ratio, primarily due to its computational simplicity and numerical stability. However, we observe that token-level correction often leads to unstable training dynamics when the degree of off-policyness is large. In this paper, we revisit LLM policy optimization under off-policy conditions and show that the theoretically rigorous correction term is the prefix importance ratio, and that relaxing it to a token-level approximation can induce instability in RL post-training. To stabilize LLM optimization under large off-policy drift, we propose a simple yet effective objective, Minimum Prefix Ratio (MinPRO). MinPRO replaces the unstable cumulative prefix ratio with a non-cumulative surrogate based on the minimum token-level ratio observed in the preceding prefix. Extensive experiments on both dense and mixture-of-experts LLMs, across multiple mathematical reasoning benchmarks, demonstrate that MinPRO substantially improves training stability and peak performance in off-policy regimes.
Offline Behavioral Data Selection
Dec 20, 2025


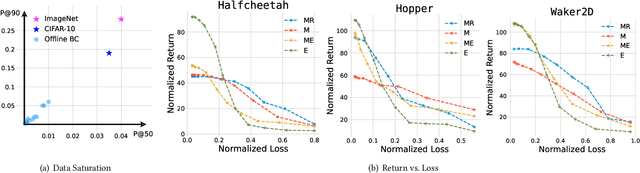
Behavioral cloning is a widely adopted approach for offline policy learning from expert demonstrations. However, the large scale of offline behavioral datasets often results in computationally intensive training when used in downstream tasks. In this paper, we uncover the striking data saturation in offline behavioral data: policy performance rapidly saturates when trained on a small fraction of the dataset. We attribute this effect to the weak alignment between policy performance and test loss, revealing substantial room for improvement through data selection. To this end, we propose a simple yet effective method, Stepwise Dual Ranking (SDR), which extracts a compact yet informative subset from large-scale offline behavioral datasets. SDR is build on two key principles: (1) stepwise clip, which prioritizes early-stage data; and (2) dual ranking, which selects samples with both high action-value rank and low state-density rank. Extensive experiments and ablation studies on D4RL benchmarks demonstrate that SDR significantly enhances data selection for offline behavioral data.
Quantum Imitation Learning
Apr 04, 2023Despite remarkable successes in solving various complex decision-making tasks, training an imitation learning (IL) algorithm with deep neural networks (DNNs) suffers from the high computation burden. In this work, we propose quantum imitation learning (QIL) with a hope to utilize quantum advantage to speed up IL. Concretely, we develop two QIL algorithms, quantum behavioural cloning (Q-BC) and quantum generative adversarial imitation learning (Q-GAIL). Q-BC is trained with a negative log-likelihood loss in an off-line manner that suits extensive expert data cases, whereas Q-GAIL works in an inverse reinforcement learning scheme, which is on-line and on-policy that is suitable for limited expert data cases. For both QIL algorithms, we adopt variational quantum circuits (VQCs) in place of DNNs for representing policies, which are modified with data re-uploading and scaling parameters to enhance the expressivity. We first encode classical data into quantum states as inputs, then perform VQCs, and finally measure quantum outputs to obtain control signals of agents. Experiment results demonstrate that both Q-BC and Q-GAIL can achieve comparable performance compared to classical counterparts, with the potential of quantum speed-up. To our knowledge, we are the first to propose the concept of QIL and conduct pilot studies, which paves the way for the quantum era.
Off-policy Imitation Learning from Visual Inputs
Nov 08, 2021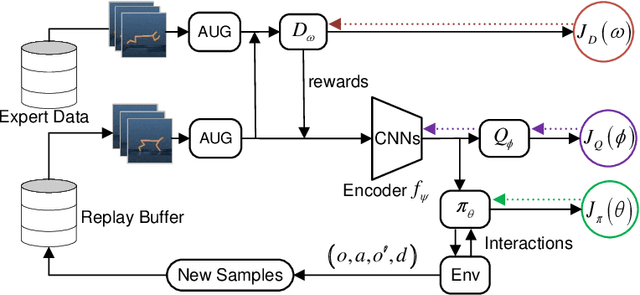
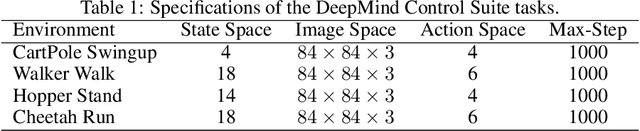
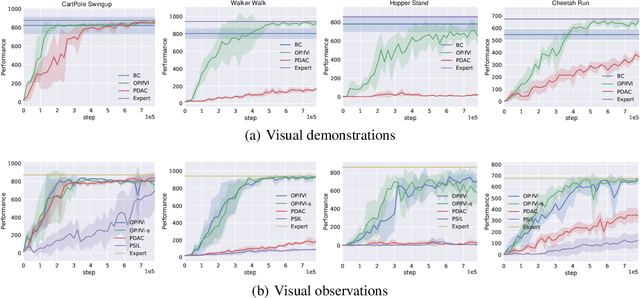
Recently, various successful applications utilizing expert states in imitation learning (IL) have been witnessed. However, another IL setting -- IL from visual inputs (ILfVI), which has a greater promise to be applied in reality by utilizing online visual resources, suffers from low data-efficiency and poor performance resulted from an on-policy learning manner and high-dimensional visual inputs. We propose OPIfVI (Off-Policy Imitation from Visual Inputs), which is composed of an off-policy learning manner, data augmentation, and encoder techniques, to tackle the mentioned challenges, respectively. More specifically, to improve data-efficiency, OPIfVI conducts IL in an off-policy manner, with which sampled data can be used multiple times. In addition, we enhance the stability of OPIfVI with spectral normalization to mitigate the side-effect of off-policy training. The core factor, contributing to the poor performance of ILfVI, that we think is the agent could not extract meaningful features from visual inputs. Hence, OPIfVI employs data augmentation from computer vision to help train encoders that can better extract features from visual inputs. In addition, a specific structure of gradient backpropagation for the encoder is designed to stabilize the encoder training. At last, we demonstrate that OPIfVI is able to achieve expert-level performance and outperform existing baselines no matter visual demonstrations or visual observations are provided via extensive experiments using DeepMind Control Suite.
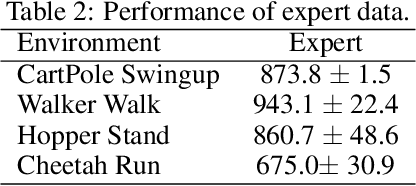
On the Guaranteed Almost Equivalence between Imitation Learning from Observation and Demonstration
Oct 16, 2020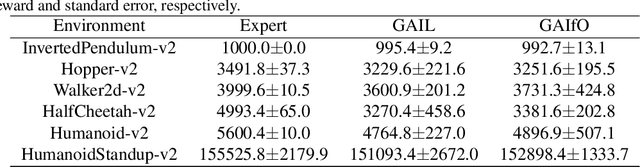
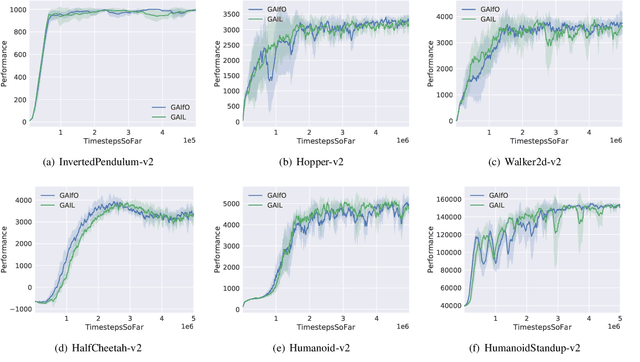
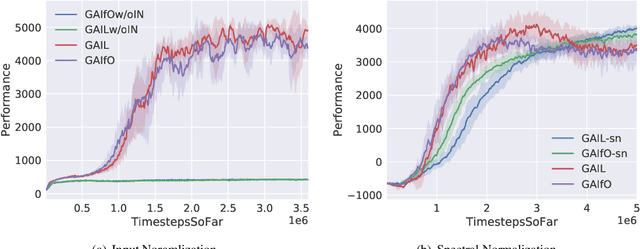
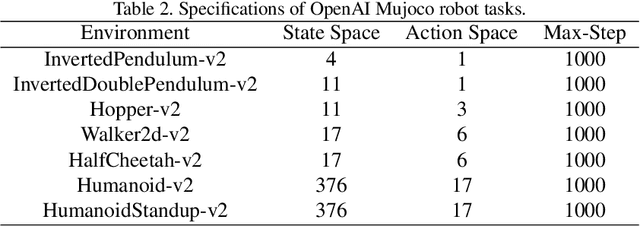
Imitation learning from observation (LfO) is more preferable than imitation learning from demonstration (LfD) due to the nonnecessity of expert actions when reconstructing the expert policy from the expert data. However, previous studies imply that the performance of LfO is inferior to LfD by a tremendous gap, which makes it challenging to employ LfO in practice. By contrast, this paper proves that LfO is almost equivalent to LfD in the deterministic robot environment, and more generally even in the robot environment with bounded randomness. In the deterministic robot environment, from the perspective of the control theory, we show that the inverse dynamics disagreement between LfO and LfD approaches zero, meaning that LfO is almost equivalent to LfD. To further relax the deterministic constraint and better adapt to the practical environment, we consider bounded randomness in the robot environment and prove that the optimizing targets for both LfD and LfO remain almost same in the more generalized setting. Extensive experiments for multiple robot tasks are conducted to empirically demonstrate that LfO achieves comparable performance to LfD. In fact, most common robot systems in reality are the robot environment with bounded randomness (i.e., the environment this paper considered). Hence, our findings greatly extend the potential of LfO and suggest that we can safely apply LfO without sacrificing the performance compared to LfD in practice.