 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Guaranteed Almost Equivalence between Imitation Learning from Observation and Demonstration
Paper and Code
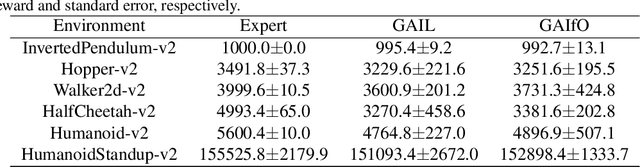
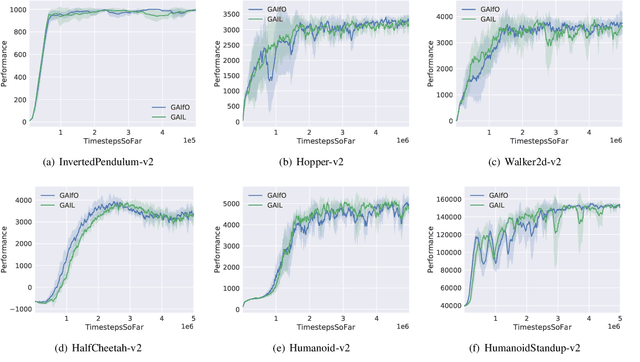
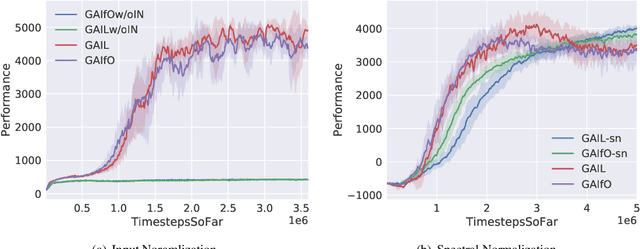
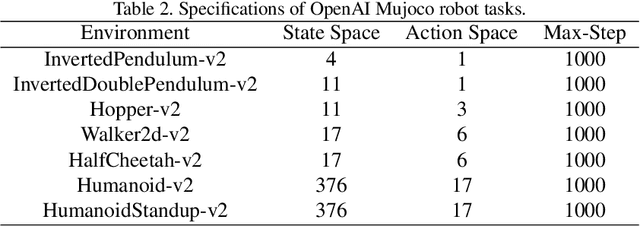
Imitation learning from observation (LfO) is more preferable than imitation learning from demonstration (LfD) due to the nonnecessity of expert actions when reconstructing the expert policy from the expert data. However, previous studies imply that the performance of LfO is inferior to LfD by a tremendous gap, which makes it challenging to employ LfO in practice. By contrast, this paper proves that LfO is almost equivalent to LfD in the deterministic robot environment, and more generally even in the robot environment with bounded randomness. In the deterministic robot environment, from the perspective of the control theory, we show that the inverse dynamics disagreement between LfO and LfD approaches zero, meaning that LfO is almost equivalent to LfD. To further relax the deterministic constraint and better adapt to the practical environment, we consider bounded randomness in the robot environment and prove that the optimizing targets for both LfD and LfO remain almost same in the more generalized setting. Extensive experiments for multiple robot tasks are conducted to empirically demonstrate that LfO achieves comparable performance to LfD. In fact, most common robot systems in reality are the robot environment with bounded randomness (i.e., the environment this paper considered). Hence, our findings greatly extend the potential of LfO and suggest that we can safely apply LfO without sacrificing the performance compared to LfD in practice.