 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOff-policy Imitation Learning from Visual Inputs
Paper and Code
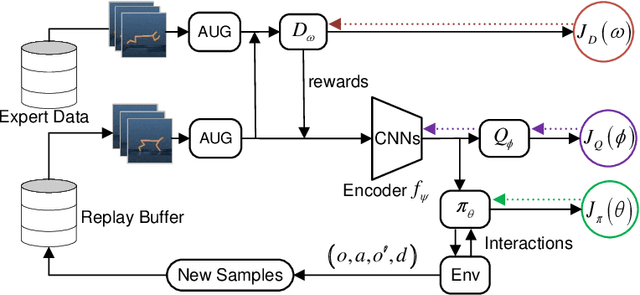
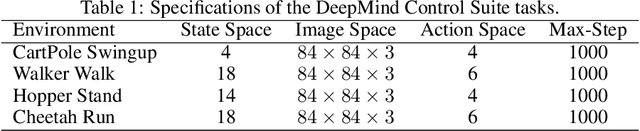
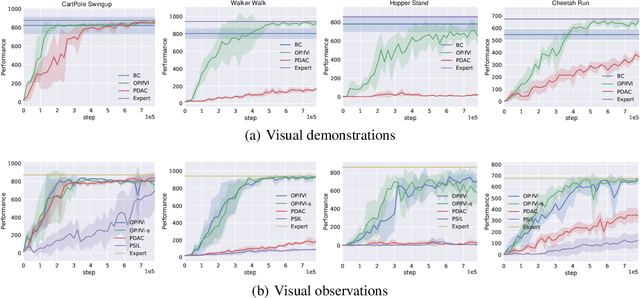
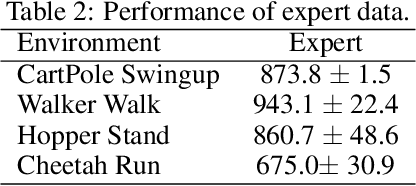
Recently, various successful applications utilizing expert states in imitation learning (IL) have been witnessed. However, another IL setting -- IL from visual inputs (ILfVI), which has a greater promise to be applied in reality by utilizing online visual resources, suffers from low data-efficiency and poor performance resulted from an on-policy learning manner and high-dimensional visual inputs. We propose OPIfVI (Off-Policy Imitation from Visual Inputs), which is composed of an off-policy learning manner, data augmentation, and encoder techniques, to tackle the mentioned challenges, respectively. More specifically, to improve data-efficiency, OPIfVI conducts IL in an off-policy manner, with which sampled data can be used multiple times. In addition, we enhance the stability of OPIfVI with spectral normalization to mitigate the side-effect of off-policy training. The core factor, contributing to the poor performance of ILfVI, that we think is the agent could not extract meaningful features from visual inputs. Hence, OPIfVI employs data augmentation from computer vision to help train encoders that can better extract features from visual inputs. In addition, a specific structure of gradient backpropagation for the encoder is designed to stabilize the encoder training. At last, we demonstrate that OPIfVI is able to achieve expert-level performance and outperform existing baselines no matter visual demonstrations or visual observations are provided via extensive experiments using DeepMind Control Suite.