 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHistogramless Time-Domain Sketched Fluorescence Lifetime Imaging
May 07, 2026We present a statistics-aware compression strategy that processes photon timestamps directly from time-correlated single-photon counting (TCSPC) modules for time-domain fluorescence lifetime imaging (FLIM). Rather than storing or transmitting the full histogram per pixel, timestamps are projected onto sparse, non-uniform one-dimensional spline sketches, with knot positions optimally allocated based on Fisher information. This knot allocation concentrates sketch channels where the decay signal exhibits the greatest statistical discriminability, rather than using a uniform allocation. The proposed approach is extensively validated on synthetic mono- and bi-exponential decay data and on experimental fluorescent dye data, demonstrating comparable accuracy to full-histogram non-linear least-squares fitting (NLSF) and Poisson maximum-likelihood estimation (MLE) at compression ratios of up to 256x. We further validate the feasibility of integrating the timestamp-to-sketch projection directly into firmware via fixed-point (FXP) lookup-table (LUT) simulation, targeting high-spatial-resolution single-photon avalanche diode (SPAD) arrays subject to significant data-throughput constraints.
On-Device Super Resolution Imaging Using Low-Cost SPAD Array and Embedded Lightweight Deep Learning
Mar 27, 2026This work presents a lightweight super-resolution (LiteSR) neural network for depth and intensity images acquired from a consumer-grade single-photon avalanche diode (SPAD) array with a 48x32 spatial resolution. The proposed framework reconstructs high-resolution (HR) images of size 256x256. Both synthetic and real datasets are used for performance evaluation. Extensive quantitative metrics demonstrate high reconstruction fidelity on synthetic datasets, while experiments on real indoor and outdoor measurements further confirm the robustness of the proposed approach. Moreover, the SPAD sensor is interfaced with an Arduino UNO Q microcontroller, which receives low-resolution (LR) depth and intensity images and feeds them into a compressed, pre-trained deep learning (DL) model, enabling real-time SR video streaming. In addition to the 256x256 setting, a range of target HR resolutions is evaluated to determine the maximum achievable upscaling resolution (512x512) with LiteSR, including scenarios with noise-corrupted LR inputs. The proposed LiteSR-embedded system co-design provides a scalable, cost-effective solution to enhance the spatial resolution of current consumer-grade SPAD arrays to meet HR imaging requirements.
FPGA Implementation of Sketched LiDAR for a 192 x 128 SPAD Image Sensor
Feb 11, 2026This study presents an efficient field-programmable gate array (FPGA) implementation of a polynomial spline function-based statistical compression algorithm designed to address the critical challenge of massive data transfer bandwidth in emerging high-spatial-resolution single-photon avalanche diode (SPAD) arrays, where data rates can reach tens of gigabytes per second. In our experiments, the proposed hardware implementation achieves a compression ratio of 512x compared with conventional histogram-based outputs, with the potential for further improvement. The algorithm is first optimized in software using fixed-point (FXP) arithmetic and look-up tables (LUTs) to eliminate explicit additions, multiplications, and non-linear operations. This enables a careful balance between accuracy and hardware resource utilization. Guided by this trade-off analysis, online sketch processing elements (SPEs) are implemented on an FPGA to directly process time-stamp streams from the SPAD sensor. The implementation is validated using a customized LiDAR setup with a 192 x 128-pixel SPAD array. This work demonstrates histogram-free online depth reconstruction with high fidelity, effectively alleviating the time-stamp transfer bottleneck of SPAD arrays and offering scalability as pixel counts continue to increase for future SPADs.
Towards On-Device Learning and Reconfigurable Hardware Implementation for Encoded Single-Photon Signal Processing
Apr 12, 2025



Deep neural networks (DNNs) enhance the accuracy and efficiency of reconstructing key parameters from time-resolved photon arrival signals recorded by single-photon detectors. However, the performance of conventional backpropagation-based DNNs is highly dependent on various parameters of the optical setup and biological samples under examination, necessitating frequent network retraining, either through transfer learning or from scratch. Newly collected data must also be stored and transferred to a high-performance GPU server for retraining, introducing latency and storage overhead. To address these challenges, we propose an online training algorithm based on a One-Sided Jacobi rotation-based Online Sequential Extreme Learning Machine (OSOS-ELM). We fully exploit parallelism in executing OSOS-ELM on a heterogeneous FPGA with integrated ARM cores. Extensive evaluations of OSOS-ELM and OSELM demonstrate that both achieve comparable accuracy across different network dimensions (i.e., input, hidden, and output layers), while OSOS-ELM proves to be more hardware-efficient. By leveraging the parallelism of OSOS-ELM, we implement a holistic computing prototype on a Xilinx ZCU104 FPGA, which integrates a multi-core CPU and programmable logic fabric. We validate our approach through three case studies involving single-photon signal analysis: sensing through fog using commercial single-photon LiDAR, fluorescence lifetime estimation in FLIM, and blood flow index reconstruction in DCS, all utilizing one-dimensional data encoded from photonic signals. From a hardware perspective, we optimize the OSOS-ELM workload by employing multi-tasked processing on ARM CPU cores and pipelined execution on the FPGA's logic fabric. We also implement our OSOS-ELM on the NVIDIA Jetson Xavier NX GPU to comprehensively investigate its computing performance on another type of heterogeneous computing platform.
Spiking Neural Network Enhanced Hand Gesture Recognition Using Low-Cost Single-photon Avalanche Diode Array
Feb 08, 2024We present a compact spiking convolutional neural network (SCNN) and spiking multilayer perceptron (SMLP) to recognize ten different gestures in dark and bright light environments, using a $9.6 single-photon avalanche diode (SPAD) array. In our hand gesture recognition (HGR) system, photon intensity data was leveraged to train and test the network. A vanilla convolutional neural network (CNN) was also implemented to compare the performance of SCNN with the same network topologies and training strategies. Our SCNN was trained from scratch instead of being converted from the CNN. We tested the three models in dark and ambient light (AL)-corrupted environments. The results indicate that SCNN achieves comparable accuracy (90.8%) to CNN (92.9%) and exhibits lower floating operations with only 8 timesteps. SMLP also presents a trade-off between computational workload and accuracy. The code and collected datasets of this work are available at https://github.com/zzy666666zzy/TinyLiDAR_NET_SNN.
Fast Cerebral Blood Flow Analysis via Extreme Learning Machine
Feb 01, 2024We introduce a rapid and precise analytical approach for analyzing cerebral blood flow (CBF) using Diffuse Correlation Spectroscopy (DCS) with the application of the Extreme Learning Machine (ELM). Our evaluation of ELM and existing algorithms involves a comprehensive set of metrics. We assess these algorithms using synthetic datasets for both semi-infinite and multi-layer models. The results demonstrate that ELM consistently achieves higher fidelity across various noise levels and optical parameters, showcasing robust generalization ability and outperforming iterative fitting algorithms. Through a comparison with a computationally efficient neural network, ELM attains comparable accuracy with reduced training and inference times. Notably, the absence of a back-propagation process in ELM during training results in significantly faster training speeds compared to existing neural network approaches. This proposed strategy holds promise for edge computing applications with online training capabilities.
Compact and Robust Deep Learning Architecture for Fluorescence Lifetime Imaging and FPGA Implementation
Sep 09, 2022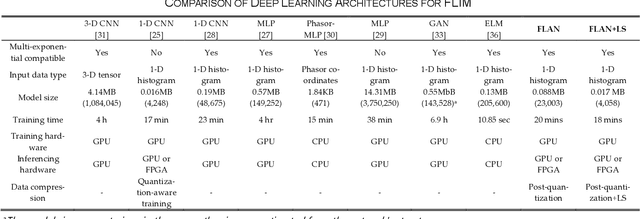
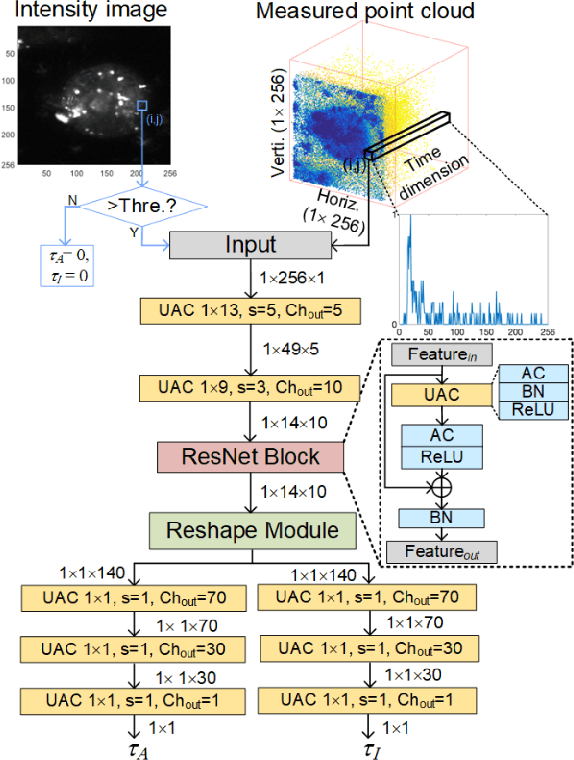
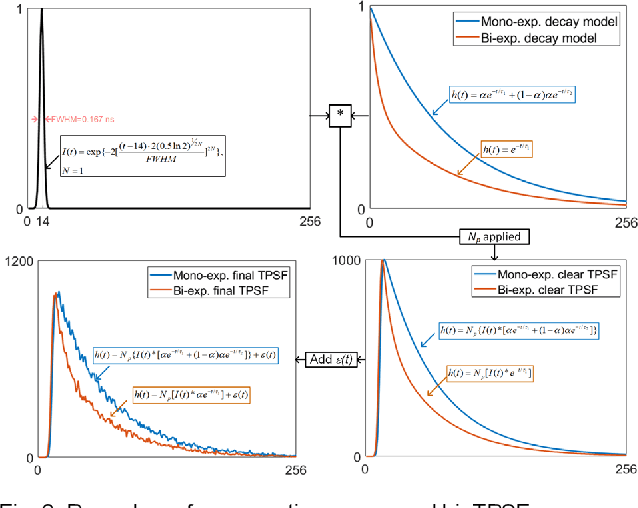
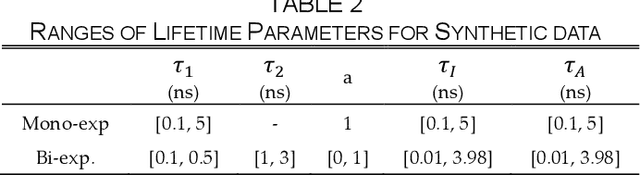
This paper reported a bespoke adder-based deep learning network for time-domain fluorescence lifetime imaging (FLIM). By leveraging the l1-norm extraction method, we propose a 1-D Fluorescence Lifetime AdderNet (FLAN) without multiplication-based convolutions to reduce the computational complexity. Further, we compressed fluorescence decays in temporal dimension using a log-scale merging technique to discard redundant temporal information derived as log-scaling FLAN (FLAN+LS). FLAN+LS achieves 0.11 and 0.23 compression ratios compared with FLAN and a conventional 1-D convolutional neural network (1-D CNN) while maintaining high accuracy in retrieving lifetimes. We extensively evaluated FLAN and FLAN+LS using synthetic and real data. A traditional fitting method and other non-fitting, high-accuracy algorithms were compared with our networks for synthetic data. Our networks attained a minor reconstruction error in different photon-count scenarios. For real data, we used fluorescent beads' data acquired by a confocal microscope to validate the effectiveness of real fluorophores, and our networks can differentiate beads with different lifetimes. Additionally, we implemented the network architecture on a field-programmable gate array (FPGA) with a post-quantization technique to shorten the bit-width, thereby improving computing efficiency. FLAN+LS on hardware achieves the highest computing efficiency compared to 1-D CNN and FLAN. We also discussed the applicability of our network and hardware architecture for other time-resolved biomedical applications using photon-efficient, time-resolved sensors.
Fast fluorescence lifetime imaging analysis via extreme learning machine
Mar 25, 2022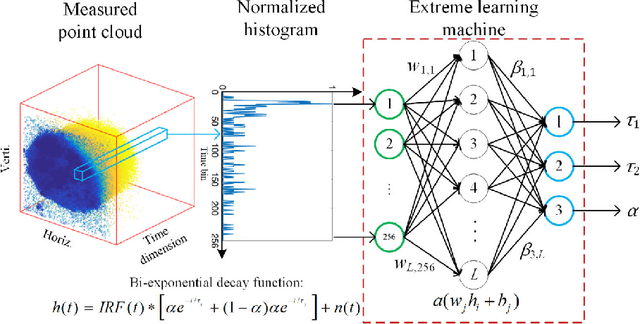

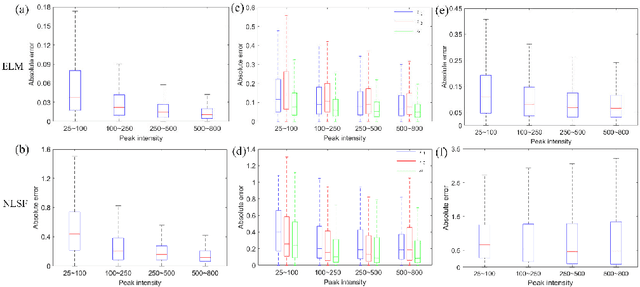
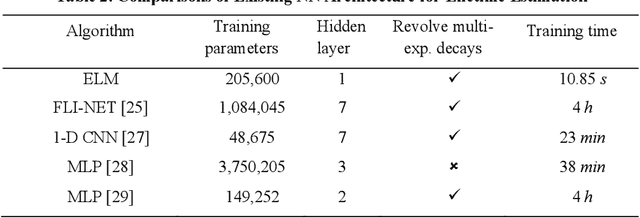
We present a fast and accurate analytical method for fluorescence lifetime imaging microscopy (FLIM) using the extreme learning machine (ELM). We used extensive metrics to evaluate ELM and existing algorithms. First, we compared these algorithms using synthetic datasets. Results indicate that ELM can obtain higher fidelity, even in low-photon conditions. Afterwards, we used ELM to retrieve lifetime components from human prostate cancer cells loaded with gold nanosensors, showing that ELM also outperforms the iterative fitting and non-fitting algorithms. By comparing ELM with a computational efficient neural network, ELM achieves comparable accuracy with less training and inference time. As there is no back-propagation process for ELM during the training phase, the training speed is much higher than existing neural network approaches. The proposed strategy is promising for edge computing with online training.