 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Richardson-Lucy Deconvolution for Low-Light Image Deblurring
Aug 10, 2023

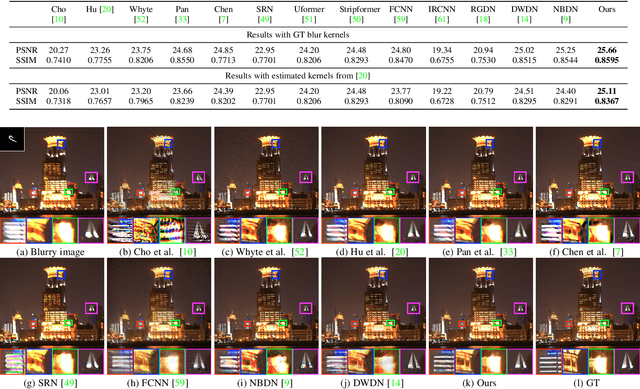

Images taken under the low-light condition often contain blur and saturated pixels at the same time. Deblurring images with saturated pixels is quite challenging. Because of the limited dynamic range, the saturated pixels are usually clipped in the imaging process and thus cannot be modeled by the linear blur model. Previous methods use manually designed smooth functions to approximate the clipping procedure. Their deblurring processes often require empirically defined parameters, which may not be the optimal choices for different images. In this paper, we develop a data-driven approach to model the saturated pixels by a learned latent map. Based on the new model, the non-blind deblurring task can be formulated into a maximum a posterior (MAP) problem, which can be effectively solved by iteratively computing the latent map and the latent image. Specifically, the latent map is computed by learning from a map estimation network (MEN), and the latent image estimation process is implemented by a Richardson-Lucy (RL)-based updating scheme. To estimate high-quality deblurred images without amplified artifacts, we develop a prior estimation network (PEN) to obtain prior information, which is further integrated into the RL scheme. Experimental results demonstrate that the proposed method performs favorably against state-of-the-art algorithms both quantitatively and qualitatively on synthetic and real-world images.
Pareto Multi-Task Learning
Dec 30, 2019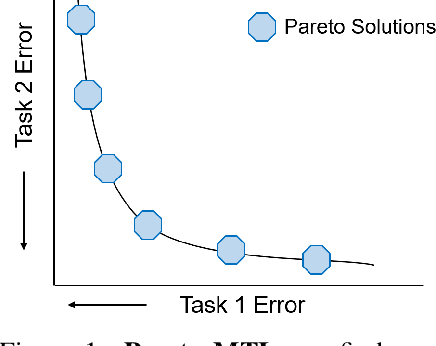
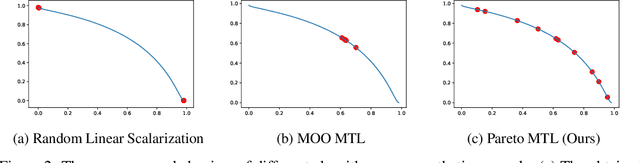
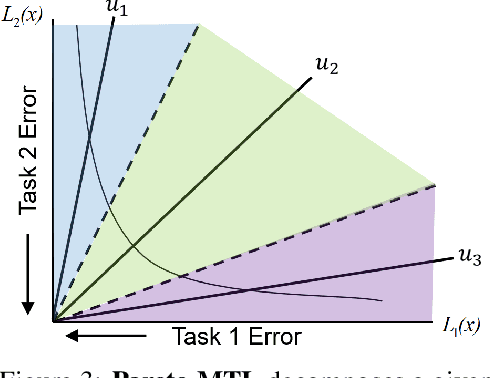
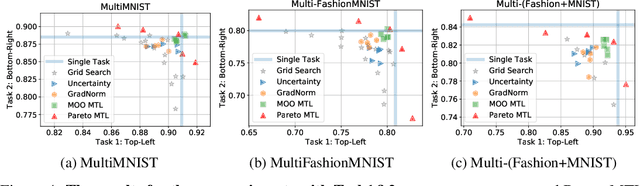
Multi-task learning is a powerful method for solving multiple correlated tasks simultaneously. However, it is often impossible to find one single solution to optimize all the tasks, since different tasks might conflict with each other. Recently, a novel method is proposed to find one single Pareto optimal solution with good trade-off among different tasks by casting multi-task learning as multiobjective optimization. In this paper, we generalize this idea and propose a novel Pareto multi-task learning algorithm (Pareto MTL) to find a set of well-distributed Pareto solutions which can represent different trade-offs among different tasks. The proposed algorithm first formulates a multi-task learning problem as a multiobjective optimization problem, and then decomposes the multiobjective optimization problem into a set of constrained subproblems with different trade-off preferences. By solving these subproblems in parallel, Pareto MTL can find a set of well-representative Pareto optimal solutions with different trade-off among all tasks. Practitioners can easily select their preferred solution from these Pareto solutions, or use different trade-off solutions for different situations. Experimental results confirm that the proposed algorithm can generate well-representative solutions and outperform some state-of-the-art algorithms on many multi-task learning applications.
A Batched Scalable Multi-Objective Bayesian Optimization Algorithm
Nov 04, 2018



The surrogate-assisted optimization algorithm is a promising approach for solving expensive multi-objective optimization problems. However, most existing surrogate-assisted multi-objective optimization algorithms have three main drawbacks: 1) cannot scale well for solving problems with high dimensional decision space, 2) cannot incorporate available gradient information, and 3) do not support batch optimization. These drawbacks prevent their use for solving many real-world large scale optimization problems. This paper proposes a batched scalable multi-objective Bayesian optimization algorithm to tackle these issues. The proposed algorithm uses the Bayesian neural network as the scalable surrogate model. Powered with Monte Carlo dropout and Sobolov training, the model can be easily trained and can incorporate available gradient information. We also propose a novel batch hypervolume upper confidence bound acquisition function to support batch optimization. Experimental results on various benchmark problems and a real-world application demonstrate the efficiency of the proposed algorithm.
Nonlinear Collaborative Scheme for Deep Neural Networks
Nov 04, 2018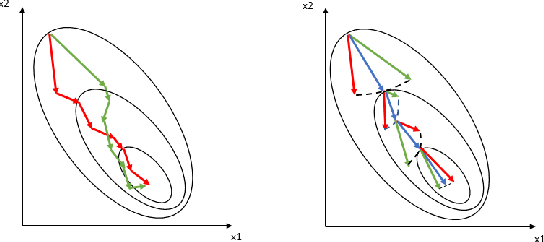
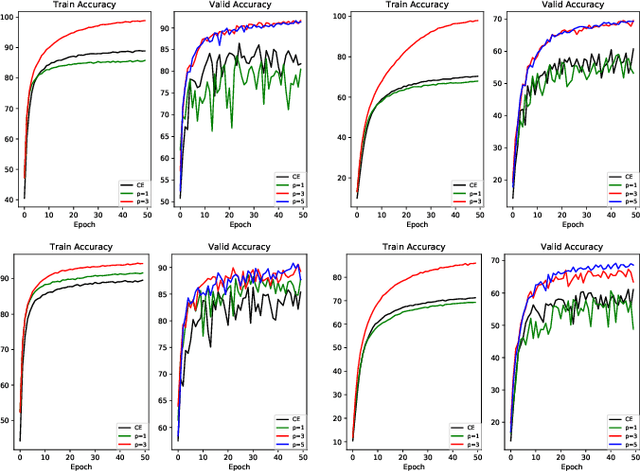
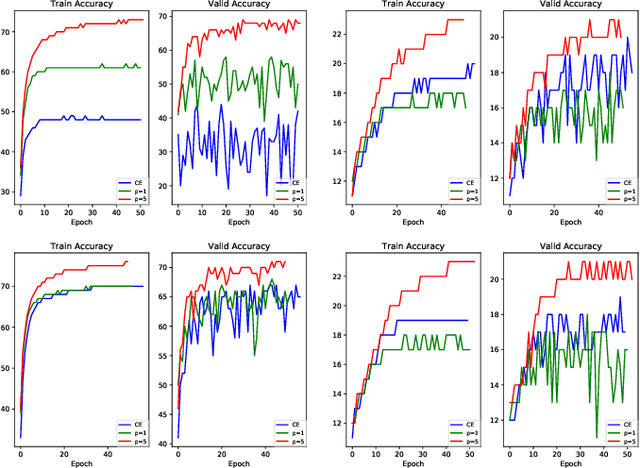
Conventional research attributes the improvements of generalization ability of deep neural networks either to powerful optimizers or the new network design. Different from them, in this paper, we aim to link the generalization ability of a deep network to optimizing a new objective function. To this end, we propose a \textit{nonlinear collaborative scheme} for deep network training, with the key technique as combining different loss functions in a nonlinear manner. We find that after adaptively tuning the weights of different loss functions, the proposed objective function can efficiently guide the optimization process. What is more, we demonstrate that, from the mathematical perspective, the nonlinear collaborative scheme can lead to (i) smaller KL divergence with respect to optimal solutions; (ii) data-driven stochastic gradient descent; (iii) tighter PAC-Bayes bound. We also prove that its advantage can be strengthened by nonlinearity increasing. To some extent, we bridge the gap between learning (i.e., minimizing the new objective function) and generalization (i.e., minimizing a PAC-Bayes bound) in the new scheme. We also interpret our findings through the experiments on Residual Networks and DenseNet, showing that our new scheme performs superior to single-loss and multi-loss schemes no matter with randomization or not.
A Simple Yet Efficient Rank One Update for Covariance Matrix Adaptation
Oct 22, 2017
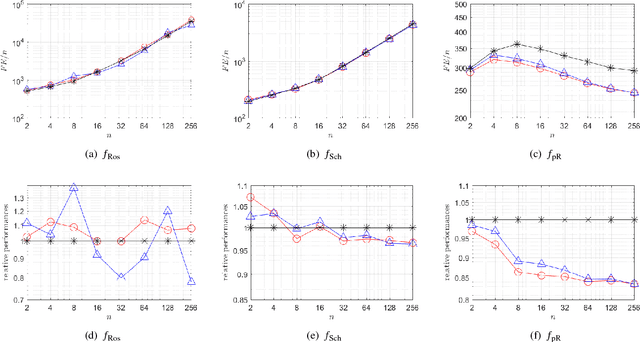


In this paper, we propose an efficient approximated rank one update for covariance matrix adaptation evolution strategy (CMA-ES). It makes use of two evolution paths as simple as that of CMA-ES, while avoiding the computational matrix decomposition. We analyze the algorithms' properties and behaviors. We experimentally study the proposed algorithm's performances. It generally outperforms or performs competitively to the Cholesky CMA-ES.