 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNonlinear Collaborative Scheme for Deep Neural Networks
Paper and Code
Nov 04, 2018
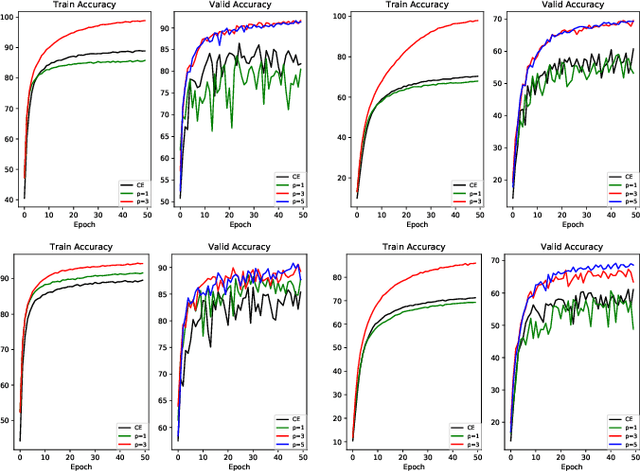
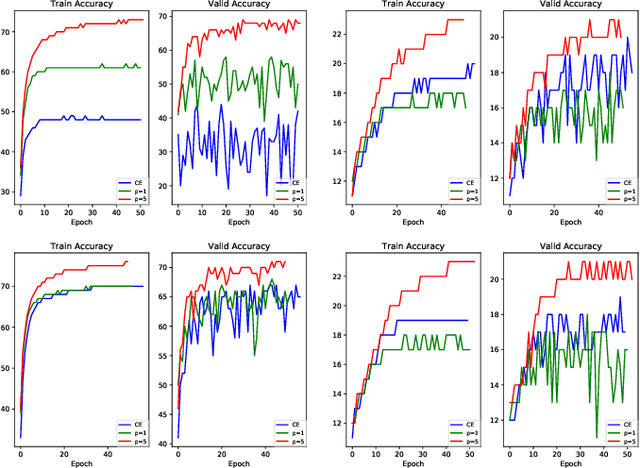
Conventional research attributes the improvements of generalization ability of deep neural networks either to powerful optimizers or the new network design. Different from them, in this paper, we aim to link the generalization ability of a deep network to optimizing a new objective function. To this end, we propose a \textit{nonlinear collaborative scheme} for deep network training, with the key technique as combining different loss functions in a nonlinear manner. We find that after adaptively tuning the weights of different loss functions, the proposed objective function can efficiently guide the optimization process. What is more, we demonstrate that, from the mathematical perspective, the nonlinear collaborative scheme can lead to (i) smaller KL divergence with respect to optimal solutions; (ii) data-driven stochastic gradient descent; (iii) tighter PAC-Bayes bound. We also prove that its advantage can be strengthened by nonlinearity increasing. To some extent, we bridge the gap between learning (i.e., minimizing the new objective function) and generalization (i.e., minimizing a PAC-Bayes bound) in the new scheme. We also interpret our findings through the experiments on Residual Networks and DenseNet, showing that our new scheme performs superior to single-loss and multi-loss schemes no matter with randomization or not.