 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-recovery of memory via generative replay
Jan 15, 2023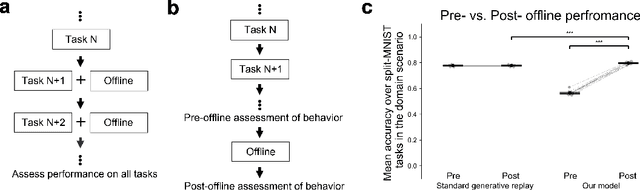
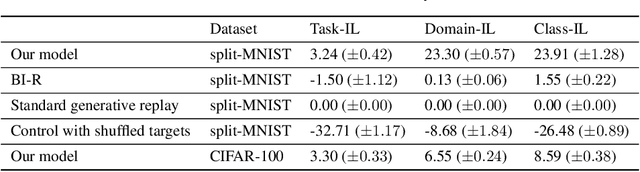
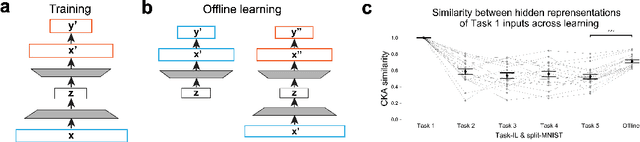
A remarkable capacity of the brain is its ability to autonomously reorganize memories during offline periods. Memory replay, a mechanism hypothesized to underlie biological offline learning, has inspired offline methods for reducing forgetting in artificial neural networks in continual learning settings. A memory-efficient and neurally-plausible method is generative replay, which achieves state of the art performance on continual learning benchmarks. However, unlike the brain, standard generative replay does not self-reorganize memories when trained offline on its own replay samples. We propose a novel architecture that augments generative replay with an adaptive, brain-like capacity to autonomously recover memories. We demonstrate this capacity of the architecture across several continual learning tasks and environments.
Multi-View Photometric Stereo: A Robust Solution and Benchmark Dataset for Spatially Varying Isotropic Materials
Jan 18, 2020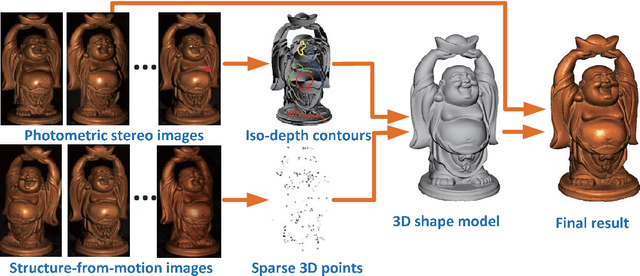

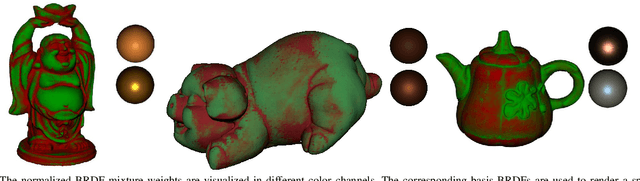
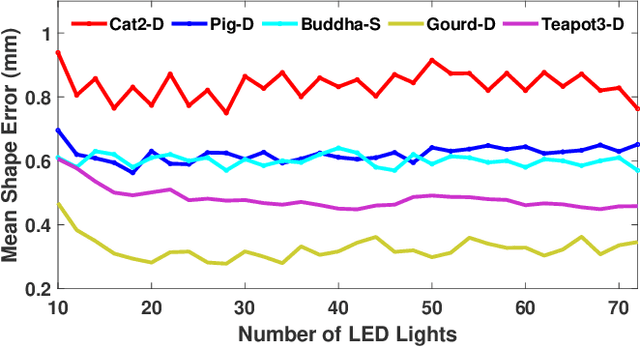
We present a method to capture both 3D shape and spatially varying reflectance with a multi-view photometric stereo (MVPS) technique that works for general isotropic materials. Our algorithm is suitable for perspective cameras and nearby point light sources. Our data capture setup is simple, which consists of only a digital camera, some LED lights, and an optional automatic turntable. From a single viewpoint, we use a set of photometric stereo images to identify surface points with the same distance to the camera. We collect this information from multiple viewpoints and combine it with structure-from-motion to obtain a precise reconstruction of the complete 3D shape. The spatially varying isotropic bidirectional reflectance distribution function (BRDF) is captured by simultaneously inferring a set of basis BRDFs and their mixing weights at each surface point. In experiments, we demonstrate our algorithm with two different setups: a studio setup for highest precision and a desktop setup for best usability. According to our experiments, under the studio setting, the captured shapes are accurate to 0.5 millimeters and the captured reflectance has a relative root-mean-square error (RMSE) of 9%. We also quantitatively evaluate state-of-the-art MVPS on a newly collected benchmark dataset, which is publicly available for inspiring future research.
Taking a machine's perspective: Human deciphering of adversarial images
Sep 11, 2018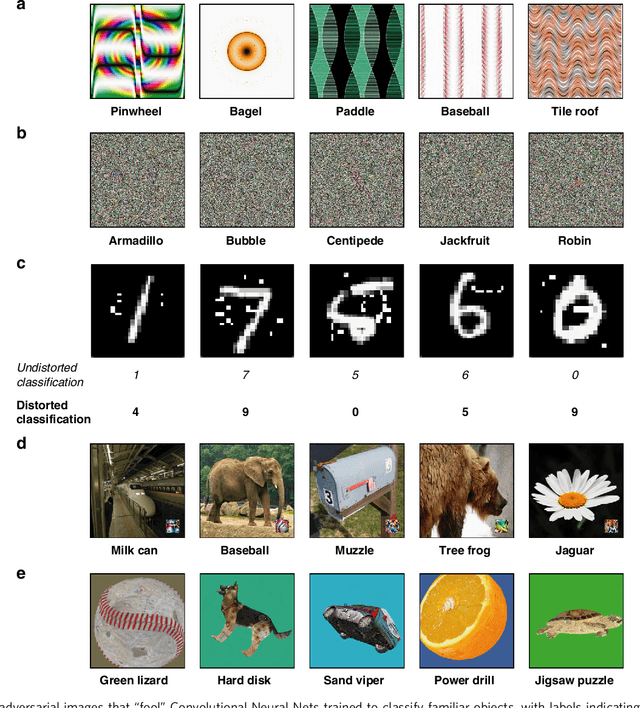
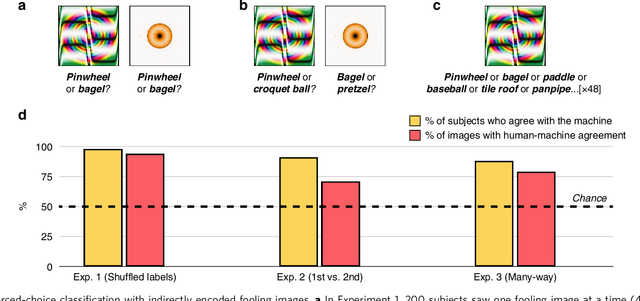
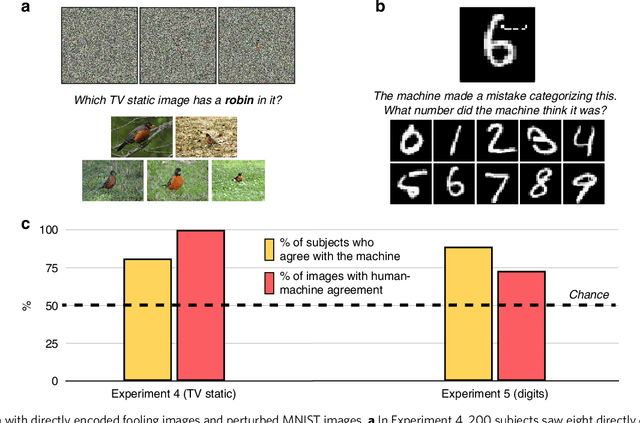
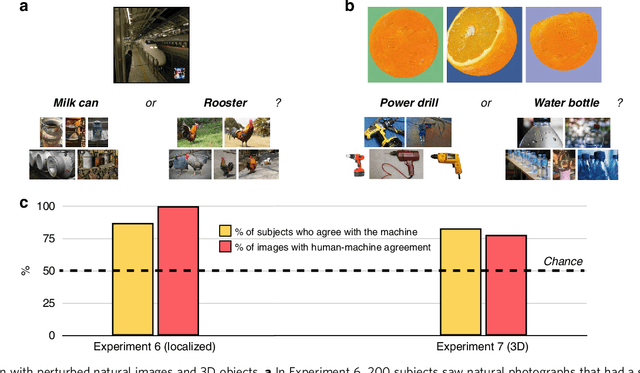
How similar is the human mind to the sophisticated machine-learning systems that mirror its performance? Models of object categorization based on convolutional neural networks (CNNs) have achieved human-level benchmarks in assigning known labels to novel images. These advances support transformative technologies such as autonomous vehicles and machine diagnosis; beyond this, they also serve as candidate models for the visual system itself -- not only in their output but perhaps even in their underlying mechanisms and principles. However, unlike human vision, CNNs can be "fooled" by adversarial examples -- carefully crafted images that appear as nonsense patterns to humans but are recognized as familiar objects by machines, or that appear as one object to humans and a different object to machines. This seemingly extreme divergence between human and machine classification challenges the promise of these new advances, both as applied image-recognition systems and also as models of the human mind. Surprisingly, however, little work has empirically investigated human classification of such adversarial stimuli: Does human and machine performance fundamentally diverge? Or could humans decipher such images and predict the machine's preferred labels? Here, we show that human and machine classification of adversarial stimuli are robustly related: In seven experiments on five prominent and diverse adversarial imagesets, human subjects reliably identified the machine's chosen label over relevant foils. This pattern persisted for images with strong antecedent identities, and even for images described as "totally unrecognizable to human eyes". We suggest that human intuition may be a more reliable guide to machine (mis)classification than has typically been imagined, and we explore the consequences of this result for minds and machines alike.