 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComparing Human and Machine Deepfake Detection with Affective and Holistic Processing
May 13, 2021
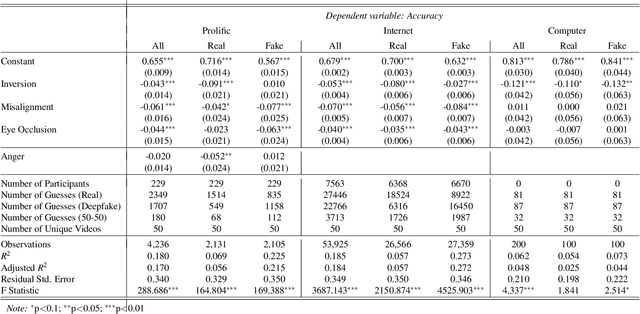
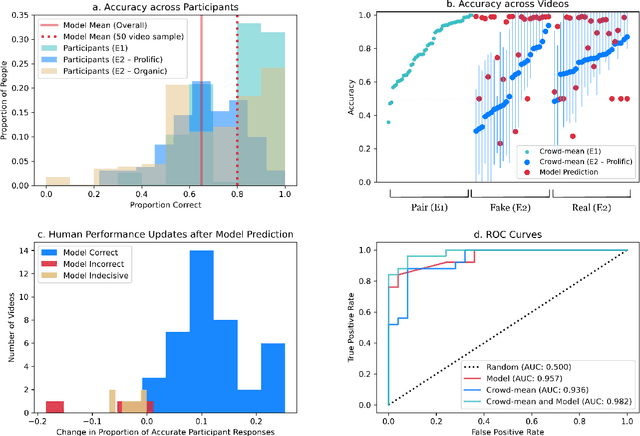

The recent emergence of deepfake videos leads to an important societal question: how can we know if a video that we watch is real or fake? In three online studies with 15,016 participants, we present authentic videos and deepfakes and ask participants to identify which is which. We compare the performance of ordinary participants against the leading computer vision deepfake detection model and find them similarly accurate while making different kinds of mistakes. Together, participants with access to the model's prediction are more accurate than either alone, but inaccurate model predictions often decrease participants' accuracy. We embed randomized experiments and find: incidental anger decreases participants' performance and obstructing holistic visual processing of faces also hinders participants' performance while mostly not affecting the model's. These results suggest that considering emotional influences and harnessing specialized, holistic visual processing of ordinary people could be promising defenses against machine-manipulated media.
Can you hear me $\textit{now}$? Sensitive comparisons of human and machine perception
Mar 27, 2020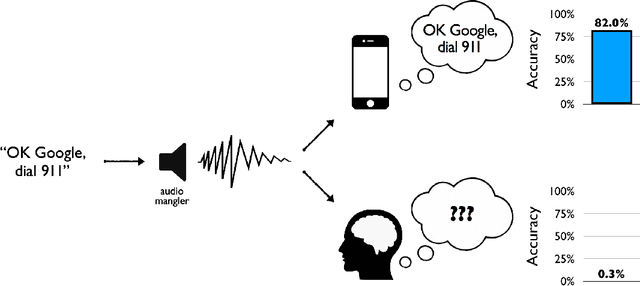
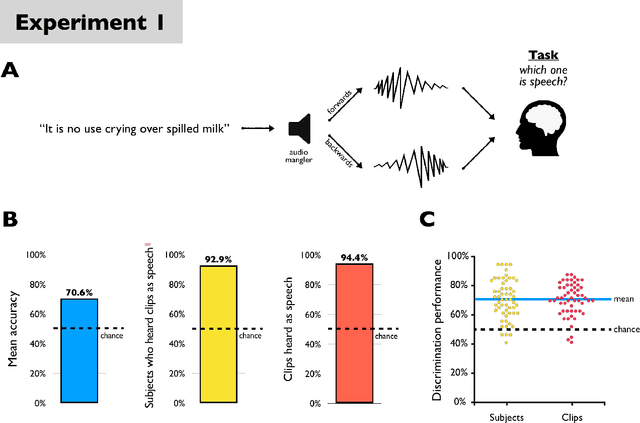
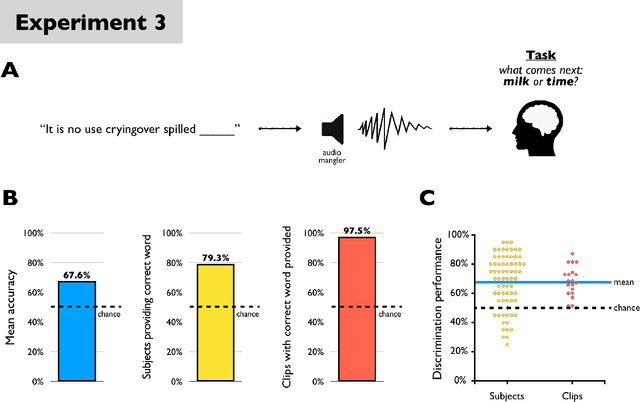
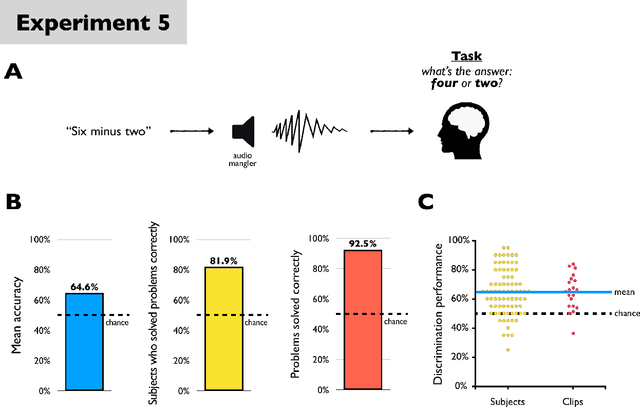
The rise of sophisticated machine-recognition systems has brought with it a rise in comparisons between human and machine perception. But such comparisons face an asymmetry: Whereas machine perception of some stimulus can often be probed through direct and explicit measures, much of human perceptual knowledge is latent, incomplete, or embedded in unconscious mental processes that may not be available for explicit report. Here, we show how this asymmetry can cause such comparisons to underestimate the overlap in human and machine perception. As a case study, we consider human perception of $\textit{adversarial speech}$ -- synthetic audio commands that are recognized as valid messages by automated speech-recognition systems but that human listeners reportedly hear as meaningless noise. In five experiments, we adapt task designs from the human psychophysics literature to show that even when subjects cannot freely transcribe adversarial speech (the previous benchmark for human understanding), they nevertheless $\textit{can}$ discriminate adversarial speech from closely matched non-speech (Experiments 1-2), finish common phrases begun in adversarial speech (Experiments 3-4), and solve simple math problems posed in adversarial speech (Experiment 5) -- even for stimuli previously described as "unintelligible to human listeners". We recommend the adoption of $\textit{sensitive tests}$ of human and machine perception, and discuss the broader consequences of this approach for comparing natural and artificial intelligence.
Taking a machine's perspective: Human deciphering of adversarial images
Sep 11, 2018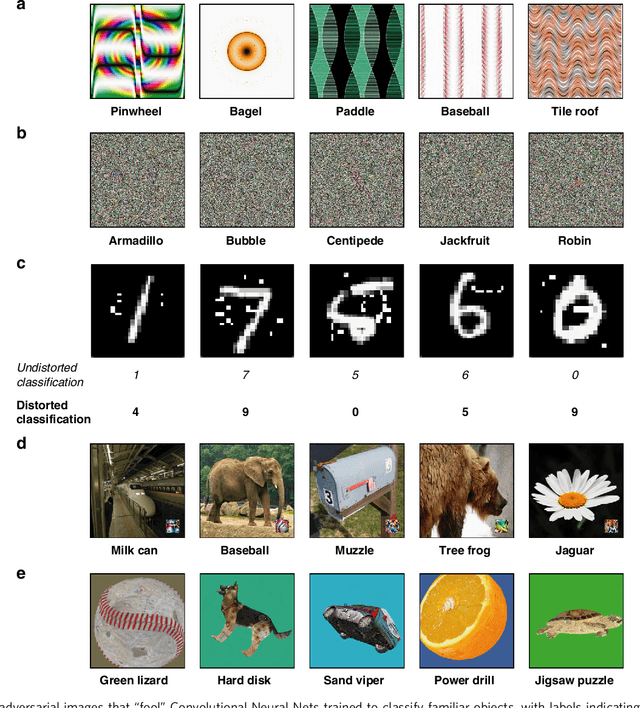
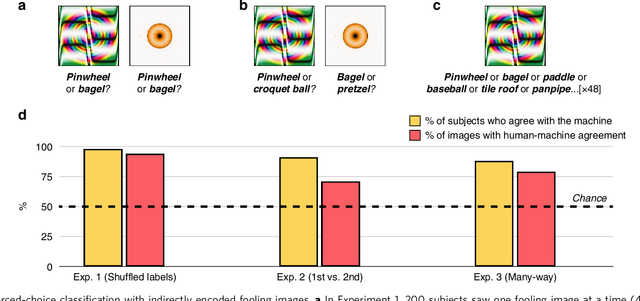
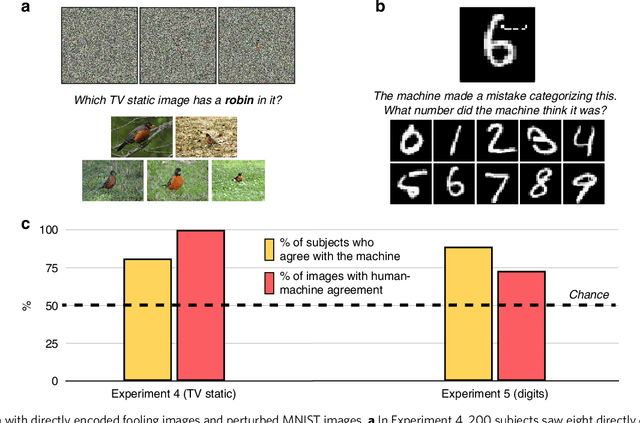
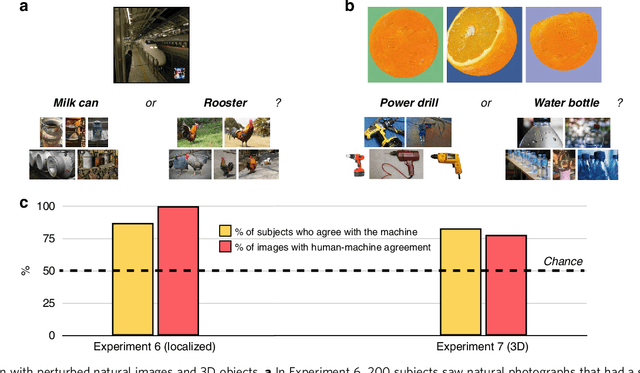
How similar is the human mind to the sophisticated machine-learning systems that mirror its performance? Models of object categorization based on convolutional neural networks (CNNs) have achieved human-level benchmarks in assigning known labels to novel images. These advances support transformative technologies such as autonomous vehicles and machine diagnosis; beyond this, they also serve as candidate models for the visual system itself -- not only in their output but perhaps even in their underlying mechanisms and principles. However, unlike human vision, CNNs can be "fooled" by adversarial examples -- carefully crafted images that appear as nonsense patterns to humans but are recognized as familiar objects by machines, or that appear as one object to humans and a different object to machines. This seemingly extreme divergence between human and machine classification challenges the promise of these new advances, both as applied image-recognition systems and also as models of the human mind. Surprisingly, however, little work has empirically investigated human classification of such adversarial stimuli: Does human and machine performance fundamentally diverge? Or could humans decipher such images and predict the machine's preferred labels? Here, we show that human and machine classification of adversarial stimuli are robustly related: In seven experiments on five prominent and diverse adversarial imagesets, human subjects reliably identified the machine's chosen label over relevant foils. This pattern persisted for images with strong antecedent identities, and even for images described as "totally unrecognizable to human eyes". We suggest that human intuition may be a more reliable guide to machine (mis)classification than has typically been imagined, and we explore the consequences of this result for minds and machines alike.