 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Bandits Model to Deep Deterministic Policy Gradient, Reinforcement Learning with Contextual Information
Oct 01, 2023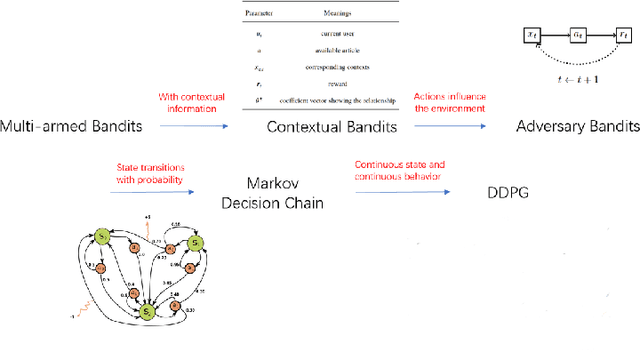
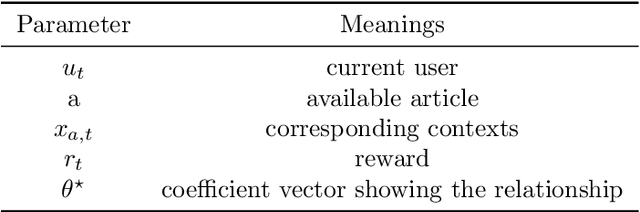
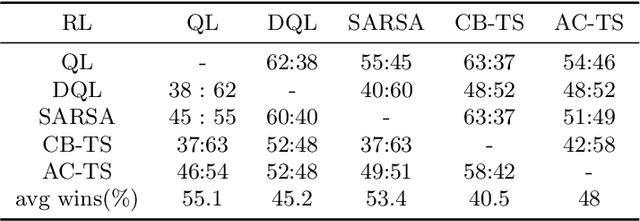
The problem of how to take the right actions to make profits in sequential process continues to be difficult due to the quick dynamics and a significant amount of uncertainty in many application scenarios. In such complicated environments, reinforcement learning (RL), a reward-oriented strategy for optimum control, has emerged as a potential technique to address this strategic decision-making issue. However, reinforcement learning also has some shortcomings that make it unsuitable for solving many financial problems, excessive resource consumption, and inability to quickly obtain optimal solutions, making it unsuitable for quantitative trading markets. In this study, we use two methods to overcome the issue with contextual information: contextual Thompson sampling and reinforcement learning under supervision which can accelerate the iterations in search of the best answer. In order to investigate strategic trading in quantitative markets, we merged the earlier financial trading strategy known as constant proportion portfolio insurance (CPPI) into deep deterministic policy gradient (DDPG). The experimental results show that both methods can accelerate the progress of reinforcement learning to obtain the optimal solution.
Strategic Trading in Quantitative Markets through Multi-Agent Reinforcement Learning
Mar 15, 2023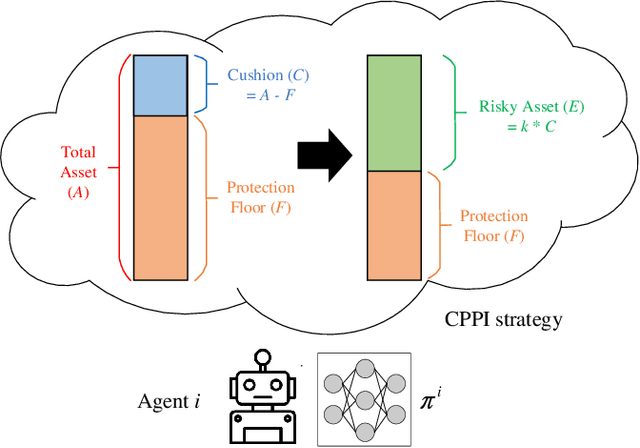
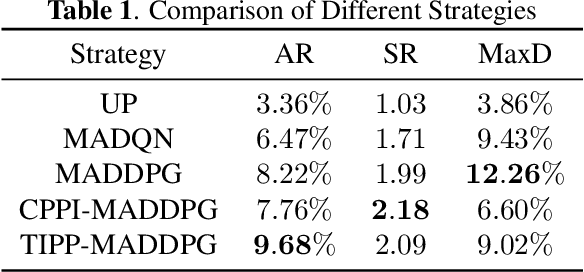
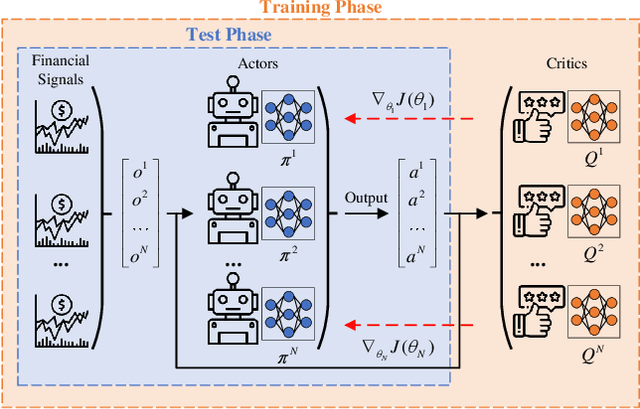

Due to the rapid dynamics and a mass of uncertainties in the quantitative markets, the issue of how to take appropriate actions to make profits in stock trading remains a challenging one. Reinforcement learning (RL), as a reward-oriented approach for optimal control, has emerged as a promising method to tackle this strategic decision-making problem in such a complex financial scenario. In this paper, we integrated two prior financial trading strategies named constant proportion portfolio insurance (CPPI) and time-invariant portfolio protection (TIPP) into multi-agent deep deterministic policy gradient (MADDPG) and proposed two specifically designed multi-agent RL (MARL) methods: CPPI-MADDPG and TIPP-MADDPG for investigating strategic trading in quantitative markets. Afterward, we selected 100 different shares in the real financial market to test these specifically proposed approaches. The experiment results show that CPPI-MADDPG and TIPP-MADDPG approaches generally outperform the conventional ones.
Thompson Sampling on Asymmetric $α$-Stable Bandits
Mar 25, 2022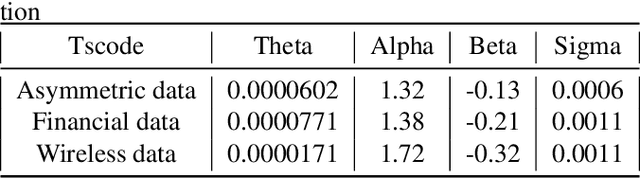
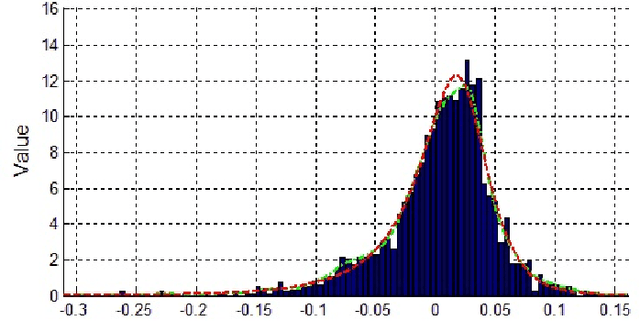
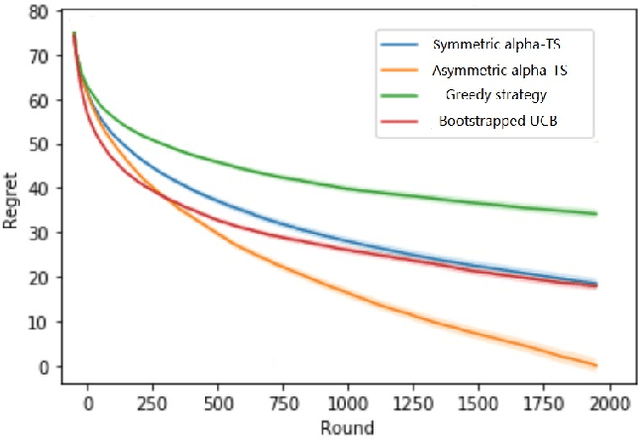
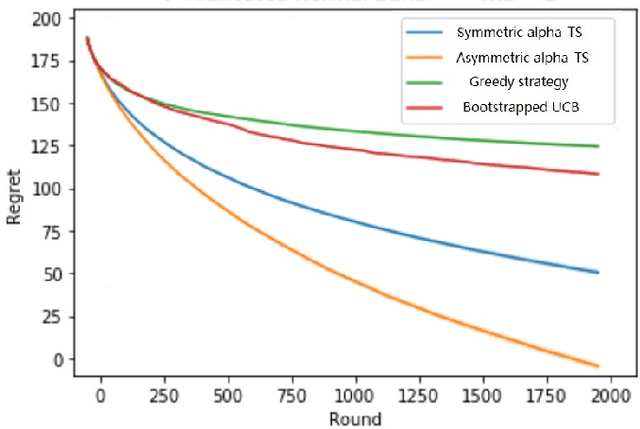
In algorithm optimization in reinforcement learning, how to deal with the exploration-exploitation dilemma is particularly important. Multi-armed bandit problem can optimize the proposed solutions by changing the reward distribution to realize the dynamic balance between exploration and exploitation. Thompson Sampling is a common method for solving multi-armed bandit problem and has been used to explore data that conform to various laws. In this paper, we consider the Thompson Sampling approach for multi-armed bandit problem, in which rewards conform to unknown asymmetric $\alpha$-stable distributions and explore their applications in modelling financial and wireless data.