 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnalyzing and Overcoming Local Optima in Complex Multi-Objective Optimization by Decomposition-Based Evolutionary Algorithms
Apr 12, 2024



When addressing the challenge of complex multi-objective optimization problems, particularly those with non-convex and non-uniform Pareto fronts, Decomposition-based Multi-Objective Evolutionary Algorithms (MOEADs) often converge to local optima, thereby limiting solution diversity. Despite its significance, this issue has received limited theoretical exploration. Through a comprehensive geometric analysis, we identify that the traditional method of Reference Point (RP) selection fundamentally contributes to this challenge. In response, we introduce an innovative RP selection strategy, the Weight Vector-Guided and Gaussian-Hybrid method, designed to overcome the local optima issue. This approach employs a novel RP type that aligns with weight vector directions and integrates a Gaussian distribution to combine three distinct RP categories. Our research comprises two main experimental components: an ablation study involving 14 algorithms within the MOEADs framework, spanning from 2014 to 2022, to validate our theoretical framework, and a series of empirical tests to evaluate the effectiveness of our proposed method against both traditional and cutting-edge alternatives. Results demonstrate that our method achieves remarkable improvements in both population diversity and convergence.
Cooperative Multi-Type Multi-Agent Deep Reinforcement Learning for Resource Management in Space-Air-Ground Integrated Networks
Aug 08, 2023The Space-Air-Ground Integrated Network (SAGIN), integrating heterogeneous devices including low earth orbit (LEO) satellites, unmanned aerial vehicles (UAVs), and ground users (GUs), holds significant promise for advancing smart city applications. However, resource management of the SAGIN is a challenge requiring urgent study in that inappropriate resource management will cause poor data transmission, and hence affect the services in smart cities. In this paper, we develop a comprehensive SAGIN system that encompasses five distinct communication links and propose an efficient cooperative multi-type multi-agent deep reinforcement learning (CMT-MARL) method to address the resource management issue. The experimental results highlight the efficacy of the proposed CMT-MARL, as evidenced by key performance indicators such as the overall transmission rate and transmission success rate. These results underscore the potential value and feasibility of future implementation of the SAGIN.
Strategic Trading in Quantitative Markets through Multi-Agent Reinforcement Learning
Mar 15, 2023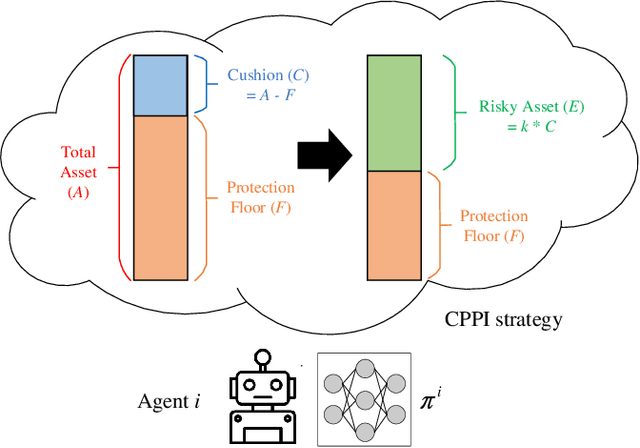
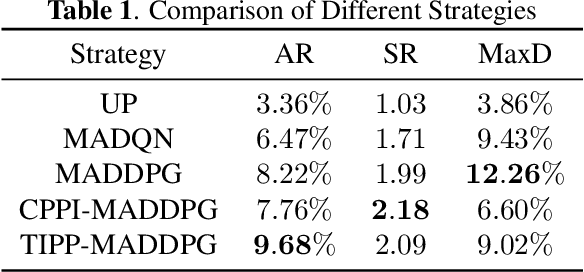
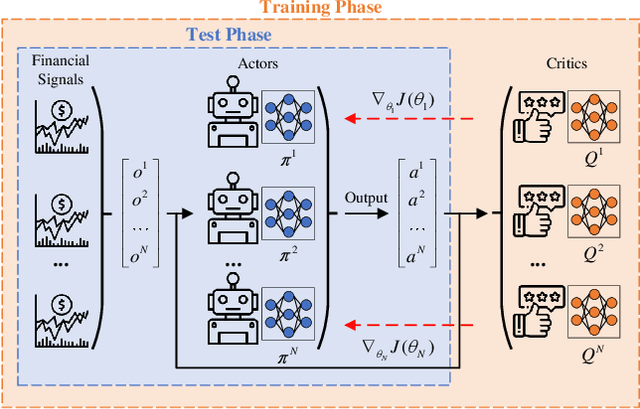

Due to the rapid dynamics and a mass of uncertainties in the quantitative markets, the issue of how to take appropriate actions to make profits in stock trading remains a challenging one. Reinforcement learning (RL), as a reward-oriented approach for optimal control, has emerged as a promising method to tackle this strategic decision-making problem in such a complex financial scenario. In this paper, we integrated two prior financial trading strategies named constant proportion portfolio insurance (CPPI) and time-invariant portfolio protection (TIPP) into multi-agent deep deterministic policy gradient (MADDPG) and proposed two specifically designed multi-agent RL (MARL) methods: CPPI-MADDPG and TIPP-MADDPG for investigating strategic trading in quantitative markets. Afterward, we selected 100 different shares in the real financial market to test these specifically proposed approaches. The experiment results show that CPPI-MADDPG and TIPP-MADDPG approaches generally outperform the conventional ones.