Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThompson Sampling on Asymmetric $α$-Stable Bandits
Paper and Code
Mar 25, 2022
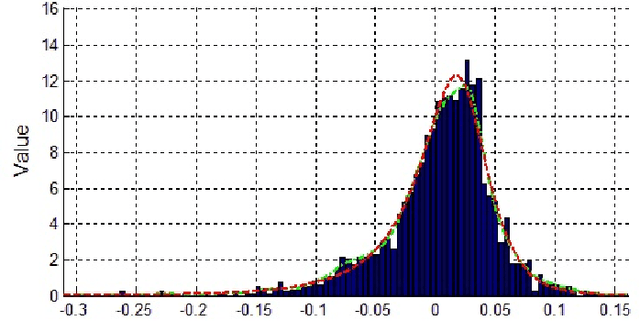
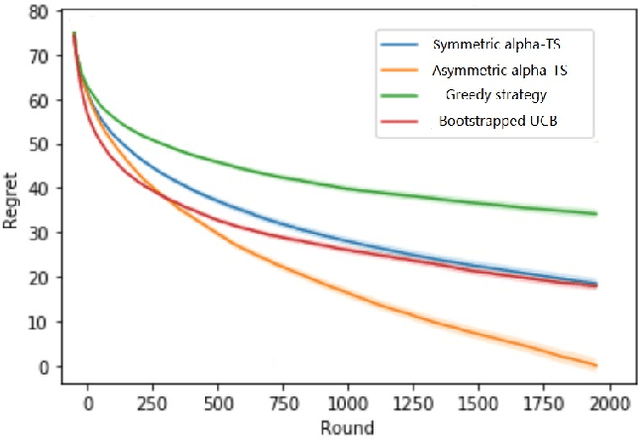
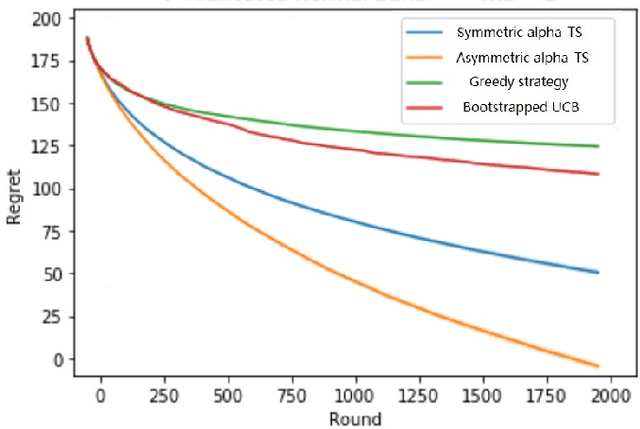
In algorithm optimization in reinforcement learning, how to deal with the exploration-exploitation dilemma is particularly important. Multi-armed bandit problem can optimize the proposed solutions by changing the reward distribution to realize the dynamic balance between exploration and exploitation. Thompson Sampling is a common method for solving multi-armed bandit problem and has been used to explore data that conform to various laws. In this paper, we consider the Thompson Sampling approach for multi-armed bandit problem, in which rewards conform to unknown asymmetric $\alpha$-stable distributions and explore their applications in modelling financial and wireless data.
* 8 pages, 4 figures
View paper on