 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Bandits Model to Deep Deterministic Policy Gradient, Reinforcement Learning with Contextual Information
Paper and Code
Oct 01, 2023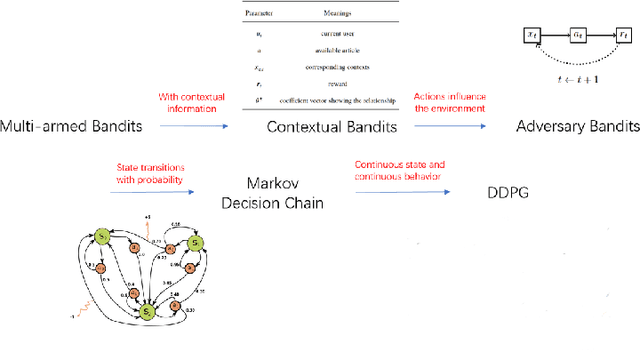
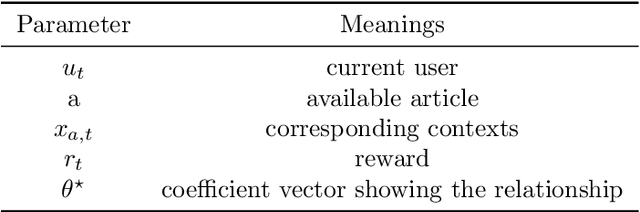
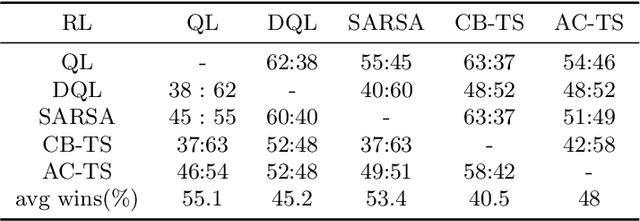
The problem of how to take the right actions to make profits in sequential process continues to be difficult due to the quick dynamics and a significant amount of uncertainty in many application scenarios. In such complicated environments, reinforcement learning (RL), a reward-oriented strategy for optimum control, has emerged as a potential technique to address this strategic decision-making issue. However, reinforcement learning also has some shortcomings that make it unsuitable for solving many financial problems, excessive resource consumption, and inability to quickly obtain optimal solutions, making it unsuitable for quantitative trading markets. In this study, we use two methods to overcome the issue with contextual information: contextual Thompson sampling and reinforcement learning under supervision which can accelerate the iterations in search of the best answer. In order to investigate strategic trading in quantitative markets, we merged the earlier financial trading strategy known as constant proportion portfolio insurance (CPPI) into deep deterministic policy gradient (DDPG). The experimental results show that both methods can accelerate the progress of reinforcement learning to obtain the optimal solution.