 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking and Designing a High-performing Automatic License Plate Recognition Approach
Nov 30, 2020
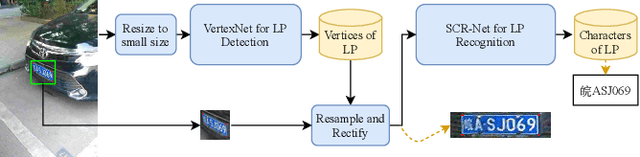
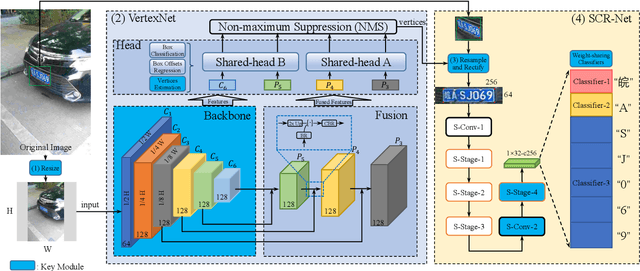
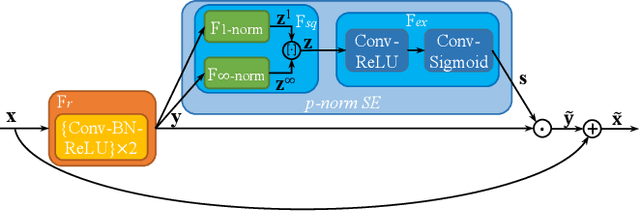
In this paper, we propose a real-time and accurate automatic license plate recognition (ALPR) approach. Our study illustrates the outstanding design of ALPR with four insights: (1) the resampling-based cascaded framework is beneficial to both speed and accuracy; (2) the highly efficient license plate recognition should abundant additional character segmentation and recurrent neural network (RNN), but adopt a plain convolutional neural network (CNN); (3) in the case of CNN, taking advantage of vertex information on license plates improves the recognition performance; and (4) the weight-sharing character classifier addresses the lack of training images in small-scale datasets. Based on these insights, we propose a novel ALPR approach, termed VSNet. Specifically, VSNet includes two CNNs, i.e., VertexNet for license plate detection and SCR-Net for license plate recognition, which is integrated in a resampling-based cascaded manner. In VertexNet, we propose an efficient integration block to extract the spatial features of license plates. With vertex supervisory information, we propose a vertex-estimation branch in VertexNet such that license plates can be rectified as the input images of SCR-Net. Moreover, vertex-based data augmentation is employed to diverse the training samples. In SCR-Net, we propose a horizontal encoding technique for left-to-right feature extraction and a weight-sharing classifier for character recognition. Experimental results show that the proposed VSNet outperforms state-of-the-art methods by more than 50% relative improvement on error rate, achieving >99% recognition accuracy on both CCPD and AOLP datasets with 149 FPS inference speed.
When Residual Learning Meets Dense Aggregation: Rethinking the Aggregation of Deep Neural Networks
Apr 24, 2020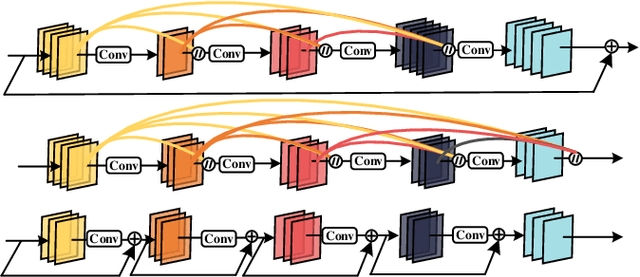

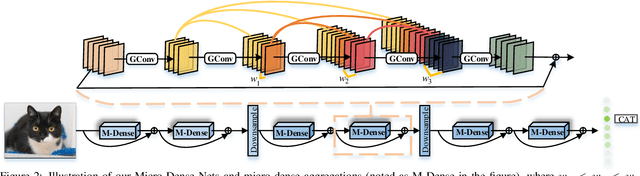
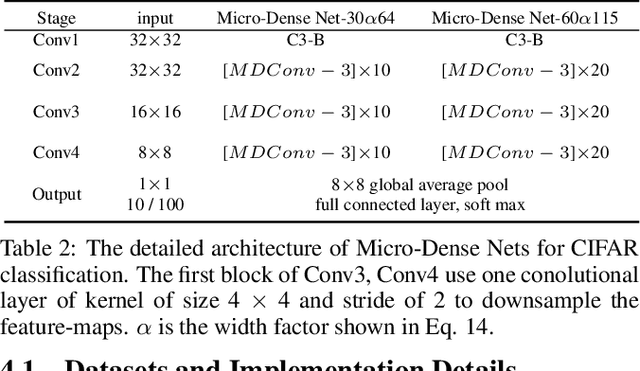
Various architectures (such as GoogLeNets, ResNets, and DenseNets) have been proposed. However, the existing networks usually suffer from either redundancy of convolutional layers or insufficient utilization of parameters. To handle these challenging issues, we propose Micro-Dense Nets, a novel architecture with global residual learning and local micro-dense aggregations. Specifically, residual learning aims to efficiently retrieve features from different convolutional blocks, while the micro-dense aggregation is able to enhance each block and avoid redundancy of convolutional layers by lessening residual aggregations. Moreover, the proposed micro-dense architecture has two characteristics: pyramidal multi-level feature learning which can widen the deeper layer in a block progressively, and dimension cardinality adaptive convolution which can balance each layer using linearly increasing dimension cardinality. The experimental results over three datasets (i.e., CIFAR-10, CIFAR-100, and ImageNet-1K) demonstrate that the proposed Micro-Dense Net with only 4M parameters can achieve higher classification accuracy than state-of-the-art networks, while being 12.1$\times$ smaller depends on the number of parameters. In addition, our micro-dense block can be integrated with neural architecture search based models to boost their performance, validating the advantage of our architecture. We believe our design and findings will be beneficial to the DNN community.
Convolutional Neural Networks with Dynamic Regularization
Sep 26, 2019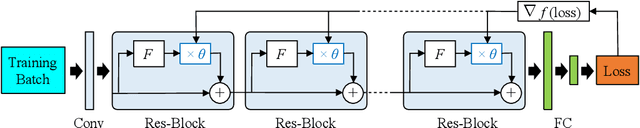
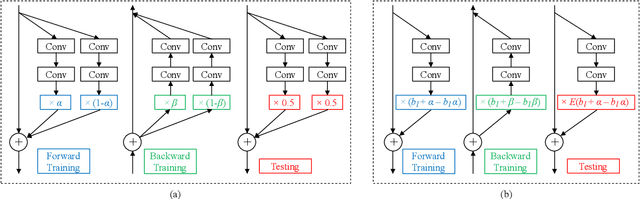
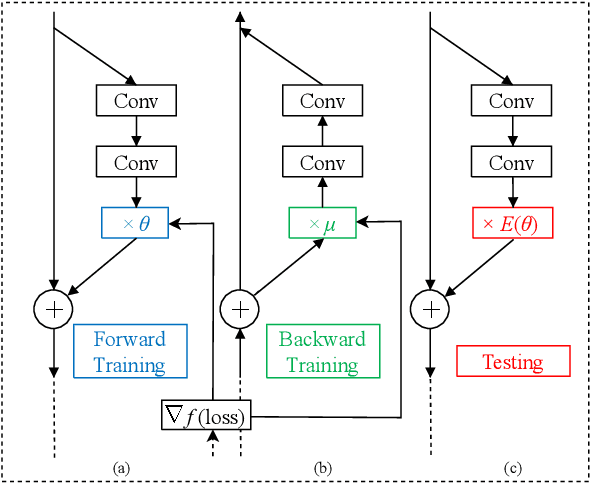
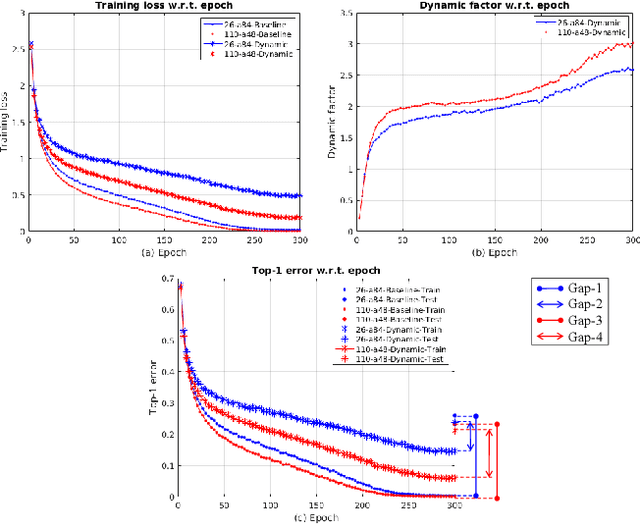
Regularization is commonly used in machine learning for alleviating overfitting. In convolutional neural networks, regularization methods, such as Dropout and Shake-Shake, have been proposed to improve the generalization performance. However, these methods are lack of self-adaption throughout training, i.e., the regularization strength is fixed to a predefined schedule, and manual adjustment has to be performed to adapt to various network architectures. In this paper, we propose a dynamic regularization method which can dynamically adjust the regularization strength in the training procedure. Specifically, we model the regularization strength as a backward difference of the training loss, which can be directly extracted in each training iteration. With dynamic regularization, the large model is regularized by the strong perturbation and vice versa. Experimental results show that the proposed method can improve the generalization capability of off-the-shelf network architectures and outperforms state-of-the-art regularization methods.