 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRepresentation Learning for Wearable-Based Applications in the Case of Missing Data
Jan 12, 2024Wearable devices continuously collect sensor data and use it to infer an individual's behavior, such as sleep, physical activity, and emotions. Despite the significant interest and advancements in this field, modeling multimodal sensor data in real-world environments is still challenging due to low data quality and limited data annotations. In this work, we investigate representation learning for imputing missing wearable data and compare it with state-of-the-art statistical approaches. We investigate the performance of the transformer model on 10 physiological and behavioral signals with different masking ratios. Our results show that transformers outperform baselines for missing data imputation of signals that change more frequently, but not for monotonic signals. We further investigate the impact of imputation strategies and masking rations on downstream classification tasks. Our study provides insights for the design and development of masking-based self-supervised learning tasks and advocates the adoption of hybrid-based imputation strategies to address the challenge of missing data in wearable devices.
KQA Pro: A Large Diagnostic Dataset for Complex Question Answering over Knowledge Base
Jul 08, 2020

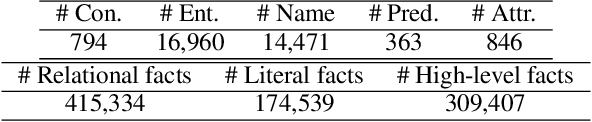
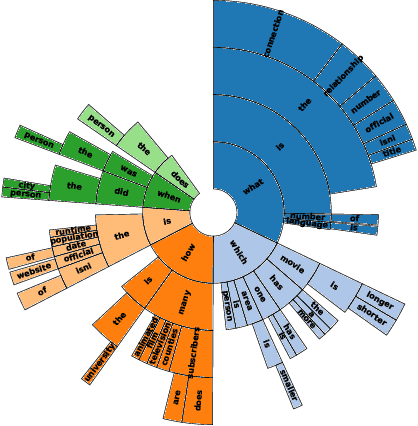
Complex question answering over knowledge base (Complex KBQA) is challenging because it requires the compositional reasoning capability. Existing benchmarks have three shortcomings that limit the development of Complex KBQA: 1) they only provide QA pairs without explicit reasoning processes; 2) questions are either generated by templates, leading to poor diversity, or on a small scale; and 3) they mostly only consider the relations among entities but not attributes. To this end, we introduce KQA Pro, a large-scale dataset for Complex KBQA. We generate questions, SPARQLs, and functional programs with recursive templates and then paraphrase the questions by crowdsourcing, giving rise to around 120K diverse instances. The SPARQLs and programs depict the reasoning processes in various manners, which can benefit a large spectrum of QA methods. We contribute a unified codebase and conduct extensive evaluations for baselines and state-of-the-arts: a blind GRU obtains 31.58\%, the best model achieves only 35.15\%, and humans top at 97.5\%, which offers great research potential to fill the gap.