 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeDR: Segment Representation Learning for Long Documents Dense Retrieval
Nov 20, 2022Recently, Dense Retrieval (DR) has become a promising solution to document retrieval, where document representations are used to perform effective and efficient semantic search. However, DR remains challenging on long documents, due to the quadratic complexity of its Transformer-based encoder and the finite capacity of a low-dimension embedding. Current DR models use suboptimal strategies such as truncating or splitting-and-pooling to long documents leading to poor utilization of whole document information. In this work, to tackle this problem, we propose Segment representation learning for long documents Dense Retrieval (SeDR). In SeDR, Segment-Interaction Transformer is proposed to encode long documents into document-aware and segment-sensitive representations, while it holds the complexity of splitting-and-pooling and outperforms other segment-interaction patterns on DR. Since GPU memory requirements for long document encoding causes insufficient negatives for DR training, Late-Cache Negative is further proposed to provide additional cache negatives for optimizing representation learning. Experiments on MS MARCO and TREC-DL datasets show that SeDR achieves superior performance among DR models, and confirm the effectiveness of SeDR on long document retrieval.
Personalized Federated Learning: An Attentive Collaboration Approach
Jul 07, 2020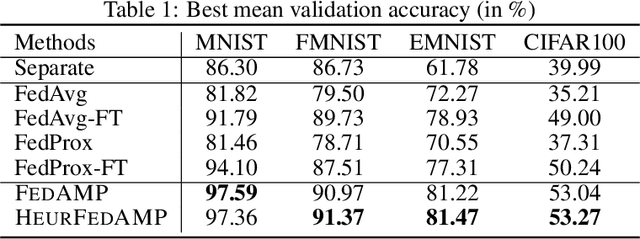



For the challenging computational environment of IOT/edge computing, personalized federated learning allows every client to train a strong personalized cloud model by effectively collaborating with the other clients in a privacy-preserving manner. The performance of personalized federated learning is largely determined by the effectiveness of inter-client collaboration. However, when the data is non-IID across all clients, it is challenging to infer the collaboration relationships between clients without knowing their data distributions. In this paper, we propose to tackle this problem by a novel framework named federated attentive message passing (FedAMP) that allows each client to collaboratively train its own personalized cloud model without using a global model. FedAMP implements an attentive collaboration mechanism by iteratively encouraging clients with more similar model parameters to have stronger collaborations. This adaptively discovers the underlying collaboration relationships between clients, which significantly boosts effectiveness of collaboration and leads to the outstanding performance of FedAMP. We establish the convergence of FedAMP for both convex and non-convex models, and further propose a heuristic method that resembles the FedAMP framework to further improve its performance for federated learning with deep neural networks. Extensive experiments demonstrate the superior performance of our methods in handling non-IID data, dirty data and dropped clients.