 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA provable control of sensitivity of neural networks through a direct parameterization of the overall bi-Lipschitzness
Apr 15, 2024
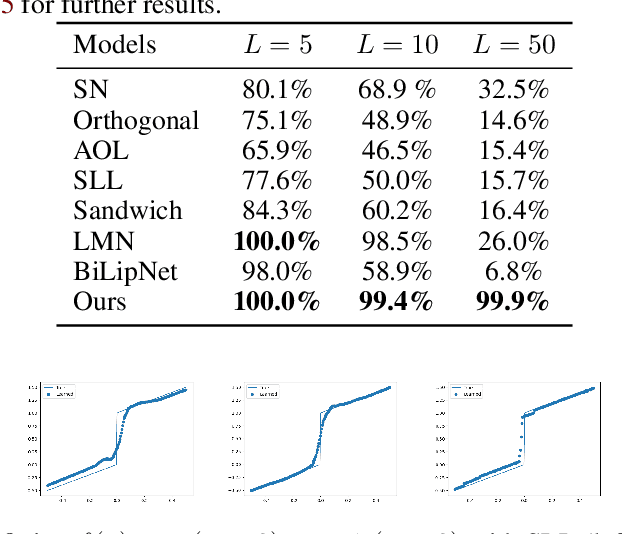
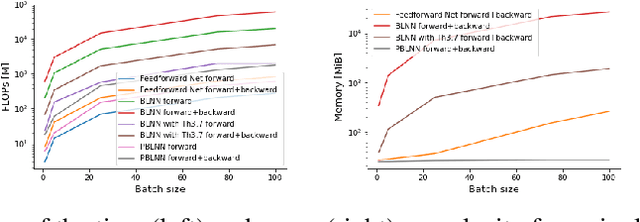

While neural networks can enjoy an outstanding flexibility and exhibit unprecedented performance, the mechanism behind their behavior is still not well-understood. To tackle this fundamental challenge, researchers have tried to restrict and manipulate some of their properties in order to gain new insights and better control on them. Especially, throughout the past few years, the concept of \emph{bi-Lipschitzness} has been proved as a beneficial inductive bias in many areas. However, due to its complexity, the design and control of bi-Lipschitz architectures are falling behind, and a model that is precisely designed for bi-Lipschitzness realizing a direct and simple control of the constants along with solid theoretical analysis is lacking. In this work, we investigate and propose a novel framework for bi-Lipschitzness that can achieve such a clear and tight control based on convex neural networks and the Legendre-Fenchel duality. Its desirable properties are illustrated with concrete experiments. We also apply this framework to uncertainty estimation and monotone problem settings to illustrate its broad range of applications.
Controlling Posterior Collapse by an Inverse Lipschitz Constraint on the Decoder Network
Apr 25, 2023



Variational autoencoders (VAEs) are one of the deep generative models that have experienced enormous success over the past decades. However, in practice, they suffer from a problem called posterior collapse, which occurs when the encoder coincides, or collapses, with the prior taking no information from the latent structure of the input data into consideration. In this work, we introduce an inverse Lipschitz neural network into the decoder and, based on this architecture, provide a new method that can control in a simple and clear manner the degree of posterior collapse for a wide range of VAE models equipped with a concrete theoretical guarantee. We also illustrate the effectiveness of our method through several numerical experiments.
Improved Convergence Rate of Stochastic Gradient Langevin Dynamics with Variance Reduction and its Application to Optimization
Mar 30, 2022
The stochastic gradient Langevin Dynamics is one of the most fundamental algorithms to solve sampling problems and non-convex optimization appearing in several machine learning applications. Especially, its variance reduced versions have nowadays gained particular attention. In this paper, we study two variants of this kind, namely, the Stochastic Variance Reduced Gradient Langevin Dynamics and the Stochastic Recursive Gradient Langevin Dynamics. We prove their convergence to the objective distribution in terms of KL-divergence under the sole assumptions of smoothness and Log-Sobolev inequality which are weaker conditions than those used in prior works for these algorithms. With the batch size and the inner loop length set to $\sqrt{n}$, the gradient complexity to achieve an $\epsilon$-precision is $\tilde{O}((n+dn^{1/2}\epsilon^{-1})\gamma^2 L^2\alpha^{-2})$, which is an improvement from any previous analyses. We also show some essential applications of our result to non-convex optimization.