 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecoding Linguistic Nuances in Mental Health Text Classification Using Expressive Narrative Stories
Dec 20, 2024Recent advancements in NLP have spurred significant interest in analyzing social media text data for identifying linguistic features indicative of mental health issues. However, the domain of Expressive Narrative Stories (ENS)-deeply personal and emotionally charged narratives that offer rich psychological insights-remains underexplored. This study bridges this gap by utilizing a dataset sourced from Reddit, focusing on ENS from individuals with and without self-declared depression. Our research evaluates the utility of advanced language models, BERT and MentalBERT, against traditional models. We find that traditional models are sensitive to the absence of explicit topic-related words, which could risk their potential to extend applications to ENS that lack clear mental health terminology. Despite MentalBERT is design to better handle psychiatric contexts, it demonstrated a dependency on specific topic words for classification accuracy, raising concerns about its application when explicit mental health terms are sparse (P-value<0.05). In contrast, BERT exhibited minimal sensitivity to the absence of topic words in ENS, suggesting its superior capability to understand deeper linguistic features, making it more effective for real-world applications. Both BERT and MentalBERT excel at recognizing linguistic nuances and maintaining classification accuracy even when narrative order is disrupted. This resilience is statistically significant, with sentence shuffling showing substantial impacts on model performance (P-value<0.05), especially evident in ENS comparisons between individuals with and without mental health declarations. These findings underscore the importance of exploring ENS for deeper insights into mental health-related narratives, advocating for a nuanced approach to mental health text analysis that moves beyond mere keyword detection.
Slim Embedding Layers for Recurrent Neural Language Models
Dec 22, 2017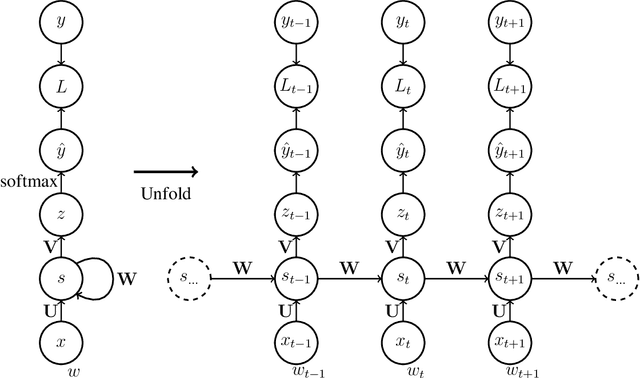
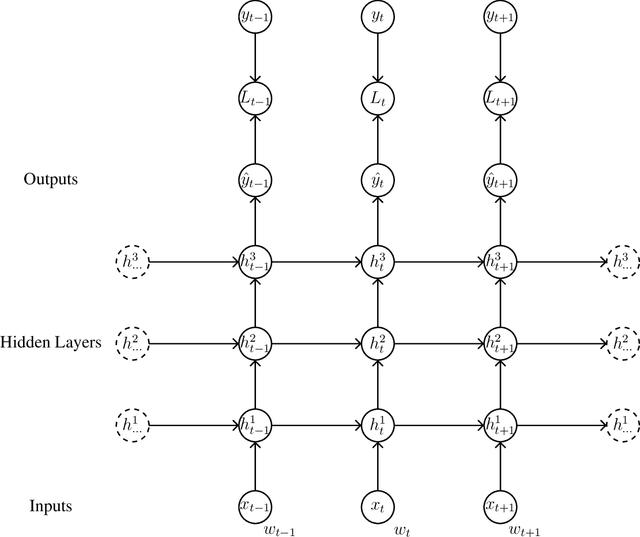
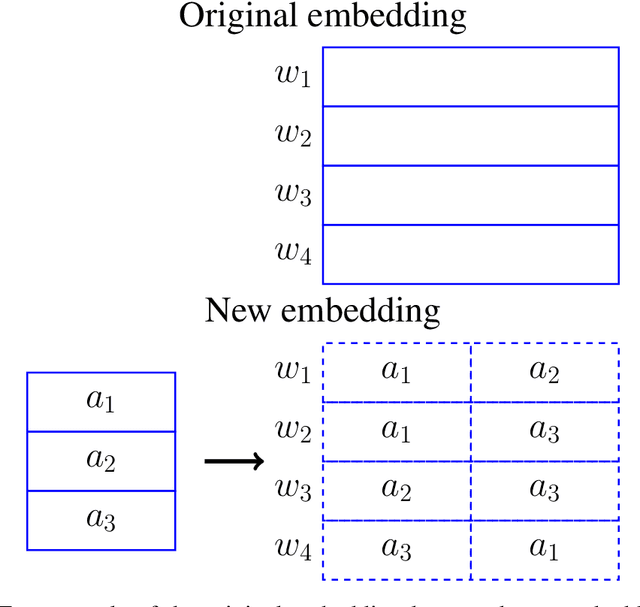
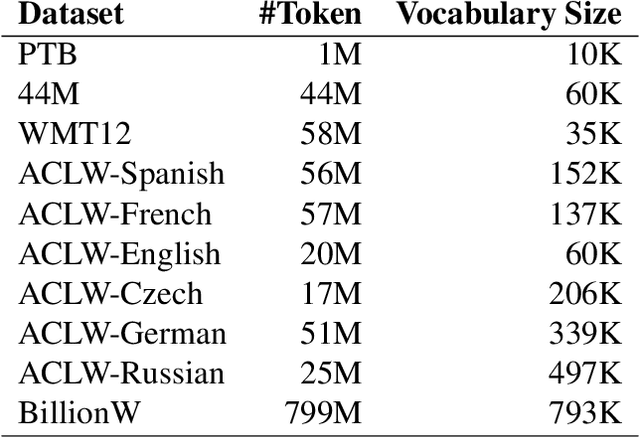
Recurrent neural language models are the state-of-the-art models for language modeling. When the vocabulary size is large, the space taken to store the model parameters becomes the bottleneck for the use of recurrent neural language models. In this paper, we introduce a simple space compression method that randomly shares the structured parameters at both the input and output embedding layers of the recurrent neural language models to significantly reduce the size of model parameters, but still compactly represent the original input and output embedding layers. The method is easy to implement and tune. Experiments on several data sets show that the new method can get similar perplexity and BLEU score results while only using a very tiny fraction of parameters.
Boltzmann Machine Learning with the Latent Maximum Entropy Principle
Oct 19, 2012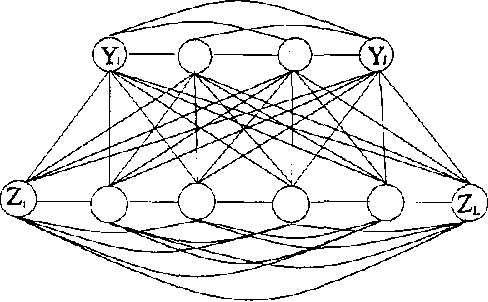
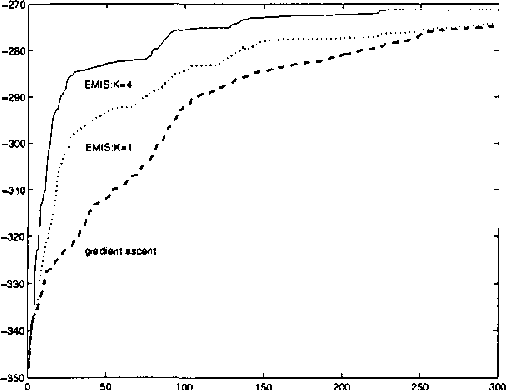
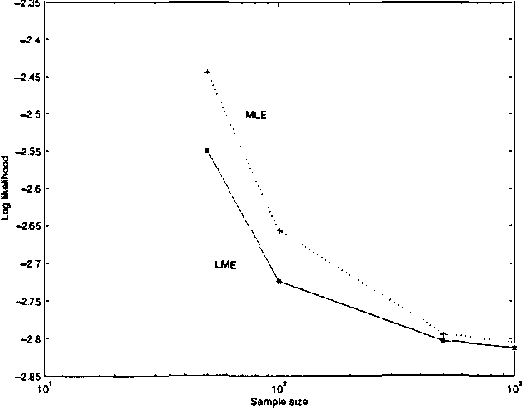
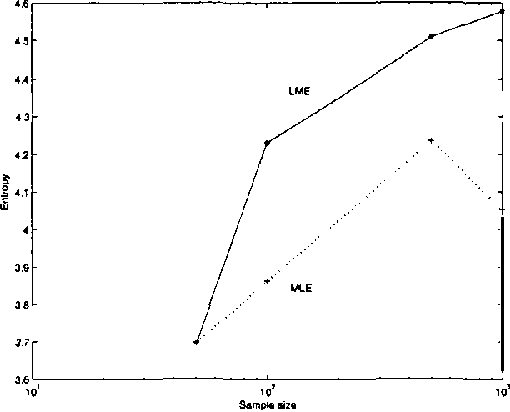
We present a new statistical learning paradigm for Boltzmann machines based on a new inference principle we have proposed: the latent maximum entropy principle (LME). LME is different both from Jaynes maximum entropy principle and from standard maximum likelihood estimation.We demonstrate the LME principle BY deriving new algorithms for Boltzmann machine parameter estimation, and show how robust and fast new variant of the EM algorithm can be developed.Our experiments show that estimation based on LME generally yields better results than maximum likelihood estimation, particularly when inferring hidden units from small amounts of data.