 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEpiLearn: A Python Library for Machine Learning in Epidemic Modeling
Jun 10, 2024

EpiLearn is a Python toolkit developed for modeling, simulating, and analyzing epidemic data. Although there exist several packages that also deal with epidemic modeling, they are often restricted to mechanistic models or traditional statistical tools. As machine learning continues to shape the world, the gap between these packages and the latest models has become larger. To bridge the gap and inspire innovative research in epidemic modeling, EpiLearn not only provides support for evaluating epidemic models based on machine learning, but also incorporates comprehensive tools for analyzing epidemic data, such as simulation, visualization, transformations, etc. For the convenience of both epidemiologists and data scientists, we provide a unified framework for training and evaluation of epidemic models on two tasks: Forecasting and Source Detection. To facilitate the development of new models, EpiLearn follows a modular design, making it flexible and easy to use. In addition, an interactive web application is also developed to visualize the real-world or simulated epidemic data. Our package is available at https://github.com/Emory-Melody/EpiLearn.
A Plug-and-play Scheme to Adapt Image Saliency Deep Model for Video Data
Aug 02, 2020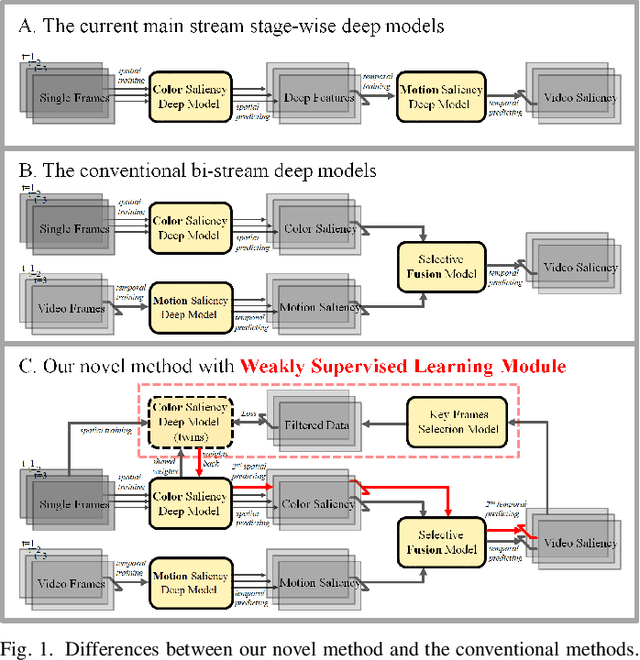

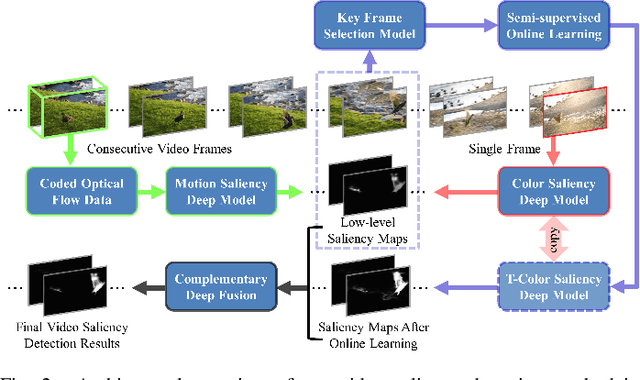

With the rapid development of deep learning techniques, image saliency deep models trained solely by spatial information have occasionally achieved detection performance for video data comparable to that of the models trained by both spatial and temporal information. However, due to the lesser consideration of temporal information, the image saliency deep models may become fragile in the video sequences dominated by temporal information. Thus, the most recent video saliency detection approaches have adopted the network architecture starting with a spatial deep model that is followed by an elaborately designed temporal deep model. However, such methods easily encounter the performance bottleneck arising from the single stream learning methodology, so the overall detection performance is largely determined by the spatial deep model. In sharp contrast to the current mainstream methods, this paper proposes a novel plug-and-play scheme to weakly retrain a pretrained image saliency deep model for video data by using the newly sensed and coded temporal information. Thus, the retrained image saliency deep model will be able to maintain temporal saliency awareness, achieving much improved detection performance. Moreover, our method is simple yet effective for adapting any off-the-shelf pre-trained image saliency deep model to obtain high-quality video saliency detection. Additionally, both the data and source code of our method are publicly available.