 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Agent Reinforcement Learning for Active Voltage Control on Power Distribution Networks
Nov 05, 2021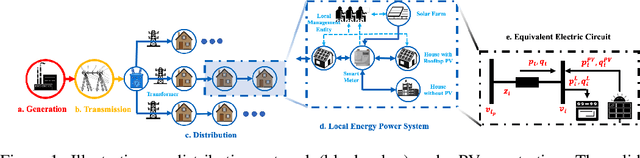


This paper presents a problem in power networks that creates an exciting and yet challenging real-world scenario for application of multi-agent reinforcement learning (MARL). The emerging trend of decarbonisation is placing excessive stress on power distribution networks. Active voltage control is seen as a promising solution to relieve power congestion and improve voltage quality without extra hardware investment, taking advantage of the controllable apparatuses in the network, such as roof-top photovoltaics (PVs) and static var compensators (SVCs). These controllable apparatuses appear in a vast number and are distributed in a wide geographic area, making MARL a natural candidate. This paper formulates the active voltage control problem in the framework of Dec-POMDP and establishes an open-source environment. It aims to bridge the gap between the power community and the MARL community and be a drive force towards real-world applications of MARL algorithms. Finally, we analyse the special characteristics of the active voltage control problems that cause challenges for state-of-the-art MARL approaches, and summarise the potential directions.
SHAQ: Incorporating Shapley Value Theory into Q-Learning for Multi-Agent Reinforcement Learning
May 31, 2021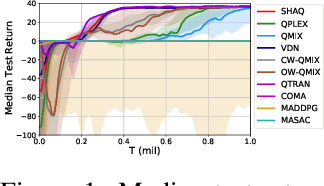

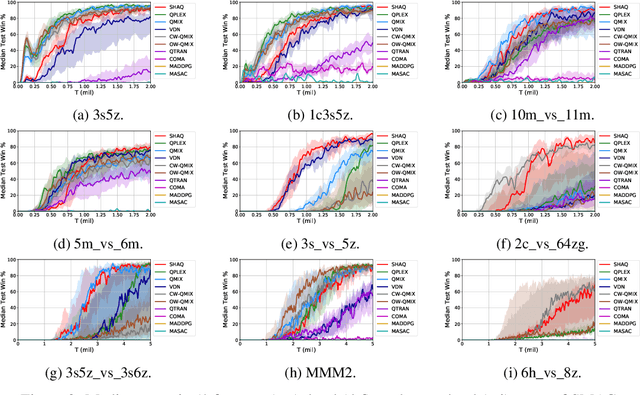
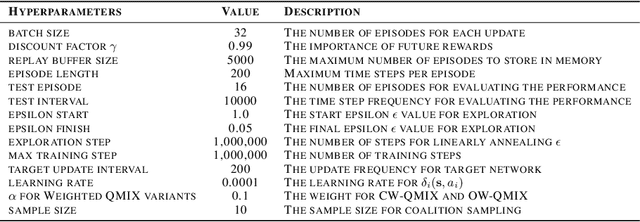
Value factorisation proves to be a very useful technique in multi-agent reinforcement learning (MARL), but the underlying mechanism is not yet fully understood. This paper explores a theoretic basis for value factorisation. We generalise the Shapley value in the coalitional game theory to a Markov convex game (MCG) and use it to guide value factorisation in MARL. We show that the generalised Shapley value possesses several features such as (1) accurate estimation of the maximum global value, (2) fairness in the factorisation of the global value, and (3) being sensitive to dummy agents. The proposed theory yields a new learning algorithm called Sharpley Q-learning (SHAQ), which inherits the important merits of ordinary Q-learning but extends it to MARL. In comparison with prior-arts, SHAQ has a much weaker assumption (MCG) that is more compatible with real-world problems, but has superior explainability and performance in many cases. We demonstrated SHAQ and verified the theoretic claims on Predator-Prey and StarCraft Multi-Agent Challenge (SMAC).
Modelling Hierarchical Structure between Dialogue Policy and Natural Language Generator with Option Framework for Task-oriented Dialogue System
Jun 11, 2020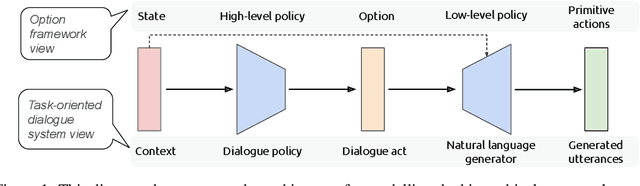
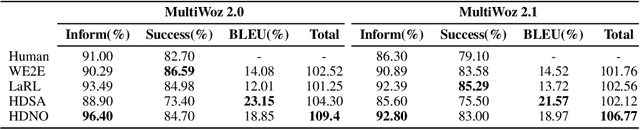
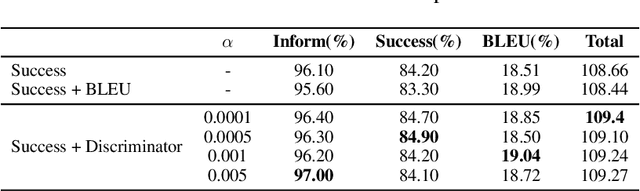

Designing task-oriented dialogue systems is a challenging research topic, since it needs not only to generate utterances fulfilling user requests but also to guarantee the comprehensibility. Many previous works trained end-to-end (E2E) models with supervised learning (SL), however, the bias in annotated system utterances remains as a bottleneck. Reinforcement learning (RL) deals with the problem through using non-differentiable evaluation metrics (e.g., the success rate) as rewards. Nonetheless, existing works with RL showed that the comprehensibility of generated system utterances could be corrupted when improving the performance on fulfilling user requests. In our work, we (1) propose modelling the hierarchical structure between dialogue policy and natural language generator (NLG) with the option framework, called HDNO; (2) train HDNO with hierarchical reinforcement learning (HRL), as well as suggest alternating updates between dialogue policy and NLG during HRL inspired by fictitious play, to preserve the comprehensibility of generated system utterances while improving fulfilling user requests; and (3) propose using a discriminator modelled with language models as an additional reward to further improve the comprehensibility. We test HDNO on MultiWoz 2.0 and MultiWoz 2.1, the datasets on multi-domain dialogues, in comparison with word-level E2E model trained with RL, LaRL and HDSA, showing a significant improvement on the total performance evaluated with automatic metrics.
Rethink Global Reward Game and Credit Assignment in Multi-agent Reinforcement Learning
Jul 11, 2019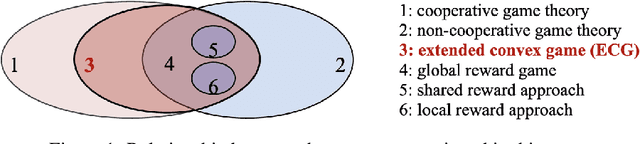



Cooperative game is a critical research area in multi-agent reinforcement learning (MARL). Global reward game is a subclass of cooperative games, where all agents aim to maximize cumulative global rewards. Credit assignment is an important problem studied in the global reward game. Most works stand by the view of non-cooperative-game theoretical framework with the shared reward approach, i.e., each agent is assigned a shared global reward directly. This, however, may give each agent an inaccurate feedback on his contribution to the group. In this paper, we introduce a cooperative-game theoretical framework and extend it to the finite-horizon case. We show that our proposed framework is a superset of the global reward game. Based on this framework, we propose an algorithm called Shapley Q-value policy gradient (SQPG) to learn a local reward approach that can distribute the cumulative global reward fairly, reflecting each agent's own contribution in contrast to the shared reward approach. We evaluate our method on the Cooperative Navigation, Prey-and-Predator and Traffic Junction, compared with MADDPG, COMA, Independent actor-critic and Independent DDPG. In the experiments, our algorithm shows better convergence than the baselines.