 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning the Basis: A Kolmogorov-Arnold Network Approach Embedding Green's Function Priors
Nov 13, 2025The Method of Moments (MoM) is constrained by the usage of static, geometry-defined basis functions, such as the Rao-Wilton-Glisson (RWG) basis. This letter reframes electromagnetic modeling around a learnable basis representation rather than solving for the coefficients over a fixed basis. We first show that the RWG basis is essentially a static and piecewise-linear realization of the Kolmogorov-Arnold representation theorem. Inspired by this insight, we propose PhyKAN, a physics-informed Kolmogorov-Arnold Network (KAN) that generalizes RWG into a learnable and adaptive basis family. Derived from the EFIE, PhyKAN integrates a local KAN branch with a global branch embedded with Green's function priors to preserve physical consistency. It is demonstrated that, across canonical geometries, PhyKAN achieves sub-0.01 reconstruction errors as well as accurate, unsupervised radar cross section predictions, offering an interpretable, physics-consistent bridge between classical solvers and modern neural network models for electromagnetic modeling.
MRIFE: A Mask-Recovering and Interactive-Feature-Enhancing Semantic Segmentation Network For Relic Landslide Detection
Nov 26, 2024



Relic landslide, formed over a long period, possess the potential for reactivation, making them a hazardous geological phenomenon. While reliable relic landslide detection benefits the effective monitoring and prevention of landslide disaster, semantic segmentation using high-resolution remote sensing images for relic landslides faces many challenges, including the object visual blur problem, due to the changes of appearance caused by prolonged natural evolution and human activities, and the small-sized dataset problem, due to difficulty in recognizing and labelling the samples. To address these challenges, a semantic segmentation model, termed mask-recovering and interactive-feature-enhancing (MRIFE), is proposed for more efficient feature extraction and separation. Specifically, a contrastive learning and mask reconstruction method with locally significant feature enhancement is proposed to improve the ability to distinguish between the target and background and represent landslide semantic features. Meanwhile, a dual-branch interactive feature enhancement architecture is used to enrich the extracted features and address the issue of visual ambiguity. Self-distillation learning is introduced to leverage the feature diversity both within and between samples for contrastive learning, improving sample utilization, accelerating model convergence, and effectively addressing the problem of the small-sized dataset. The proposed MRIFE is evaluated on a real relic landslide dataset, and experimental results show that it greatly improves the performance of relic landslide detection. For the semantic segmentation task, compared to the baseline, the precision increases from 0.4226 to 0.5347, the mean intersection over union (IoU) increases from 0.6405 to 0.6680, the landslide IoU increases from 0.3381 to 0.3934, and the F1-score increases from 0.5054 to 0.5646.
A Hyper-pixel-wise Contrastive Learning Augmented Segmentation Network for Old Landslide Detection Using High-Resolution Remote Sensing Images and Digital Elevation Model Data
Aug 02, 2023



As a harzard disaster, landslide often brings tremendous losses to humanity, so it's necessary to achieve reliable detection of landslide. However, the problems of visual blur and small-sized dataset cause great challenges for old landslide detection task when using remote sensing data. To reliably extract semantic features, a hyper-pixel-wise contrastive learning augmented segmentation network (HPCL-Net) is proposed, which augments the local salient feature extraction from the boundaries of landslides through HPCL and fuses the heterogeneous infromation in the semantic space from High-Resolution Remote Sensing Images and Digital Elevation Model Data data. For full utilization of the precious samples, a global hyper-pixel-wise sample pair queues-based contrastive learning method, which includes the construction of global queues that store hyper-pixel-wise samples and the updating scheme of a momentum encoder, is developed, reliably enhancing the extraction ability of semantic features. The proposed HPCL-Net is evaluated on a Loess Plateau old landslide dataset and experiment results show that the model greatly improves the reliablity of old landslide detection compared to the previous old landslide segmentation model, where mIoU metric is increased from 0.620 to 0.651, Landslide IoU metric is increased from 0.334 to 0.394 and F1-score metric is increased from 0.501 to 0.565.
An Iterative Classification and Semantic Segmentation Network for Old Landslide Detection Using High-Resolution Remote Sensing Images
Feb 24, 2023



Huge challenges exist for old landslide detection because their morphology features have been partially or strongly transformed over a long time and have little difference from their surrounding. Besides, small-sample problem also restrict in-depth learning. In this paper, an iterative classification and semantic segmentation network (ICSSN) is developed, which can greatly enhance both object-level and pixel-level classification performance by iteratively upgrading the feature extractor shared by two network. An object-level contrastive learning (OCL) strategy is employed in the object classification sub-network featuring a siamese network to realize the global features extraction, and a sub-object-level contrastive learning (SOCL) paradigm is designed in the semantic segmentation sub-network to efficiently extract salient features from boundaries of landslides. Moreover, an iterative training strategy is elaborated to fuse features in semantic space such that both object-level and pixel-level classification performance are improved. The proposed ICSSN is evaluated on the real landslide data set, and the experimental results show that ICSSN can greatly improve the classification and segmentation accuracy of old landslide detection. For the semantic segmentation task, compared to the baseline, the F1 score increases from 0.5054 to 0.5448, the mIoU improves from 0.6405 to 0.6610, the landslide IoU improved from 0.3381 to 0.3743, and the object-level detection accuracy of old landslides is enhanced from 0.55 to 0.9. For the object classification task, the F1 score increases from 0.8846 to 0.9230, and the accuracy score is up from 0.8375 to 0.8875.
Multi-faceted Graph Attention Network for Radar Target Recognition in Heterogeneous Radar Network
Jun 10, 2022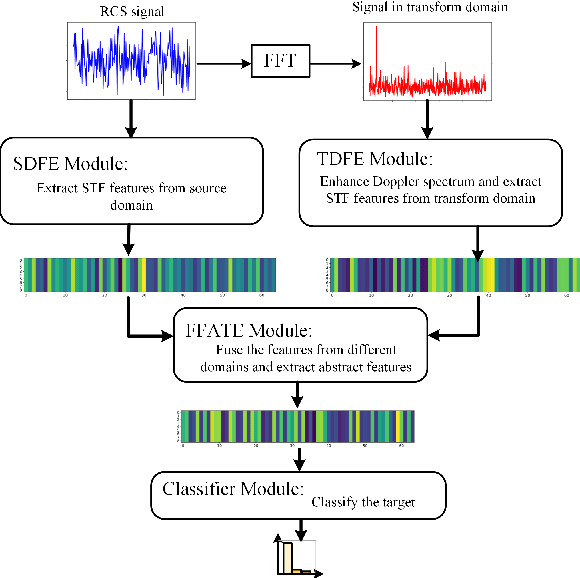

Radar target recognition (RTR), as a key technology of intelligent radar systems, has been well investigated. Accurate RTR at low signal-to-noise ratios (SNRs) still remains an open challenge. Most existing methods are based on a single radar or the homogeneous radar network, which do not fully exploit frequency-dimensional information. In this paper, a two-stream semantic feature fusion model, termed Multi-faceted Graph Attention Network (MF-GAT), is proposed to greatly improve the accuracy in the low SNR region of the heterogeneous radar network. By fusing the features extracted from the source domain and transform domain via a graph attention network model, the MF-GAT model distills higher-level semantic features before classification in a unified framework. Extensive experiments are presented to demonstrate that the proposed model can greatly improve the RTR performance at low SNRs.
* 6 pages, 4 figures
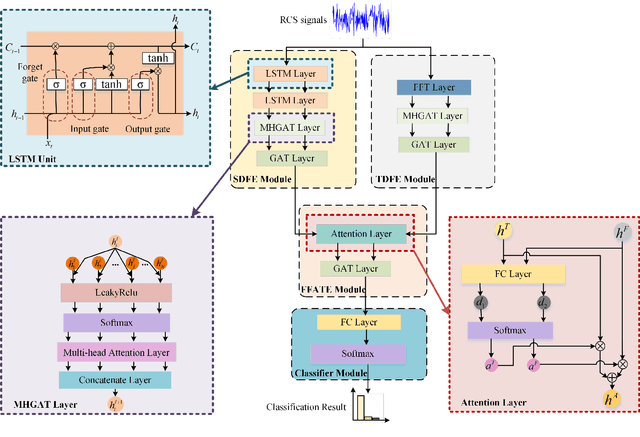
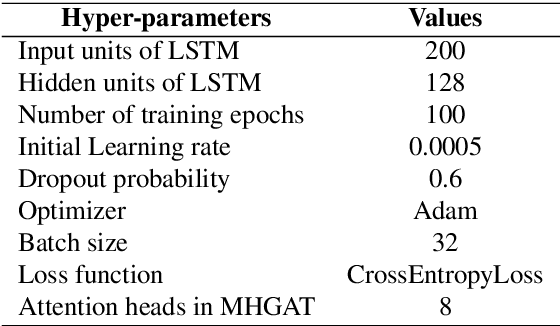
Spatio-Temporal-Frequency Graph Attention Convolutional Network for Aircraft Recognition Based on Heterogeneous Radar Network
Apr 15, 2022
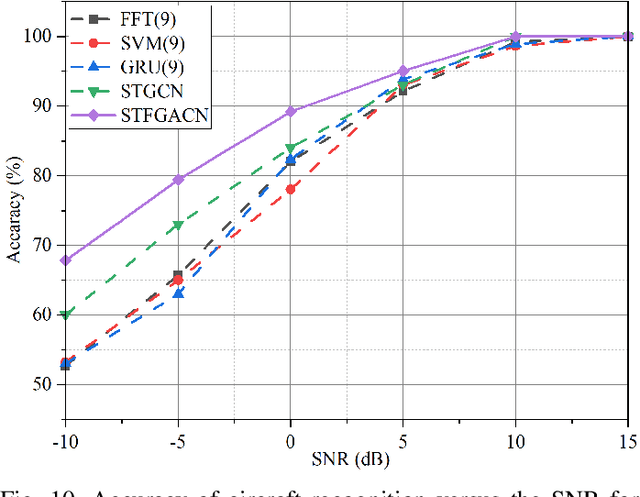
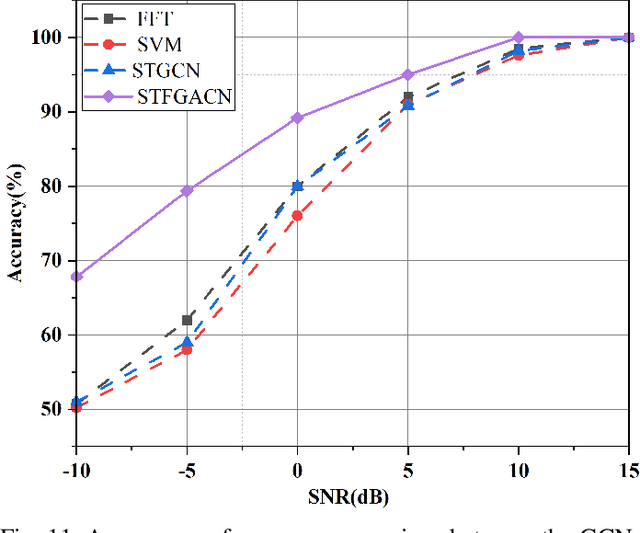
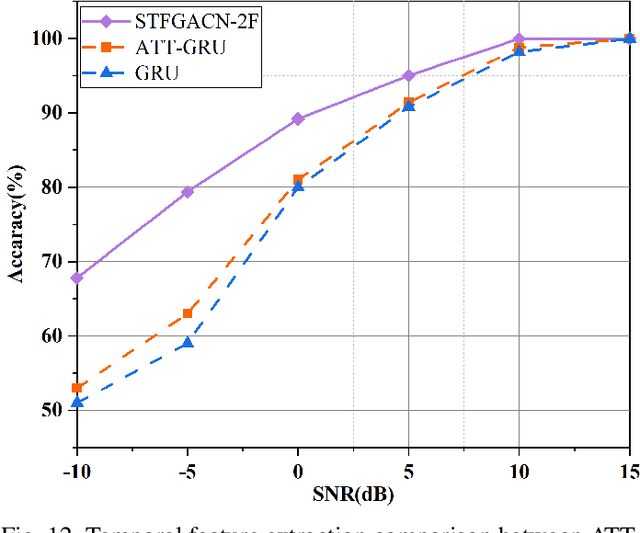
This paper proposes a knowledge-and-data-driven graph neural network-based collaboration learning model for reliable aircraft recognition in a heterogeneous radar network. The aircraft recognizability analysis shows that: (1) the semantic feature of an aircraft is motion patterns driven by the kinetic characteristics, and (2) the grammatical features contained in the radar cross-section (RCS) signals present spatial-temporal-frequency (STF) diversity decided by both the electromagnetic radiation shape and motion pattern of the aircraft. Then a STF graph attention convolutional network (STFGACN) is developed to distill semantic features from the RCS signals received by the heterogeneous radar network. Extensive experiment results verify that the STFGACN outperforms the baseline methods in terms of detection accuracy, and ablation experiments are carried out to further show that the expansion of the information dimension can gain considerable benefits to perform robustly in the low signal-to-noise ratio region.
Deep learning-based UAV detection in the low altitude clutter background
Feb 24, 2022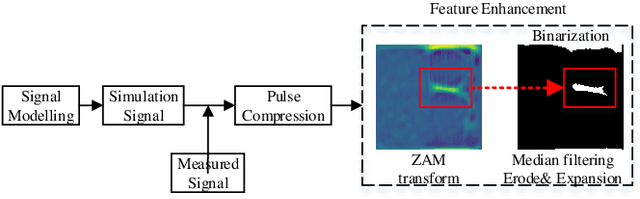
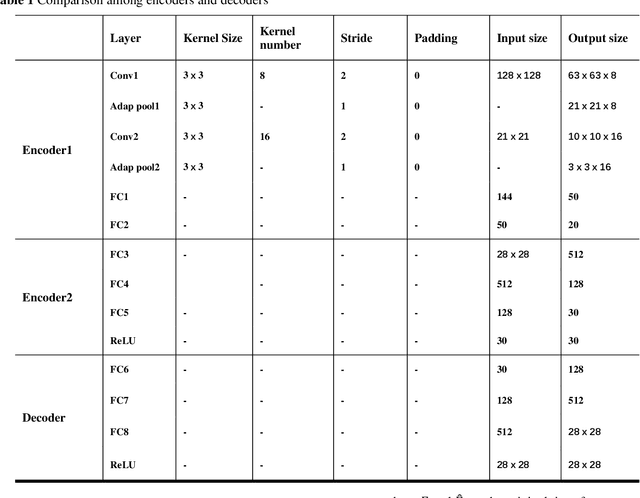
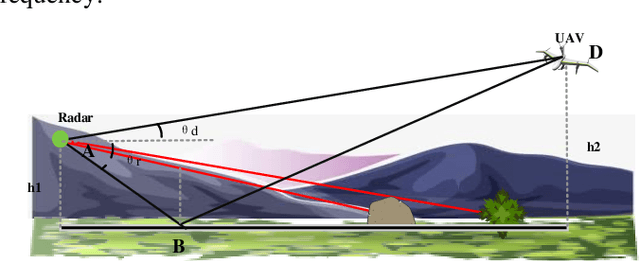
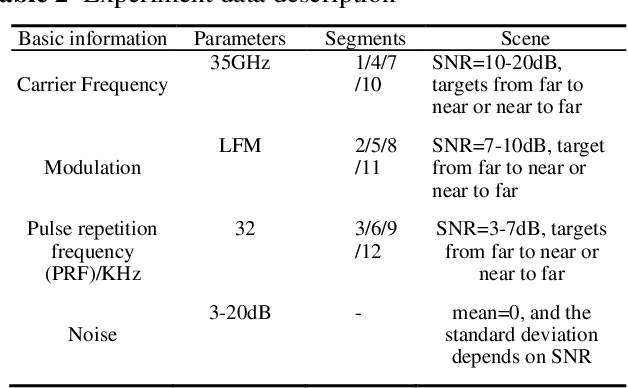
Unmanned aerial vehicles (UAVs) are widely used due to their low cost and versatility, but they also pose security and privacy threats. Therefore, reliable detection for low-altitude UAVs is an important issue. The strong ground clutter makes the radar echoes from small UAVs submerged in noise, resulting in low radar detection reliability. A low-altitude UAV detection method based on deep contrastive learning is proposed to address the above problems: Concretely, a low-altitude UAV radar echo model under low-altitude clutter interference is first established. Based on the echo components and the UAV Doppler domain identifiable mechanism, a time-frequency transformation method combining ZAM transform and morphological operations is used to suppress the ambiguity problem under clutter. Then feature extraction and fusion method introducing contrast learning is utilized to suppress non-target ground clutter interference. Finally, a detector relying on semantic features is designed for the reliable identification of low-altitude UAVs. The experiments carried out on both real and simulated data confirm that the proposed method can effectively suppress ground clutter and reliably extract recognizable semantic features of UAVs. The proposed method achieves lower false and missing alarms compared with recent state-of-art solutions and improves the detection accuracy by more than 5% for the same signal-to-noise ratio, which effectively improves the detection reliability.
DDU-Net: Dual-Decoder-U-Net for Road Extraction Using High-Resolution Remote Sensing Images
Jan 18, 2022
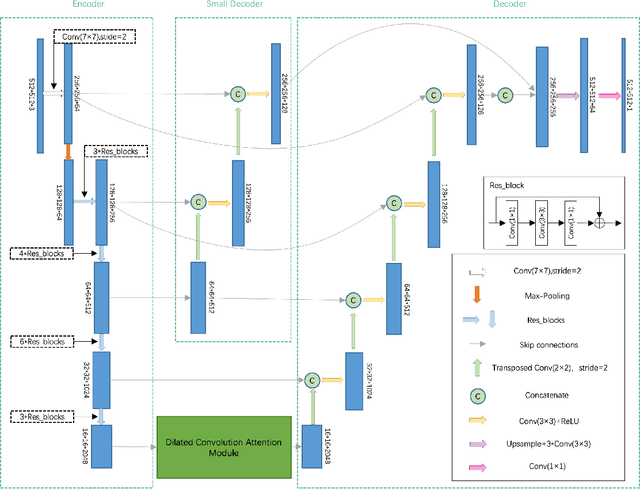
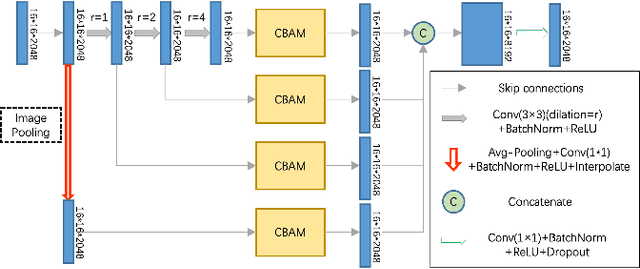
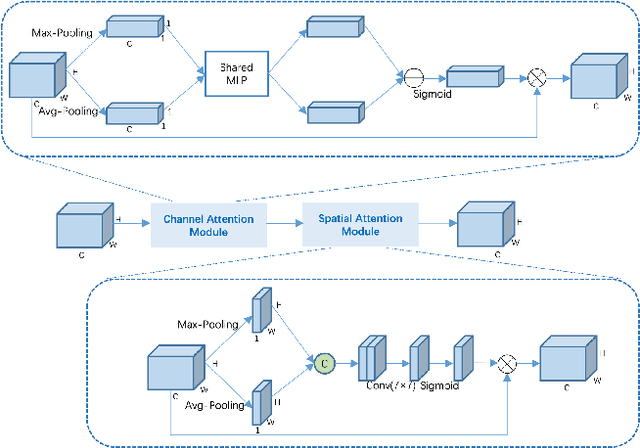
Extracting roads from high-resolution remote sensing images (HRSIs) is vital in a wide variety of applications, such as autonomous driving, path planning, and road navigation. Due to the long and thin shape as well as the shades induced by vegetation and buildings, small-sized roads are more difficult to discern. In order to improve the reliability and accuracy of small-sized road extraction when roads of multiple sizes coexist in an HRSI, an enhanced deep neural network model termed Dual-Decoder-U-Net (DDU-Net) is proposed in this paper. Motivated by the U-Net model, a small decoder is added to form a dual-decoder structure for more detailed features. In addition, we introduce the dilated convolution attention module (DCAM) between the encoder and decoders to increase the receptive field as well as to distill multi-scale features through cascading dilated convolution and global average pooling. The convolutional block attention module (CBAM) is also embedded in the parallel dilated convolution and pooling branches to capture more attention-aware features. Extensive experiments are conducted on the Massachusetts Roads dataset with experimental results showing that the proposed model outperforms the state-of-the-art DenseUNet, DeepLabv3+ and D-LinkNet by 6.5%, 3.3%, and 2.1% in the mean Intersection over Union (mIoU), and by 4%, 4.8%, and 3.1% in the F1 score, respectively. Both ablation and heatmap analyses are presented to validate the effectiveness of the proposed model.