 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTighter Analysis of Alternating Stochastic Gradient Method for Stochastic Nested Problems
Jun 25, 2021


Stochastic nested optimization, including stochastic compositional, min-max and bilevel optimization, is gaining popularity in many machine learning applications. While the three problems share the nested structure, existing works often treat them separately, and thus develop problem-specific algorithms and their analyses. Among various exciting developments, simple SGD-type updates (potentially on multiple variables) are still prevalent in solving this class of nested problems, but they are believed to have slower convergence rate compared to that of the non-nested problems. This paper unifies several SGD-type updates for stochastic nested problems into a single SGD approach that we term ALternating Stochastic gradient dEscenT (ALSET) method. By leveraging the hidden smoothness of the problem, this paper presents a tighter analysis of ALSET for stochastic nested problems. Under the new analysis, to achieve an $\epsilon$-stationary point of the nested problem, it requires ${\cal O}(\epsilon^{-2})$ samples. Under certain regularity conditions, applying our results to stochastic compositional, min-max and reinforcement learning problems either improves or matches the best-known sample complexity in the respective cases. Our results explain why simple SGD-type algorithms in stochastic nested problems all work very well in practice without the need for further modifications.
A Single-Timescale Stochastic Bilevel Optimization Method
Feb 22, 2021

Stochastic bilevel optimization generalizes the classic stochastic optimization from the minimization of a single objective to the minimization of an objective function that depends the solution of another optimization problem. Recently, stochastic bilevel optimization is regaining popularity in emerging machine learning applications such as hyper-parameter optimization and model-agnostic meta learning. To solve this class of stochastic optimization problems, existing methods require either double-loop or two-timescale updates, which are sometimes less efficient. This paper develops a new optimization method for a class of stochastic bilevel problems that we term Single-Timescale stochAstic BiLevEl optimization (STABLE) method. STABLE runs in a single loop fashion, and uses a single-timescale update with a fixed batch size. To achieve an $\epsilon$-stationary point of the bilevel problem, STABLE requires ${\cal O}(\epsilon^{-2})$ samples in total; and to achieve an $\epsilon$-optimal solution in the strongly convex case, STABLE requires ${\cal O}(\epsilon^{-1})$ samples. To the best of our knowledge, this is the first bilevel optimization algorithm achieving the same order of sample complexity as the stochastic gradient descent method for the single-level stochastic optimization.
CADA: Communication-Adaptive Distributed Adam
Dec 31, 2020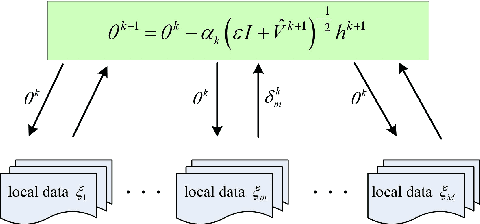


Stochastic gradient descent (SGD) has taken the stage as the primary workhorse for large-scale machine learning. It is often used with its adaptive variants such as AdaGrad, Adam, and AMSGrad. This paper proposes an adaptive stochastic gradient descent method for distributed machine learning, which can be viewed as the communication-adaptive counterpart of the celebrated Adam method - justifying its name CADA. The key components of CADA are a set of new rules tailored for adaptive stochastic gradients that can be implemented to save communication upload. The new algorithms adaptively reuse the stale Adam gradients, thus saving communication, and still have convergence rates comparable to original Adam. In numerical experiments, CADA achieves impressive empirical performance in terms of total communication round reduction.
Solving Stochastic Compositional Optimization is Nearly as Easy as Solving Stochastic Optimization
Aug 31, 2020
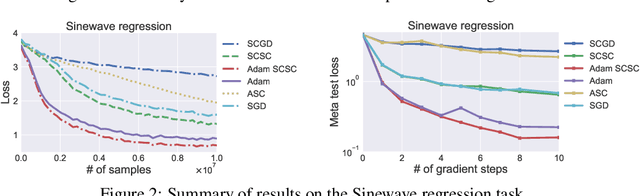
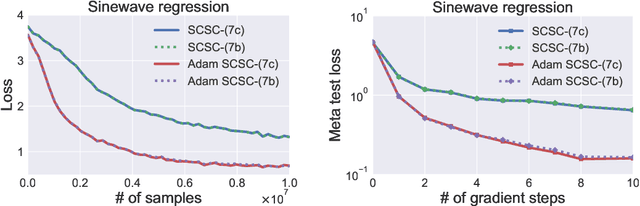
Stochastic compositional optimization generalizes classic (non-compositional) stochastic optimization to the minimization of compositions of functions. Each composition may introduce an additional expectation. The series of expectations may be nested. Stochastic compositional optimization is gaining popularity in applications such as reinforcement learning and meta learning. This paper presents a new Stochastically Corrected Stochastic Compositional gradient method (SCSC). SCSC runs in a single-time scale with a single loop, uses a fixed batch size, and guarantees to converge at the same rate as the stochastic gradient descent (SGD) method for non-compositional stochastic optimization. This is achieved by making a careful improvement to a popular stochastic compositional gradient method. It is easy to apply SGD-improvement techniques to accelerate SCSC. This helps SCSC achieve state-of-the-art performance for stochastic compositional optimization. In particular, we apply Adam to SCSC, and the exhibited rate of convergence matches that of the original Adam on non-compositional stochastic optimization. We test SCSC using the portfolio management and model-agnostic meta-learning tasks.
VAFL: a Method of Vertical Asynchronous Federated Learning
Jul 12, 2020



Horizontal Federated learning (FL) handles multi-client data that share the same set of features, and vertical FL trains a better predictor that combine all the features from different clients. This paper targets solving vertical FL in an asynchronous fashion, and develops a simple FL method. The new method allows each client to run stochastic gradient algorithms without coordination with other clients, so it is suitable for intermittent connectivity of clients. This method further uses a new technique of perturbed local embedding to ensure data privacy and improve communication efficiency. Theoretically, we present the convergence rate and privacy level of our method for strongly convex, nonconvex and even nonsmooth objectives separately. Empirically, we apply our method to FL on various image and healthcare datasets. The results compare favorably to centralized and synchronous FL methods.
LASG: Lazily Aggregated Stochastic Gradients for Communication-Efficient Distributed Learning
Feb 26, 2020

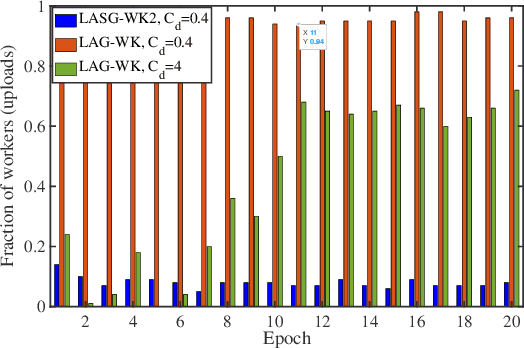

This paper targets solving distributed machine learning problems such as federated learning in a communication-efficient fashion. A class of new stochastic gradient descent (SGD) approaches have been developed, which can be viewed as the stochastic generalization to the recently developed lazily aggregated gradient (LAG) method --- justifying the name LASG. LAG adaptively predicts the contribution of each round of communication and chooses only the significant ones to perform. It saves communication while also maintains the rate of convergence. However, LAG only works with deterministic gradients, and applying it to stochastic gradients yields poor performance. The key components of LASG are a set of new rules tailored for stochastic gradients that can be implemented either to save download, upload, or both. The new algorithms adaptively choose between fresh and stale stochastic gradients and have convergence rates comparable to the original SGD. LASG achieves impressive empirical performance --- it typically saves total communication by an order of magnitude.
General Proximal Incremental Aggregated Gradient Algorithms: Better and Novel Results under General Scheme
Oct 11, 2019
The incremental aggregated gradient algorithm is popular in network optimization and machine learning research. However, the current convergence results require the objective function to be strongly convex. And the existing convergence rates are also limited to linear convergence. Due to the mathematical techniques, the stepsize in the algorithm is restricted by the strongly convex constant, which may make the stepsize be very small (the strongly convex constant may be small). In this paper, we propose a general proximal incremental aggregated gradient algorithm, which contains various existing algorithms including the basic incremental aggregated gradient method. Better and new convergence results are proved even with the general scheme. The novel results presented in this paper, which have not appeared in previous literature, include: a general scheme, nonconvex analysis, the sublinear convergence rates of the function values, much larger stepsizes that guarantee the convergence, the convergence when noise exists, the line search strategy of the proximal incremental aggregated gradient algorithm and its convergence.
Decentralized Markov Chain Gradient Descent
Sep 23, 2019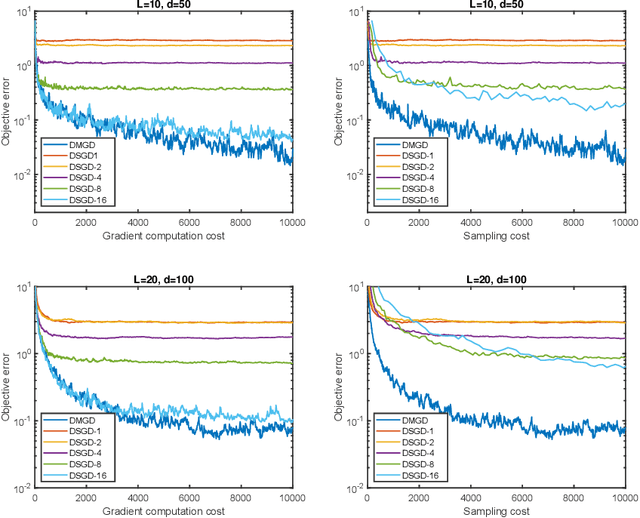
Decentralized stochastic gradient method emerges as a promising solution for solving large-scale machine learning problems. This paper studies the decentralized Markov chain gradient descent (DMGD) algorithm - a variant of the decentralized stochastic gradient methods where the random samples are taken along the trajectory of a Markov chain. This setting is well-motivated when obtaining independent samples is costly or impossible, which excludes the use of the traditional stochastic gradient algorithms. Specifically, we consider the first- and zeroth-order versions of decentralized Markov chain gradient descent over a connected network, where each node only communicates with its neighbors about intermediate results. The nonergodic convergence and the ergodic convergence rate of the proposed algorithms have been rigorously established, and their critical dependences on the network topology and the mixing time of Markov chain have been highlighted. The numerical tests further validate the sample efficiency of our algorithm.
Markov Chain Block Coordinate Descent
Nov 22, 2018
The method of block coordinate gradient descent (BCD) has been a powerful method for large-scale optimization. This paper considers the BCD method that successively updates a series of blocks selected according to a Markov chain. This kind of block selection is neither i.i.d. random nor cyclic. On the other hand, it is a natural choice for some applications in distributed optimization and Markov decision process, where i.i.d. random and cyclic selections are either infeasible or very expensive. By applying mixing-time properties of a Markov chain, we prove convergence of Markov chain BCD for minimizing Lipschitz differentiable functions, which can be nonconvex. When the functions are convex and strongly convex, we establish both sublinear and linear convergence rates, respectively. We also present a method of Markov chain inertial BCD. Finally, we discuss potential applications.
On Markov Chain Gradient Descent
Sep 12, 2018

Stochastic gradient methods are the workhorse (algorithms) of large-scale optimization problems in machine learning, signal processing, and other computational sciences and engineering. This paper studies Markov chain gradient descent, a variant of stochastic gradient descent where the random samples are taken on the trajectory of a Markov chain. Existing results of this method assume convex objectives and a reversible Markov chain and thus have their limitations. We establish new non-ergodic convergence under wider step sizes, for nonconvex problems, and for non-reversible finite-state Markov chains. Nonconvexity makes our method applicable to broader problem classes. Non-reversible finite-state Markov chains, on the other hand, can mix substatially faster. To obtain these results, we introduce a new technique that varies the mixing levels of the Markov chains. The reported numerical results validate our contributions.