 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCSST Strong Lensing Preparation: a Framework for Detecting Strong Lenses in the Multi-color Imaging Survey by the China Survey Space Telescope (CSST)
Apr 02, 2024Strong gravitational lensing is a powerful tool for investigating dark matter and dark energy properties. With the advent of large-scale sky surveys, we can discover strong lensing systems on an unprecedented scale, which requires efficient tools to extract them from billions of astronomical objects. The existing mainstream lens-finding tools are based on machine learning algorithms and applied to cut-out-centered galaxies. However, according to the design and survey strategy of optical surveys by CSST, preparing cutouts with multiple bands requires considerable efforts. To overcome these challenges, we have developed a framework based on a hierarchical visual Transformer with a sliding window technique to search for strong lensing systems within entire images. Moreover, given that multi-color images of strong lensing systems can provide insights into their physical characteristics, our framework is specifically crafted to identify strong lensing systems in images with any number of channels. As evaluated using CSST mock data based on an Semi-Analytic Model named CosmoDC2, our framework achieves precision and recall rates of 0.98 and 0.90, respectively. To evaluate the effectiveness of our method in real observations, we have applied it to a subset of images from the DESI Legacy Imaging Surveys and media images from Euclid Early Release Observations. 61 new strong lensing system candidates are discovered by our method. However, we also identified false positives arising primarily from the simplified galaxy morphology assumptions within the simulation. This underscores the practical limitations of our approach while simultaneously highlighting potential avenues for future improvements.
VMRFANet:View-Specific Multi-Receptive Field Attention Network for Person Re-identification
Jan 21, 2020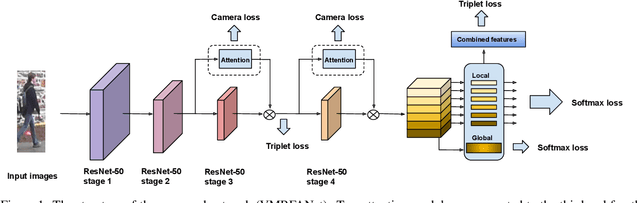
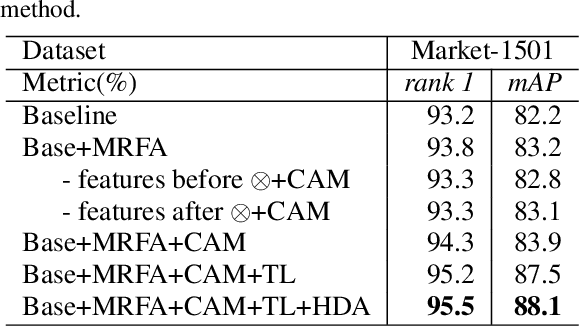
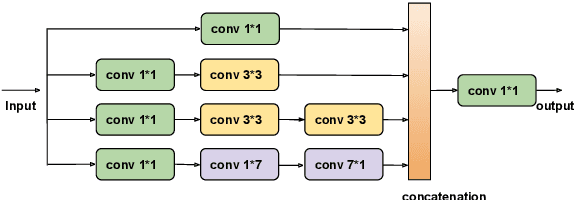
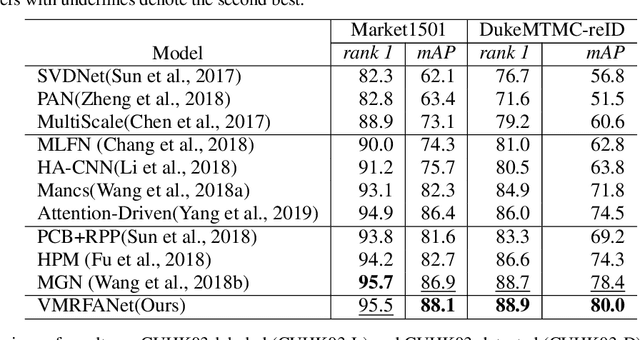
Person re-identification (re-ID) aims to retrieve the same person across different cameras. In practice, it still remains a challenging task due to background clutter, variations on body poses and view conditions, inaccurate bounding box detection, etc. To tackle these issues, in this paper, we propose a novel multi-receptive field attention (MRFA) module that utilizes filters of various sizes to help network focusing on informative pixels. Besides, we present a view-specific mechanism that guides attention module to handle the variation of view conditions. Moreover, we introduce a Gaussian horizontal random cropping/padding method which further improves the robustness of our proposed network. Comprehensive experiments demonstrate the effectiveness of each component. Our method achieves 95.5% / 88.1% in rank-1 / mAP on Market-1501, 88.9% / 80.0% on DukeMTMC-reID, 81.1% / 78.8% on CUHK03 labeled dataset and 78.9% / 75.3% on CUHK03 detected dataset, outperforming current state-of-the-art methods.