 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVMRFANet:View-Specific Multi-Receptive Field Attention Network for Person Re-identification
Jan 21, 2020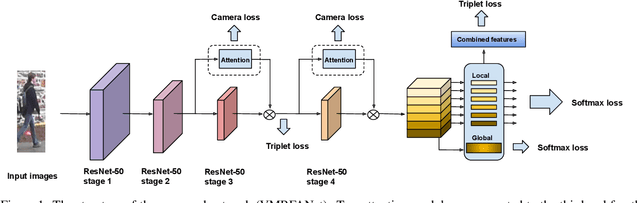
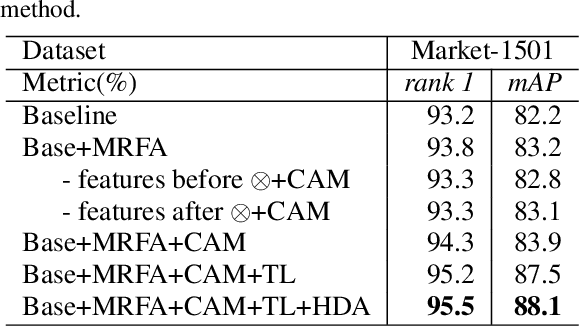
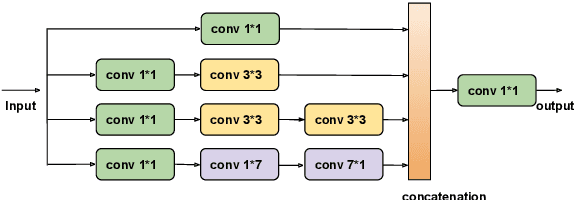
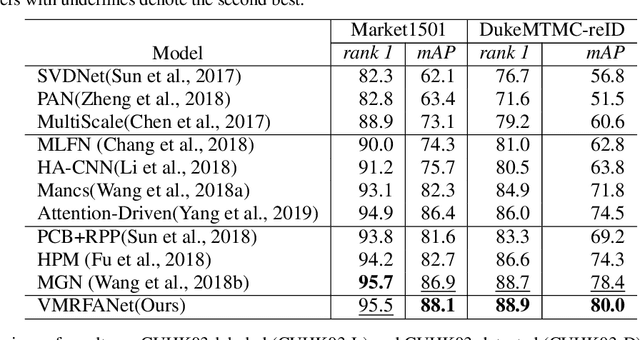
Person re-identification (re-ID) aims to retrieve the same person across different cameras. In practice, it still remains a challenging task due to background clutter, variations on body poses and view conditions, inaccurate bounding box detection, etc. To tackle these issues, in this paper, we propose a novel multi-receptive field attention (MRFA) module that utilizes filters of various sizes to help network focusing on informative pixels. Besides, we present a view-specific mechanism that guides attention module to handle the variation of view conditions. Moreover, we introduce a Gaussian horizontal random cropping/padding method which further improves the robustness of our proposed network. Comprehensive experiments demonstrate the effectiveness of each component. Our method achieves 95.5% / 88.1% in rank-1 / mAP on Market-1501, 88.9% / 80.0% on DukeMTMC-reID, 81.1% / 78.8% on CUHK03 labeled dataset and 78.9% / 75.3% on CUHK03 detected dataset, outperforming current state-of-the-art methods.
Multi-Scale Body-Part Mask Guided Attention for Person Re-identification
Apr 24, 2019
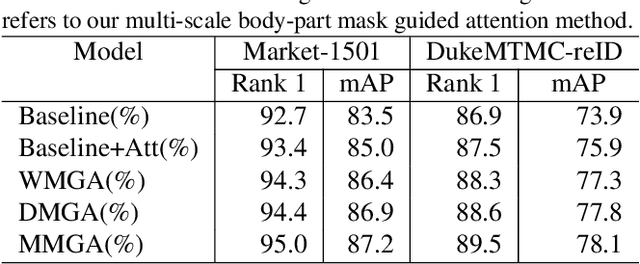

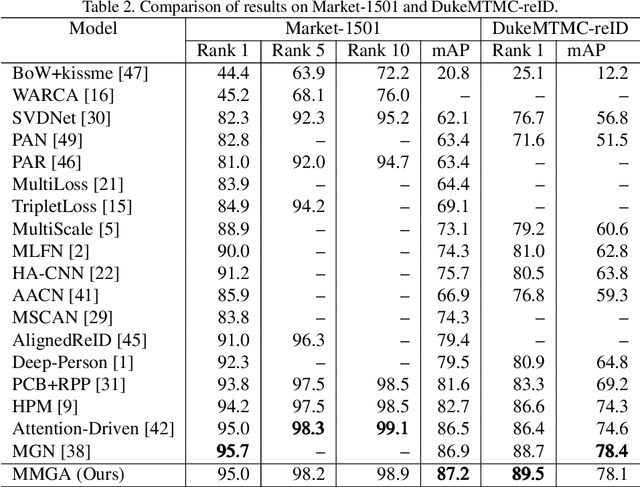
Person re-identification becomes a more and more important task due to its wide applications. In practice, person re-identification still remains challenging due to the variation of person pose, different lighting, occlusion, misalignment, background clutter, etc. In this paper, we propose a multi-scale body-part mask guided attention network (MMGA), which jointly learns whole-body and part body attention to help extract global and local features simultaneously. In MMGA, body-part masks are used to guide the training of corresponding attention. Experiments show that our proposed method can reduce the negative influence of variation of person pose, misalignment and background clutter. Our method achieves rank-1/mAP of 95.0%/87.2% on the Market1501 dataset, 89.5%/78.1% on the DukeMTMC-reID dataset, outperforming current state-of-the-art methods.