 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Optimization Method-Assisted Ensemble Deep Reinforcement Learning Algorithm to Solve Unit Commitment Problems
Jun 09, 2022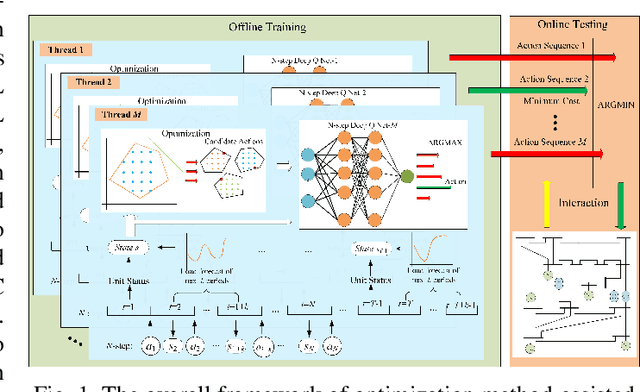
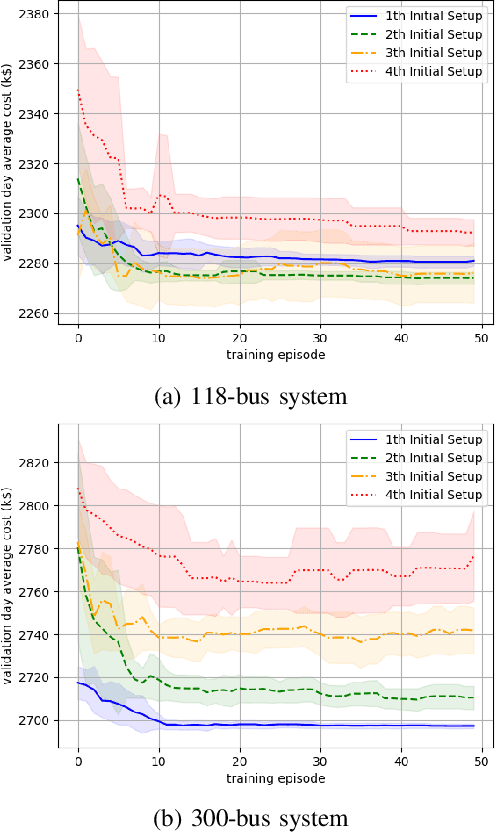
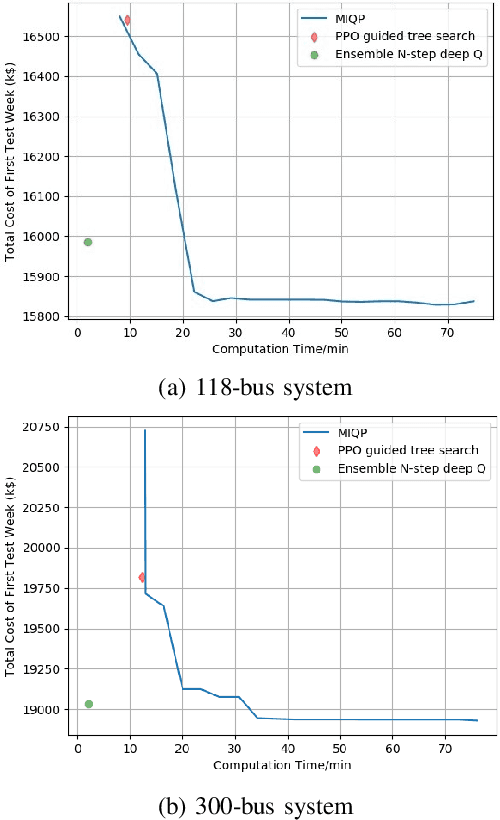
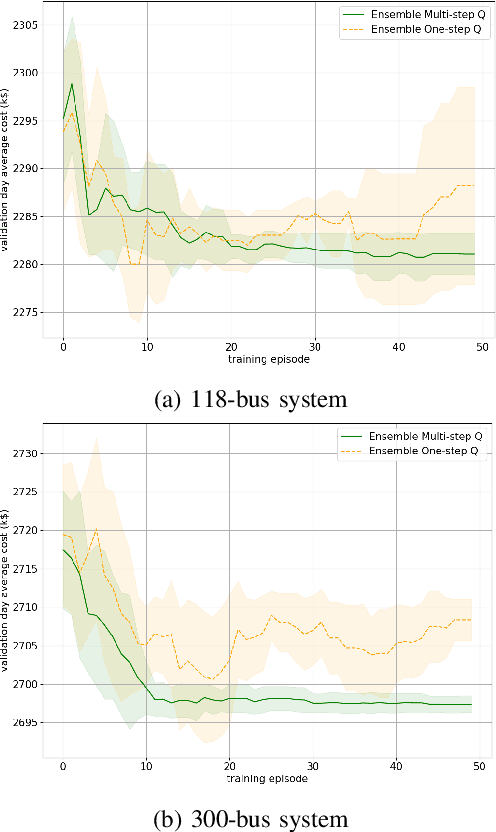
Unit commitment (UC) is a fundamental problem in the day-ahead electricity market, and it is critical to solve UC problems efficiently. Mathematical optimization techniques like dynamic programming, Lagrangian relaxation, and mixed-integer quadratic programming (MIQP) are commonly adopted for UC problems. However, the calculation time of these methods increases at an exponential rate with the amount of generators and energy resources, which is still the main bottleneck in industry. Recent advances in artificial intelligence have demonstrated the capability of reinforcement learning (RL) to solve UC problems. Unfortunately, the existing research on solving UC problems with RL suffers from the curse of dimensionality when the size of UC problems grows. To deal with these problems, we propose an optimization method-assisted ensemble deep reinforcement learning algorithm, where UC problems are formulated as a Markov Decision Process (MDP) and solved by multi-step deep Q-learning in an ensemble framework. The proposed algorithm establishes a candidate action set by solving tailored optimization problems to ensure a relatively high performance and the satisfaction of operational constraints. Numerical studies on IEEE 118 and 300-bus systems show that our algorithm outperforms the baseline RL algorithm and MIQP. Furthermore, the proposed algorithm shows strong generalization capacity under unforeseen operational conditions.
A Reinforcement Learning-based Volt-VAR Control Dataset and Testing Environment
Apr 20, 2022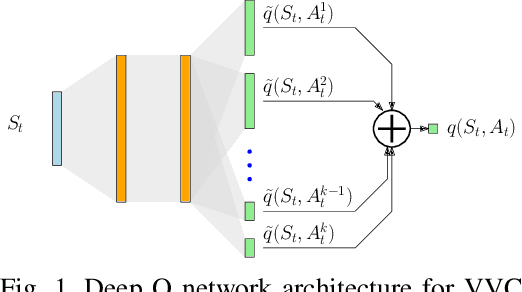
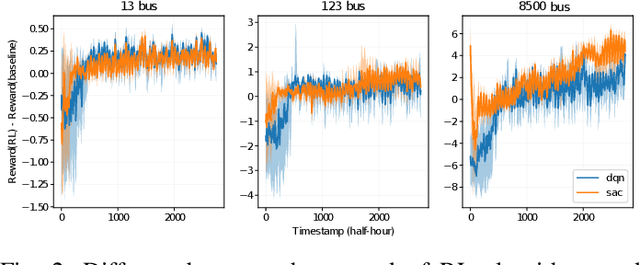
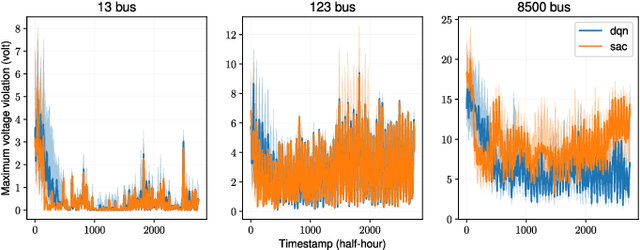

To facilitate the development of reinforcement learning (RL) based power distribution system Volt-VAR control (VVC), this paper introduces a suite of open-source datasets for RL-based VVC algorithm research that is sample efficient, safe, and robust. The dataset consists of two components: 1. a Gym-like VVC testing environment for the IEEE-13, 123, and 8500-bus test feeders and 2. a historical operational dataset for each of the feeders. Potential users of the dataset and testing environment could first train an sample-efficient off-line (batch) RL algorithm on the historical dataset and then evaluate the performance of the trained RL agent on the testing environments. This dataset serves as a useful testbed to conduct RL-based VVC research mimicking the real-world operational challenges faced by electric utilities. Meanwhile, it allows researchers to conduct fair performance comparisons between different algorithms.
Learning to Operate an Electric Vehicle Charging Station Considering Vehicle-grid Integration
Nov 01, 2021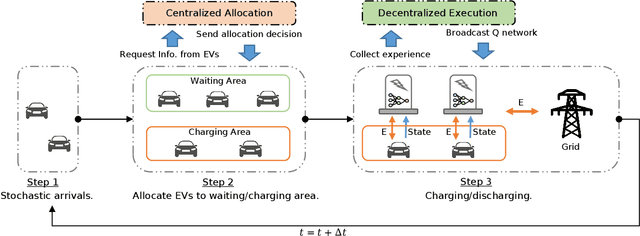
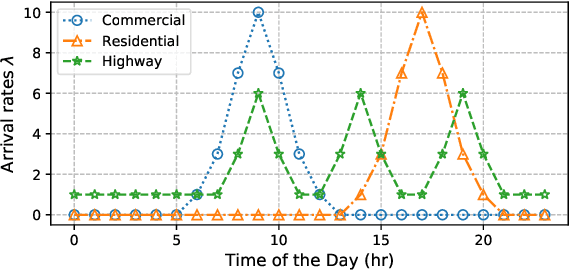
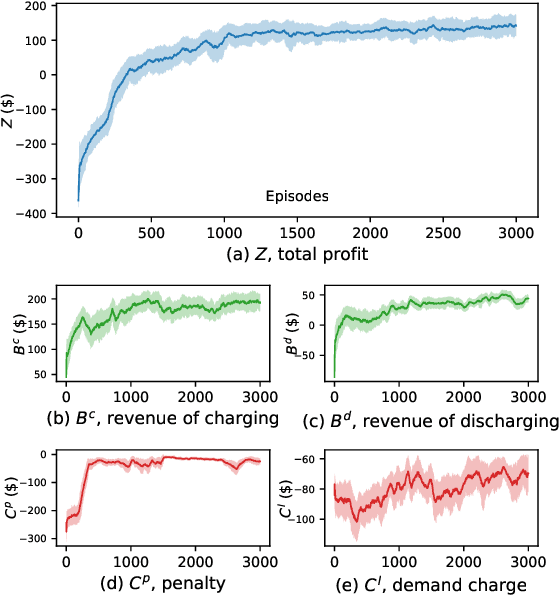
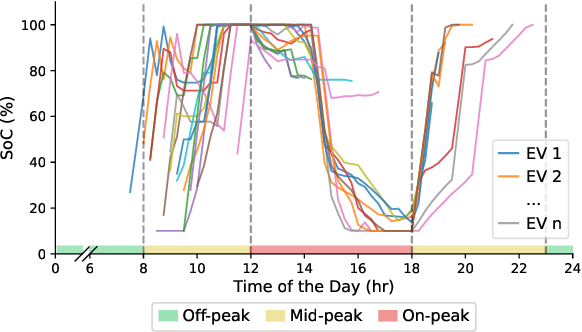
The rapid adoption of electric vehicles (EVs) calls for the widespread installation of EV charging stations. To maximize the profitability of charging stations, intelligent controllers that provide both charging and electric grid services are in great need. However, it is challenging to determine the optimal charging schedule due to the uncertain arrival time and charging demands of EVs. In this paper, we propose a novel centralized allocation and decentralized execution (CADE) reinforcement learning (RL) framework to maximize the charging station's profit. In the centralized allocation process, EVs are allocated to either the waiting or charging spots. In the decentralized execution process, each charger makes its own charging/discharging decision while learning the action-value functions from a shared replay memory. This CADE framework significantly improves the scalability and sample efficiency of the RL algorithm. Numerical results show that the proposed CADE framework is both computationally efficient and scalable, and significantly outperforms the baseline model predictive control (MPC). We also provide an in-depth analysis of the learned action-value function to explain the inner working of the reinforcement learning agent.
Consensus Multi-Agent Reinforcement Learning for Volt-VAR Control in Power Distribution Networks
Jul 06, 2020

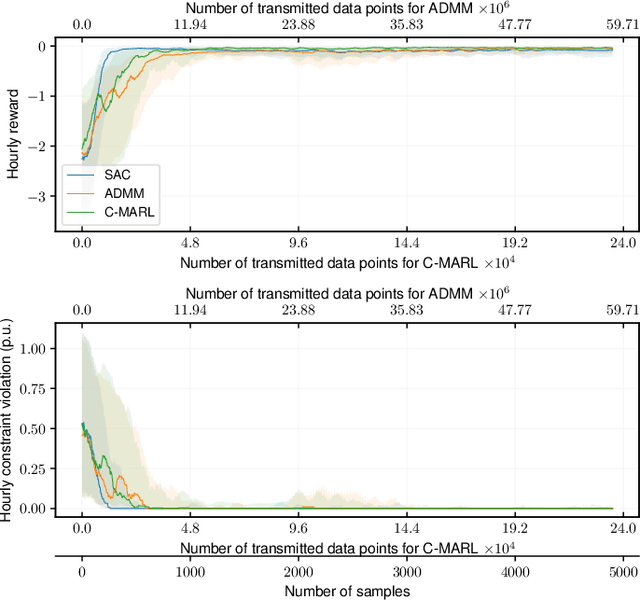
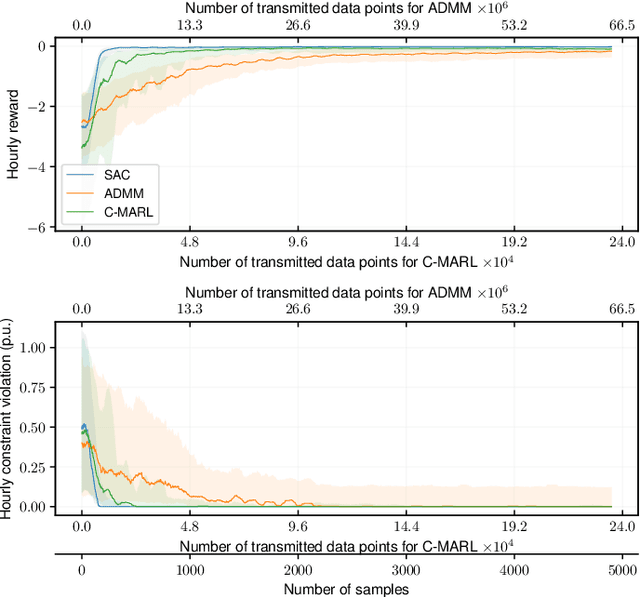
Volt-VAR control (VVC) is a critical application in active distribution network management system to reduce network losses and improve voltage profile. To remove dependency on inaccurate and incomplete network models and enhance resiliency against communication or controller failure, we propose consensus multi-agent deep reinforcement learning algorithm to solve the VVC problem. The VVC problem is formulated as a networked multi-agent Markov decision process, which is solved using the maximum entropy reinforcement learning framework and a novel communication-efficient consensus strategy. The proposed algorithm allows individual agents to learn a group control policy using local rewards. Numerical studies on IEEE distribution test feeders show that our proposed algorithm matches the performance of single-agent reinforcement learning benchmark. In addition, the proposed algorithm is shown to be communication efficient and resilient.
Asymptotic Finite Sample Information Losses in Neural Classifiers
Feb 15, 2019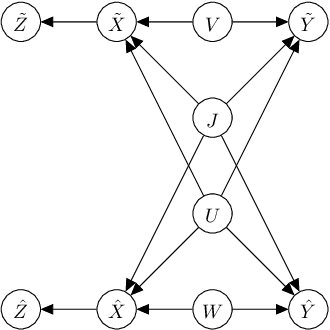
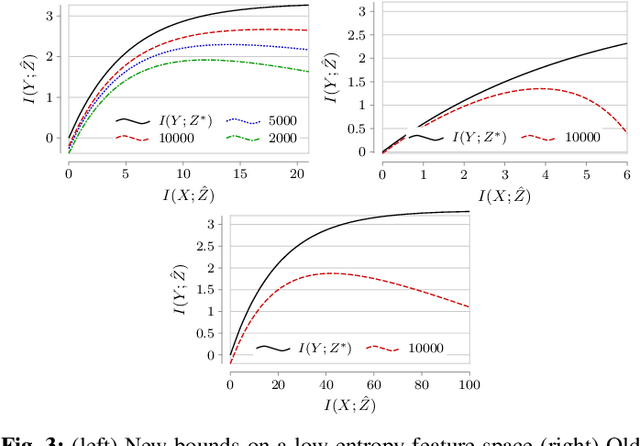
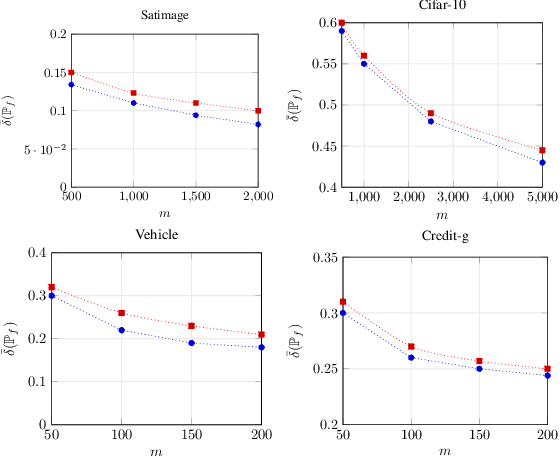
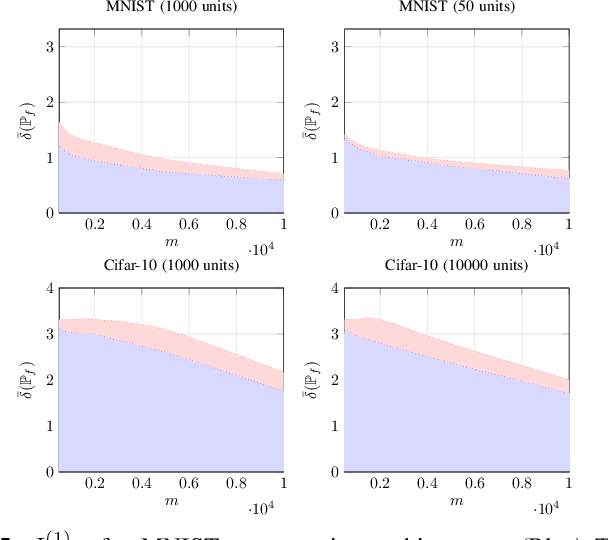
This paper considers the subject of information losses arising from finite datasets used in the training of neural classifiers. It proves a relationship between such losses and the product of the expected total variation of the estimated neural model with the information about the feature space contained in the hidden representation of that model. It then shows that this total variation drops extremely quickly with sample size. It ultimately obtains bounds on information losses that are less sensitive to input compression and much tighter than existing bounds. This brings about a tighter relevance of information theory to the training of neural networks, so a review of techniques for information estimation and control is provided. The paper then explains some potential uses of these bounds in the field of active learning, and then uses them to explain some recent experimental findings of information compression in neural networks which cannot be explained by previous work. It then uses the bounds to justify an information regularization term in the training of neural networks for low entropy feature space problems. Finally, the paper shows that, not only are these bounds much tighter than existing ones, but that these bounds correspond with experiments as well.