 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMaximum-Entropy Adversarial Audio Augmentation for Keyword Spotting
Jan 12, 2024Data augmentation is a key tool for improving the performance of deep networks, particularly when there is limited labeled data. In some fields, such as computer vision, augmentation methods have been extensively studied; however, for speech and audio data, there are relatively fewer methods developed. Using adversarial learning as a starting point, we develop a simple and effective augmentation strategy based on taking the gradient of the entropy of the outputs with respect to the inputs and then creating new data points by moving in the direction of the gradient to maximize the entropy. We validate its efficacy on several keyword spotting tasks as well as standard audio benchmarks. Our method is straightforward to implement, offering greater computational efficiency than more complex adversarial schemes like GANs. Despite its simplicity, it proves robust and effective, especially when combined with the established SpecAugment technique, leading to enhanced performance.
Learning to Operate an Electric Vehicle Charging Station Considering Vehicle-grid Integration
Nov 01, 2021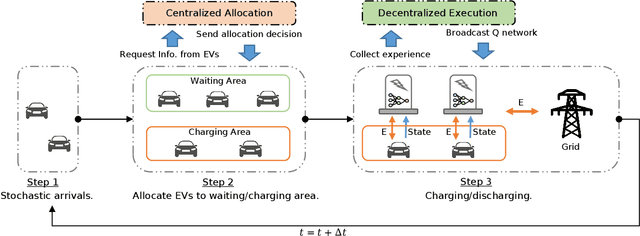
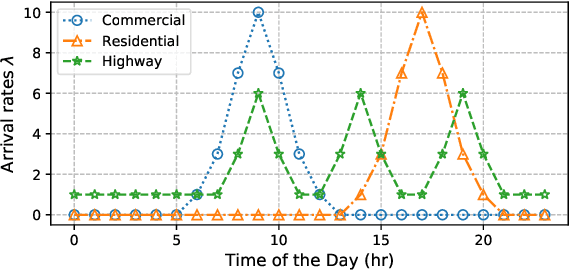
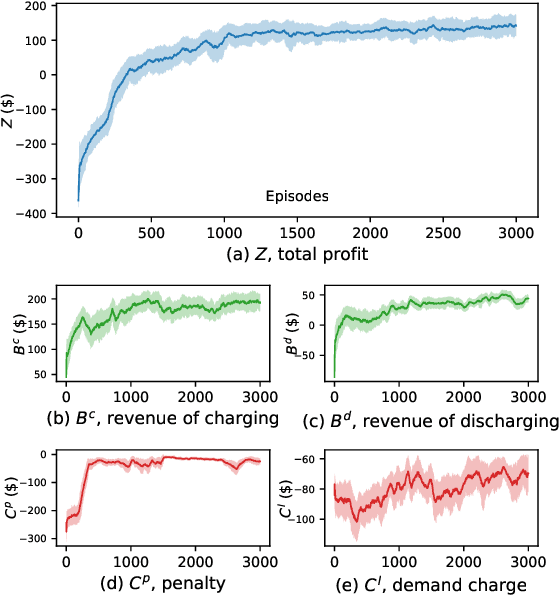
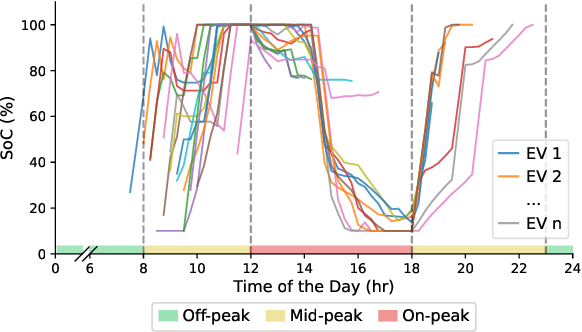
The rapid adoption of electric vehicles (EVs) calls for the widespread installation of EV charging stations. To maximize the profitability of charging stations, intelligent controllers that provide both charging and electric grid services are in great need. However, it is challenging to determine the optimal charging schedule due to the uncertain arrival time and charging demands of EVs. In this paper, we propose a novel centralized allocation and decentralized execution (CADE) reinforcement learning (RL) framework to maximize the charging station's profit. In the centralized allocation process, EVs are allocated to either the waiting or charging spots. In the decentralized execution process, each charger makes its own charging/discharging decision while learning the action-value functions from a shared replay memory. This CADE framework significantly improves the scalability and sample efficiency of the RL algorithm. Numerical results show that the proposed CADE framework is both computationally efficient and scalable, and significantly outperforms the baseline model predictive control (MPC). We also provide an in-depth analysis of the learned action-value function to explain the inner working of the reinforcement learning agent.