 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSSNAPS: Audio-Visual Separation of Speech and Background Noise with Diffusion Inverse Sampling
Feb 01, 2026This paper addresses the challenge of audio-visual single-microphone speech separation and enhancement in the presence of real-world environmental noise. Our approach is based on generative inverse sampling, where we model clean speech and ambient noise with dedicated diffusion priors and jointly leverage them to recover all underlying sources. To achieve this, we reformulate a recent inverse sampler to match our setting. We evaluate on mixtures of 1, 2, and 3 speakers with noise and show that, despite being entirely unsupervised, our method consistently outperforms leading supervised baselines in \ac{WER} across all conditions. We further extend our framework to handle off-screen speaker separation. Moreover, the high fidelity of the separated noise component makes it suitable for downstream acoustic scene detection. Demo page: https://ssnapsicml.github.io/ssnapsicml2026/
LipVoicer: Generating Speech from Silent Videos Guided by Lip Reading
Jun 05, 2023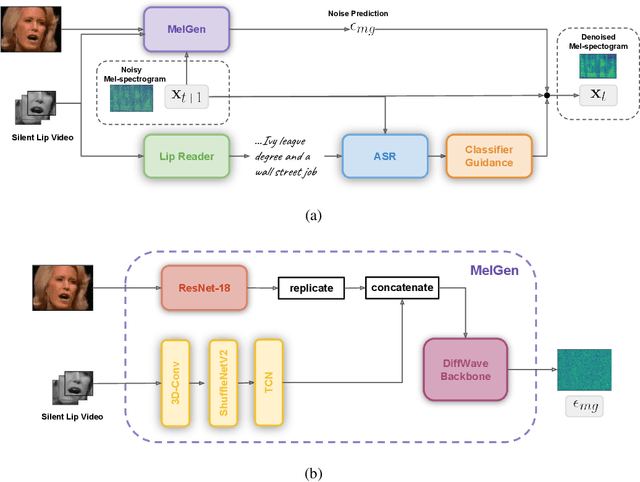
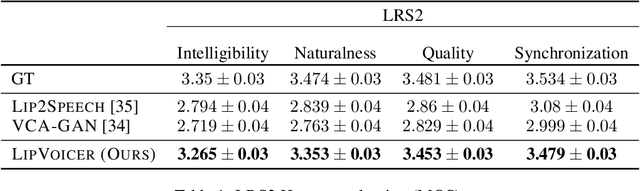
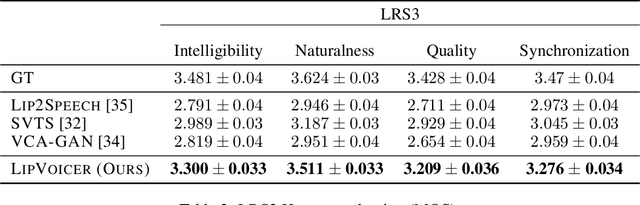
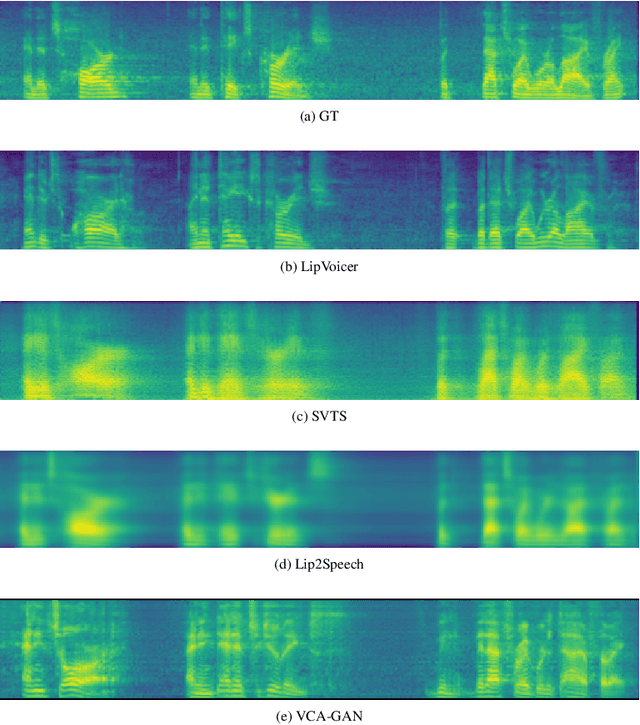
Lip-to-speech involves generating a natural-sounding speech synchronized with a soundless video of a person talking. Despite recent advances, current methods still cannot produce high-quality speech with high levels of intelligibility for challenging and realistic datasets such as LRS3. In this work, we present LipVoicer, a novel method that generates high-quality speech, even for in-the-wild and rich datasets, by incorporating the text modality. Given a silent video, we first predict the spoken text using a pre-trained lip-reading network. We then condition a diffusion model on the video and use the extracted text through a classifier-guidance mechanism where a pre-trained ASR serves as the classifier. LipVoicer outperforms multiple lip-to-speech baselines on LRS2 and LRS3, which are in-the-wild datasets with hundreds of unique speakers in their test set and an unrestricted vocabulary. Moreover, our experiments show that the inclusion of the text modality plays a major role in the intelligibility of the produced speech, readily perceptible while listening, and is empirically reflected in the substantial reduction of the WER metric. We demonstrate the effectiveness of LipVoicer through human evaluation, which shows that it produces more natural and synchronized speech signals compared to competing methods. Finally, we created a demo showcasing LipVoicer's superiority in producing natural, synchronized, and intelligible speech, providing additional evidence of its effectiveness. Project page: https://lipvoicer.github.io
GP-Tree: A Gaussian Process Classifier for Few-Shot Incremental Learning
Feb 15, 2021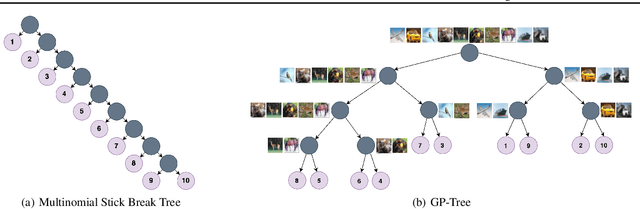
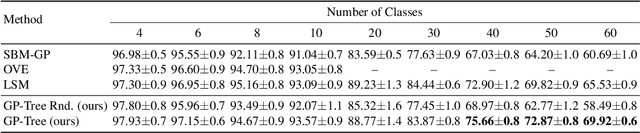
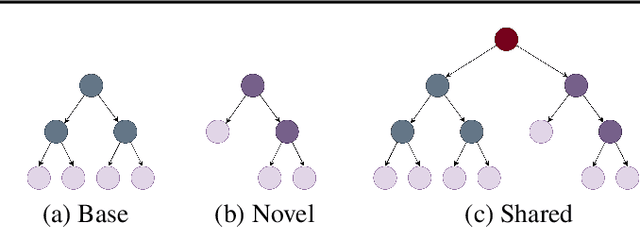

Gaussian processes (GPs) are non-parametric, flexible, models that work well in many tasks. Combining GPs with deep learning methods via deep kernel learning is especially compelling due to the strong expressive power induced by the network. However, inference in GPs, whether with or without deep kernel learning, can be computationally challenging on large datasets. Here, we propose GP-Tree, a novel method for multi-class classification with Gaussian processes and deep kernel learning. We develop a tree-based hierarchical model in which each internal node of the tree fits a GP to the data using the Polya-Gamma augmentation scheme. As a result, our method scales well with both the number of classes and data size. We demonstrate our method effectiveness against other Gaussian process training baselines, and we show how our general GP approach is easily applied to incremental few-shot learning and reaches state-of-the-art performance.
Position-Agnostic Multi-Microphone Speech Dereverberation
Oct 22, 2020

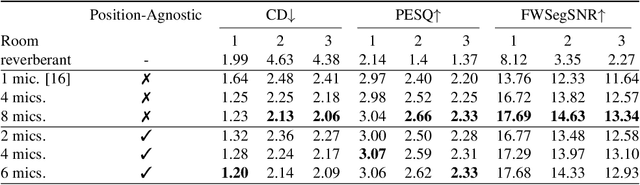
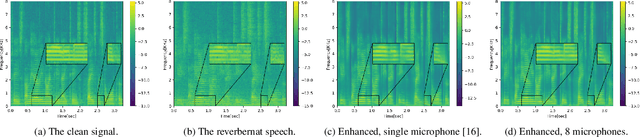
Neural networks (NNs) have been widely applied in speech processing tasks, and, in particular, those employing microphone arrays. Nevertheless, most of the existing NN architectures can only deal with fixed and position-specific microphone arrays. In this paper, we present an NN architecture that can cope with microphone arrays on which no prior knowledge is presumed, and demonstrate its applicability on the speech dereverberation problem. To this end, our approach harnesses recent advances in the Deep Sets framework to design an architecture that enhances the reverberant log-spectrum. We provide a setup for training and testing such a network. Our experiments, using REVERB challenge datasets, show that the proposed position-agnostic setup performs comparably with the position-aware framework and sometimes slightly better, even with fewer microphones. In addition, it substantially improves performance over a single microphone architecture.