 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGD-VDM: Generated Depth for better Diffusion-based Video Generation
Jun 19, 2023
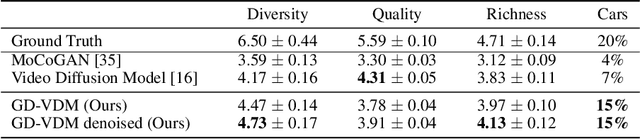
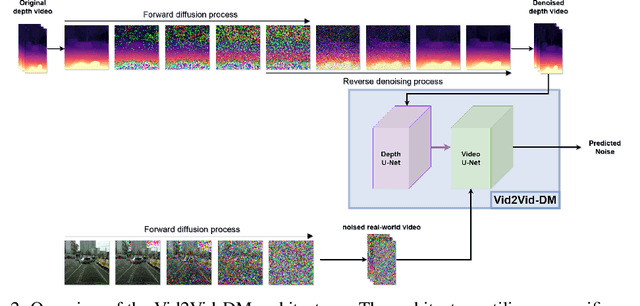

The field of generative models has recently witnessed significant progress, with diffusion models showing remarkable performance in image generation. In light of this success, there is a growing interest in exploring the application of diffusion models to other modalities. One such challenge is the generation of coherent videos of complex scenes, which poses several technical difficulties, such as capturing temporal dependencies and generating long, high-resolution videos. This paper proposes GD-VDM, a novel diffusion model for video generation, demonstrating promising results. GD-VDM is based on a two-phase generation process involving generating depth videos followed by a novel diffusion Vid2Vid model that generates a coherent real-world video. We evaluated GD-VDM on the Cityscapes dataset and found that it generates more diverse and complex scenes compared to natural baselines, demonstrating the efficacy of our approach.
LipVoicer: Generating Speech from Silent Videos Guided by Lip Reading
Jun 05, 2023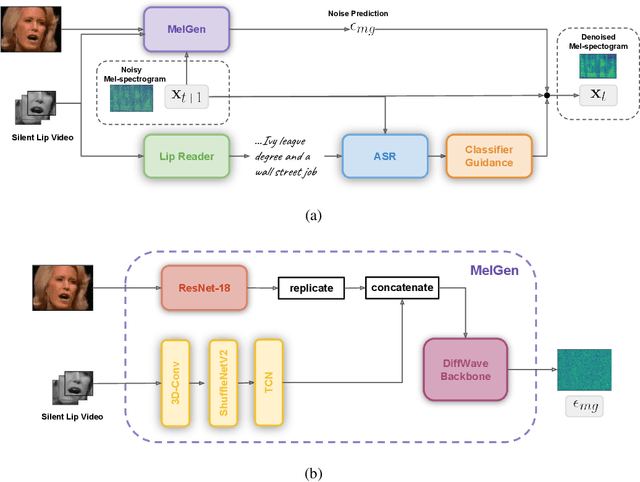
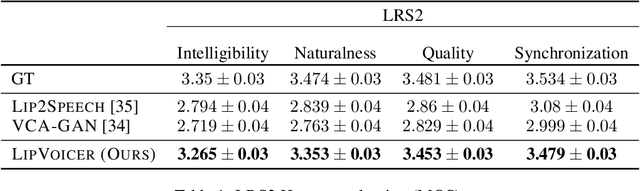
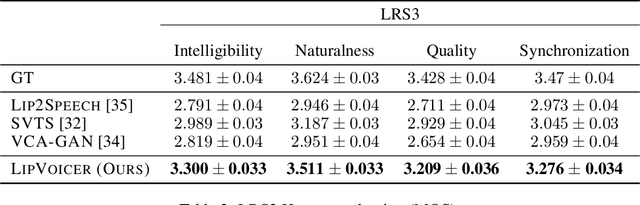
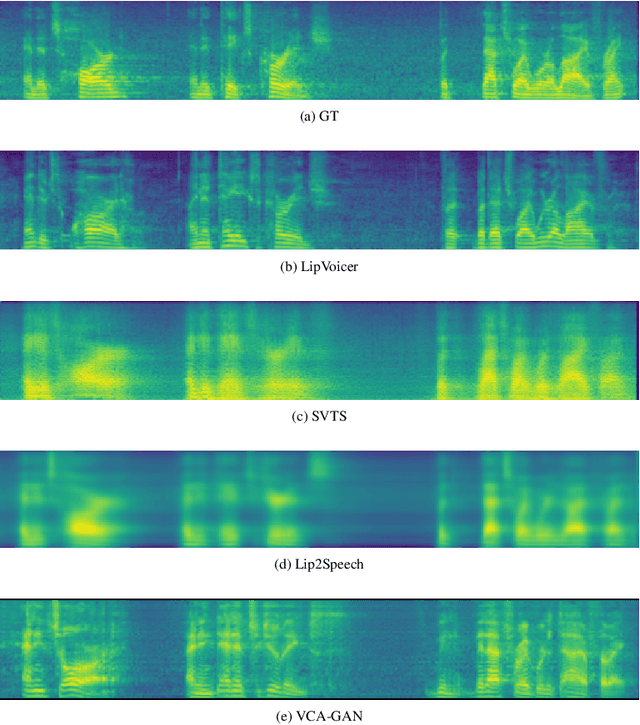
Lip-to-speech involves generating a natural-sounding speech synchronized with a soundless video of a person talking. Despite recent advances, current methods still cannot produce high-quality speech with high levels of intelligibility for challenging and realistic datasets such as LRS3. In this work, we present LipVoicer, a novel method that generates high-quality speech, even for in-the-wild and rich datasets, by incorporating the text modality. Given a silent video, we first predict the spoken text using a pre-trained lip-reading network. We then condition a diffusion model on the video and use the extracted text through a classifier-guidance mechanism where a pre-trained ASR serves as the classifier. LipVoicer outperforms multiple lip-to-speech baselines on LRS2 and LRS3, which are in-the-wild datasets with hundreds of unique speakers in their test set and an unrestricted vocabulary. Moreover, our experiments show that the inclusion of the text modality plays a major role in the intelligibility of the produced speech, readily perceptible while listening, and is empirically reflected in the substantial reduction of the WER metric. We demonstrate the effectiveness of LipVoicer through human evaluation, which shows that it produces more natural and synchronized speech signals compared to competing methods. Finally, we created a demo showcasing LipVoicer's superiority in producing natural, synchronized, and intelligible speech, providing additional evidence of its effectiveness. Project page: https://lipvoicer.github.io
DisCLIP: Open-Vocabulary Referring Expression Generation
May 30, 2023
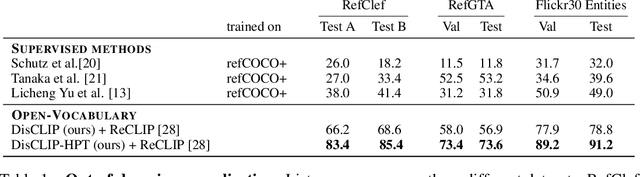
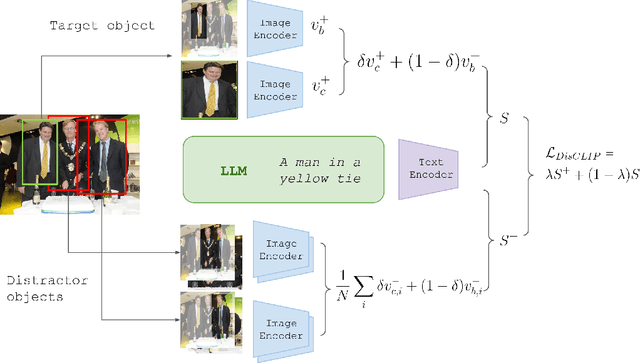
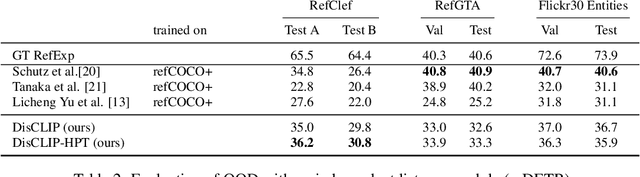
Referring Expressions Generation (REG) aims to produce textual descriptions that unambiguously identifies specific objects within a visual scene. Traditionally, this has been achieved through supervised learning methods, which perform well on specific data distributions but often struggle to generalize to new images and concepts. To address this issue, we present a novel approach for REG, named DisCLIP, short for discriminative CLIP. We build on CLIP, a large-scale visual-semantic model, to guide an LLM to generate a contextual description of a target concept in an image while avoiding other distracting concepts. Notably, this optimization happens at inference time and does not require additional training or tuning of learned parameters. We measure the quality of the generated text by evaluating the capability of a receiver model to accurately identify the described object within the scene. To achieve this, we use a frozen zero-shot comprehension module as a critique of our generated referring expressions. We evaluate DisCLIP on multiple referring expression benchmarks through human evaluation and show that it significantly outperforms previous methods on out-of-domain datasets. Our results highlight the potential of using pre-trained visual-semantic models for generating high-quality contextual descriptions.
Informative Object Annotations: Tell Me Something I Don't Know
Dec 26, 2018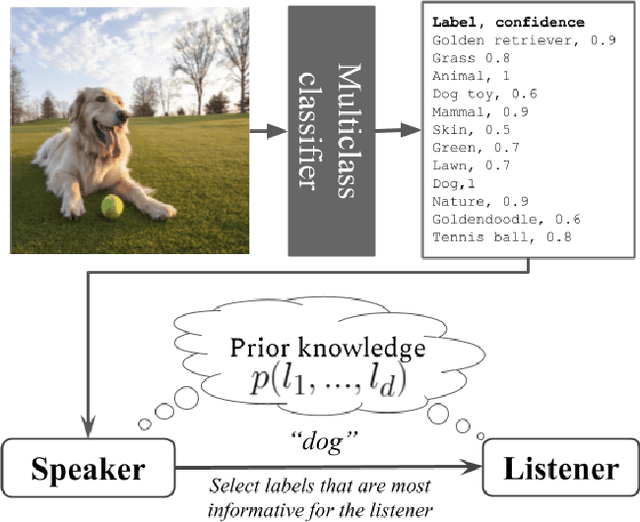
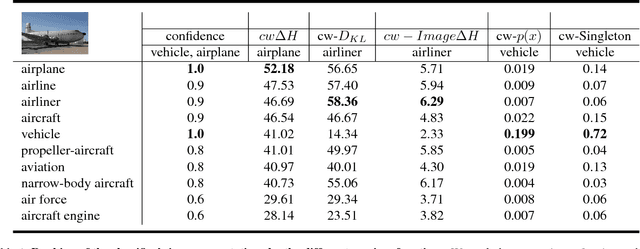
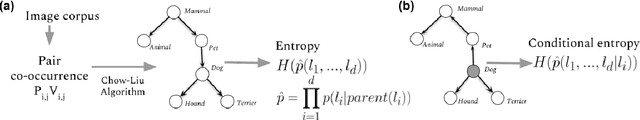
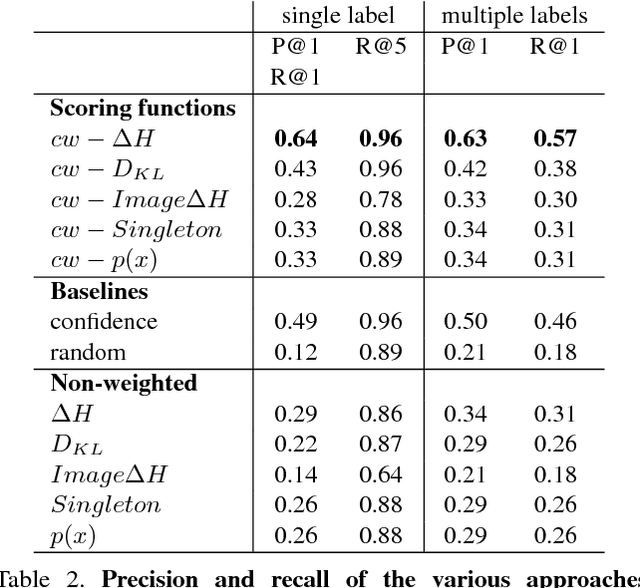
Capturing the interesting components of an image is a key aspect of image understanding. When a speaker annotates an image, selecting labels that are informative greatly depends on the prior knowledge of a prospective listener. Motivated by cognitive theories of categorization and communication, we present a new unsupervised approach to model this prior knowledge and quantify the informativeness of a description. Specifically, we compute how knowledge of a label reduces uncertainty over the space of labels and utilize this to rank candidate labels for describing an image. While the full estimation problem is intractable, we describe an efficient algorithm to approximate entropy reduction using a tree-structured graphical model. We evaluate our approach on the open-images dataset using a new evaluation set of 10K ground-truth ratings and find that it achieves ~65% agreement with human raters, largely outperforming other unsupervised baseline approaches.