 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGD-VDM: Generated Depth for better Diffusion-based Video Generation
Paper and Code

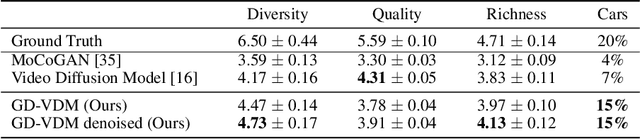
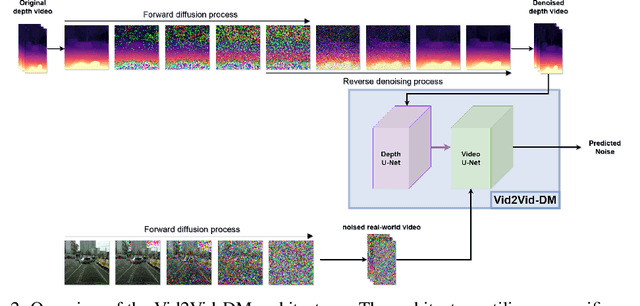

The field of generative models has recently witnessed significant progress, with diffusion models showing remarkable performance in image generation. In light of this success, there is a growing interest in exploring the application of diffusion models to other modalities. One such challenge is the generation of coherent videos of complex scenes, which poses several technical difficulties, such as capturing temporal dependencies and generating long, high-resolution videos. This paper proposes GD-VDM, a novel diffusion model for video generation, demonstrating promising results. GD-VDM is based on a two-phase generation process involving generating depth videos followed by a novel diffusion Vid2Vid model that generates a coherent real-world video. We evaluated GD-VDM on the Cityscapes dataset and found that it generates more diverse and complex scenes compared to natural baselines, demonstrating the efficacy of our approach.