 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLookahead Exploration with Neural Radiance Representation for Continuous Vision-Language Navigation
Apr 02, 2024
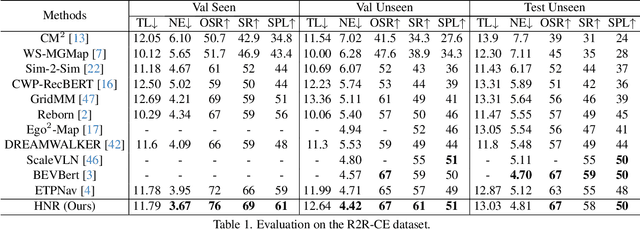


Vision-and-language navigation (VLN) enables the agent to navigate to a remote location following the natural language instruction in 3D environments. At each navigation step, the agent selects from possible candidate locations and then makes the move. For better navigation planning, the lookahead exploration strategy aims to effectively evaluate the agent's next action by accurately anticipating the future environment of candidate locations. To this end, some existing works predict RGB images for future environments, while this strategy suffers from image distortion and high computational cost. To address these issues, we propose the pre-trained hierarchical neural radiance representation model (HNR) to produce multi-level semantic features for future environments, which are more robust and efficient than pixel-wise RGB reconstruction. Furthermore, with the predicted future environmental representations, our lookahead VLN model is able to construct the navigable future path tree and select the optimal path via efficient parallel evaluation. Extensive experiments on the VLN-CE datasets confirm the effectiveness of our method.
GridMM: Grid Memory Map for Vision-and-Language Navigation
Jul 25, 2023



Vision-and-language navigation (VLN) enables the agent to navigate to a remote location following the natural language instruction in 3D environments. To represent the previously visited environment, most approaches for VLN implement memory using recurrent states, topological maps, or top-down semantic maps. In contrast to these approaches, we build the top-down egocentric and dynamically growing Grid Memory Map (i.e., GridMM) to structure the visited environment. From a global perspective, historical observations are projected into a unified grid map in a top-down view, which can better represent the spatial relations of the environment. From a local perspective, we further propose an instruction relevance aggregation method to capture fine-grained visual clues in each grid region. Extensive experiments are conducted on both the REVERIE, R2R, SOON datasets in the discrete environments, and the R2R-CE dataset in the continuous environments, showing the superiority of our proposed method.
DSTP-RNN: a dual-stage two-phase attention-based recurrent neural networks for long-term and multivariate time series prediction
Apr 16, 2019
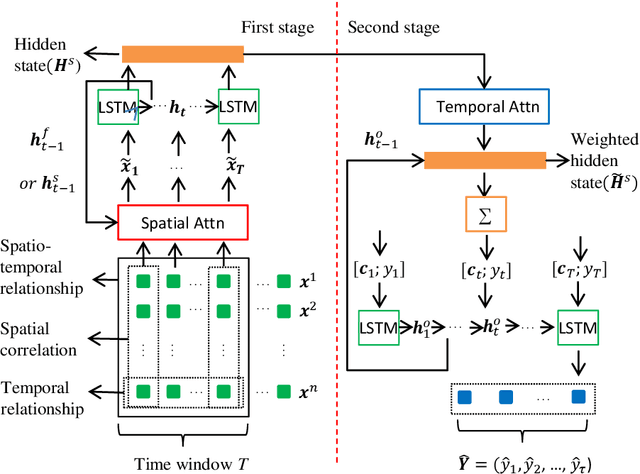
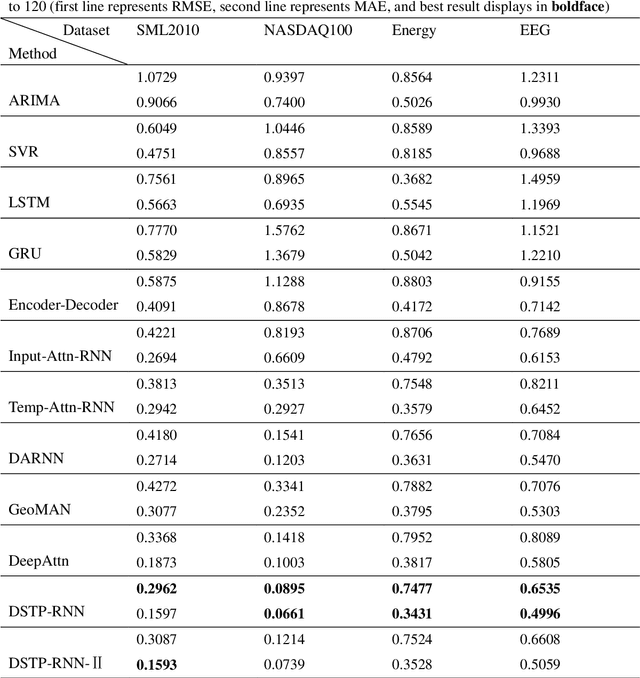
Long-term prediction of multivariate time series is still an important but challenging problem. The key to solve this problem is to capture the spatial correlations at the same time, the spatio-temporal relationships at different times and the long-term dependence of the temporal relationships between different series. Attention-based recurrent neural networks (RNN) can effectively represent the dynamic spatio-temporal relationships between exogenous series and target series, but it only performs well in one-step time prediction and short-term time prediction. In this paper, inspired by human attention mechanism including the dual-stage two-phase (DSTP) model and the influence mechanism of target information and non-target information, we propose DSTP-based RNN (DSTP-RNN) and DSTP-RNN-2 respectively for long-term time series prediction. Specifically, we first propose the DSTP-based structure to enhance the spatial correlations between exogenous series. The first phase produces violent but decentralized response weight, while the second phase leads to stationary and concentrated response weight. Secondly, we employ multiple attentions on target series to boost the long-term dependence. Finally, we study the performance of deep spatial attention mechanism and provide experiment and interpretation. Our methods outperform nine baseline methods on four datasets in the fields of energy, finance, environment and medicine, respectively.
Real time expert system for anomaly detection of aerators based on computer vision technology and existing surveillance cameras
Oct 17, 2018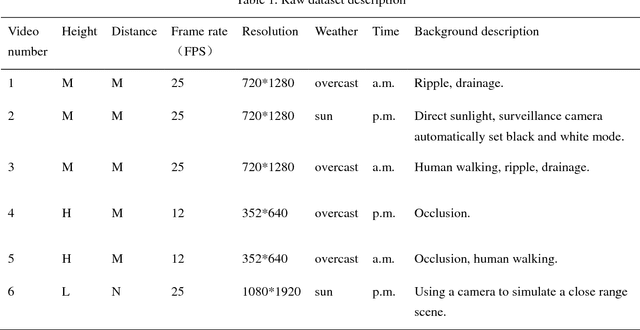

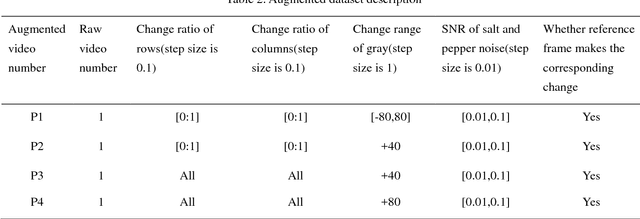
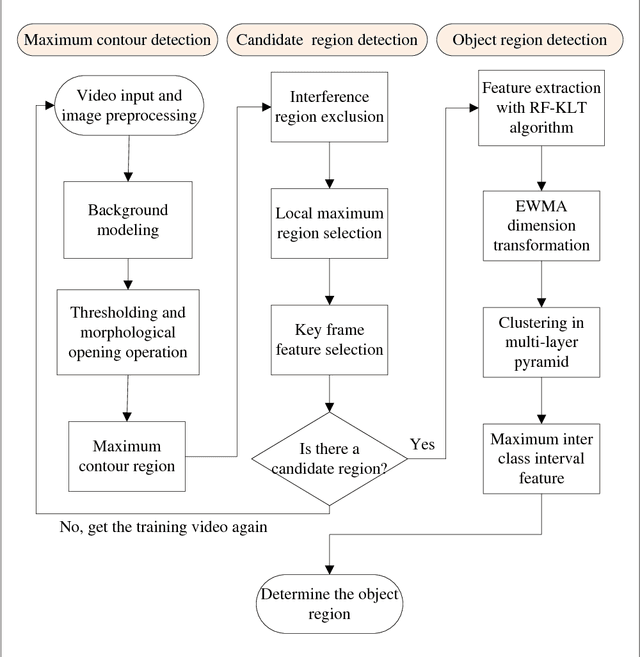
Aerators are essential and crucial auxiliary devices in intensive culture, especially in industrial culture in China. The traditional methods cannot accurately detect abnormal condition of aerators in time. Surveillance cameras are widely used as visual perception modules of the Internet of Things, and then using these widely existing surveillance cameras to realize real-time anomaly detection of aerators is a cost-free and easy-to-promote method. However, it is difficult to develop such an expert system due to some technical and applied challenges, e.g., illumination, occlusion, complex background, etc. To tackle these aforementioned challenges, we propose a real-time expert system based on computer vision technology and existing surveillance cameras for anomaly detection of aerators, which consists of two modules, i.e., object region detection and working state detection. First, it is difficult to detect the working state for some small object regions in whole images, and the time complexity of global feature comparison is also high, so we present an object region detection method based on the region proposal idea. Moreover, we propose a novel algorithm called reference frame Kanade-Lucas-Tomasi (RF-KLT) algorithm for motion feature extraction in fixed regions. Then, we present a dimension reduction method of time series for establishing a feature dataset with obvious boundaries between classes. Finally, we use machine learning algorithms to build the feature classifier. The experimental results in both the actual video dataset and the augmented video dataset show that the accuracy for detecting object region and working state of aerators is 100% and 99.9% respectively, and the detection speed is 77-333 frames per second (FPS) according to the different types of surveillance cameras.