 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnalyzing Adversarial Robustness of Deep Neural Networks in Pixel Space: a Semantic Perspective
Jun 18, 2021

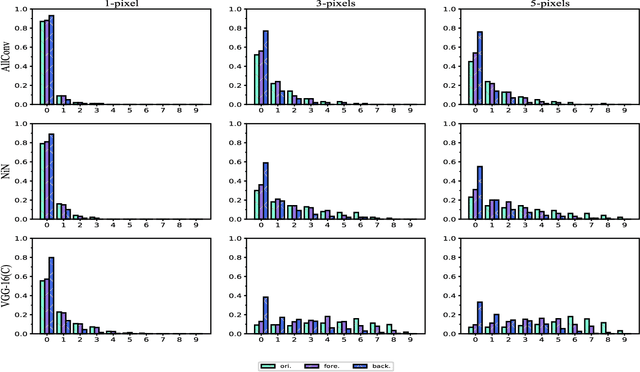

The vulnerability of deep neural networks to adversarial examples, which are crafted maliciously by modifying the inputs with imperceptible perturbations to misled the network produce incorrect outputs, reveals the lack of robustness and poses security concerns. Previous works study the adversarial robustness of image classifiers on image level and use all the pixel information in an image indiscriminately, lacking of exploration of regions with different semantic meanings in the pixel space of an image. In this work, we fill this gap and explore the pixel space of the adversarial image by proposing an algorithm to looking for possible perturbations pixel by pixel in different regions of the segmented image. The extensive experimental results on CIFAR-10 and ImageNet verify that searching for the modified pixel in only some pixels of an image can successfully launch the one-pixel adversarial attacks without requiring all the pixels of the entire image, and there exist multiple vulnerable points scattered in different regions of an image. We also demonstrate that the adversarial robustness of different regions on the image varies with the amount of semantic information contained.
Improving adversarial robustness of deep neural networks by using semantic information
Aug 18, 2020
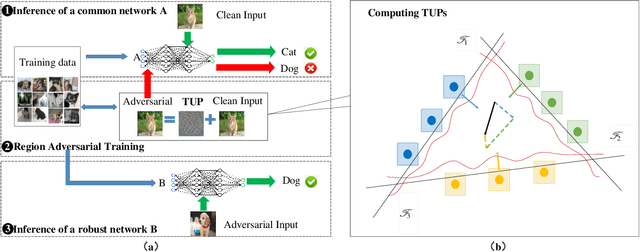

The vulnerability of deep neural networks (DNNs) to adversarial attack, which is an attack that can mislead state-of-the-art classifiers into making an incorrect classification with high confidence by deliberately perturbing the original inputs, raises concerns about the robustness of DNNs to such attacks. Adversarial training, which is the main heuristic method for improving adversarial robustness and the first line of defense against adversarial attacks, requires many sample-by-sample calculations to increase training size and is usually insufficiently strong for an entire network. This paper provides a new perspective on the issue of adversarial robustness, one that shifts the focus from the network as a whole to the critical part of the region close to the decision boundary corresponding to a given class. From this perspective, we propose a method to generate a single but image-agnostic adversarial perturbation that carries the semantic information implying the directions to the fragile parts on the decision boundary and causes inputs to be misclassified as a specified target. We call the adversarial training based on such perturbations "region adversarial training" (RAT), which resembles classical adversarial training but is distinguished in that it reinforces the semantic information missing in the relevant regions. Experimental results on the MNIST and CIFAR-10 datasets show that this approach greatly improves adversarial robustness even using a very small dataset from the training data; moreover, it can defend against FGSM adversarial attacks that have a completely different pattern from the model seen during retraining.