 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSystematic Testing of the Data-Poisoning Robustness of KNN
Jul 17, 2023Data poisoning aims to compromise a machine learning based software component by contaminating its training set to change its prediction results for test inputs. Existing methods for deciding data-poisoning robustness have either poor accuracy or long running time and, more importantly, they can only certify some of the truly-robust cases, but remain inconclusive when certification fails. In other words, they cannot falsify the truly-non-robust cases. To overcome this limitation, we propose a systematic testing based method, which can falsify as well as certify data-poisoning robustness for a widely used supervised-learning technique named k-nearest neighbors (KNN). Our method is faster and more accurate than the baseline enumeration method, due to a novel over-approximate analysis in the abstract domain, to quickly narrow down the search space, and systematic testing in the concrete domain, to find the actual violations. We have evaluated our method on a set of supervised-learning datasets. Our results show that the method significantly outperforms state-of-the-art techniques, and can decide data-poisoning robustness of KNN prediction results for most of the test inputs.
Certifying the Fairness of KNN in the Presence of Dataset Bias
Jul 17, 2023We propose a method for certifying the fairness of the classification result of a widely used supervised learning algorithm, the k-nearest neighbors (KNN), under the assumption that the training data may have historical bias caused by systematic mislabeling of samples from a protected minority group. To the best of our knowledge, this is the first certification method for KNN based on three variants of the fairness definition: individual fairness, $\epsilon$-fairness, and label-flipping fairness. We first define the fairness certification problem for KNN and then propose sound approximations of the complex arithmetic computations used in the state-of-the-art KNN algorithm. This is meant to lift the computation results from the concrete domain to an abstract domain, to reduce the computational cost. We show effectiveness of this abstract interpretation based technique through experimental evaluation on six datasets widely used in the fairness research literature. We also show that the method is accurate enough to obtain fairness certifications for a large number of test inputs, despite the presence of historical bias in the datasets.
Single Reference Image based Scene Relighting via Material Guided Filtering
Aug 23, 2017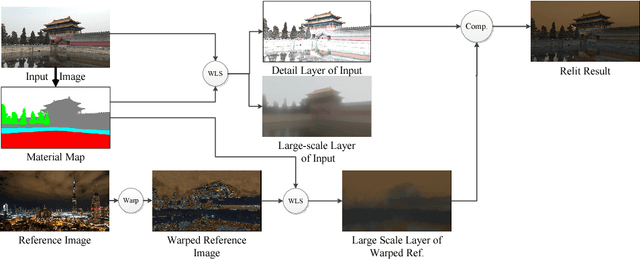
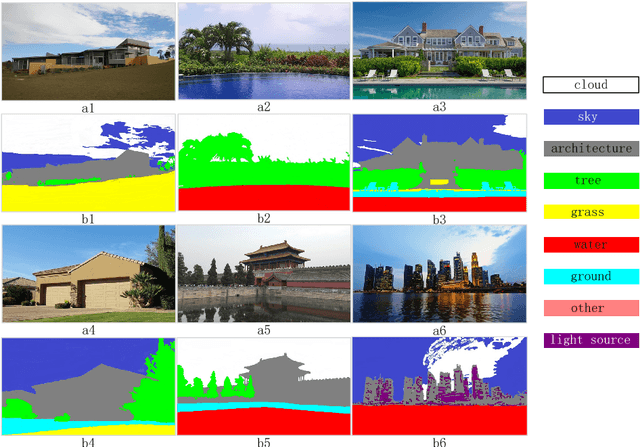


Image relighting is to change the illumination of an image to a target illumination effect without known the original scene geometry, material information and illumination condition. We propose a novel outdoor scene relighting method, which needs only a single reference image and is based on material constrained layer decomposition. Firstly, the material map is extracted from the input image. Then, the reference image is warped to the input image through patch match based image warping. Lastly, the input image is relit using material constrained layer decomposition. The experimental results reveal that our method can produce similar illumination effect as that of the reference image on the input image using only a single reference image.